本日業務で、「DynamoDB全件なめてこの条件のデータだけ頂戴」に遭遇しました。
最新のSDK等を利用すれば多分もっと簡単にできるのでしょうが、
色々な制約があった中で頑張ったメモなので、残しておきます。
Tips
- Data PipelineでS3に取っているバックアップファイルを、Bashのコマンドラインで操作して抽出
- DynamoDBのバックアップファイルは以下のフォーマットで生成されている
カラム名 0x03 カラム値 0x02 ...(繰り返し)... 0x0a
例えば以下のデータの場合
id (n) 123
age (n) 16
name (string) "abc"
id<0x03>{"n":"123"}<0x02>age<0x03>{"n":"16"}<0x02>name<0x03>{"s":"abc"}<0x0a>
この方法を採れた理由
- 日次でData Pipelineを利用してDynamoDBのExportを行っていた
- データが今いまの最新である必要はなく、前日のもので良かった
- 取得するデータが固定長だった
具体的な手順
- AWS Consoleから、S3へ移動し、backupのファイルを全部ローカルvagrantのsynced_folderに格納
- 今回は6ファイルありました。仮にファイル名を "file-xxxxx-000001" からの連番とします
- ageが16のデータのidだけを抜く (IDは3桁固定)
$ pwd
<synced_folder>
$ grep $'\x61\x67\x65\x03\x7B\x22\x6E\x22\x3A\x22\x31\x36\x22\x7D' <synced_folder>/file-xxxxx-* > result01.txt
$ cat result01.txt | sed -e 's/\x03//g' > result02.txt
$ cat result02.txt | awk -F'age' '{ print $2 }' > result03.txt
$ cut -c9-11 result03.txt > result04.txt
age<0x03>{"n":"16"} は、61 67 65 03 7B 22 6E 22 3A 22 31 36 22 7D
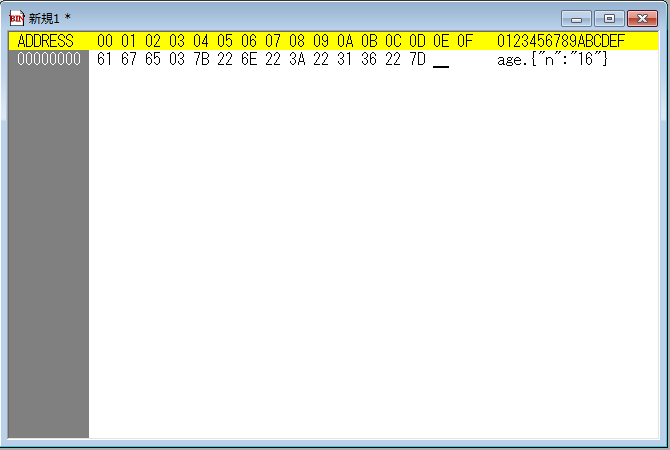
今回はこの手順でresult04.txtを提出しました。
改善できたなと思ってるポイント
- 今回無理やりバリナリ文字列でgrepしたものの、先にsedを掛けておけばもう少し視認性の高いgrepができた
- 急いでるときあるある
次やるならこうしそう
$ pwd
<synced_folder>
$ cat <synced_folder>/file-xxxxx-* | sed -e 's/\x03//g' > result01.txt
$ grep 'age{"n":"16"}' result01.txt > result02.txt
$ cat result02.txt | awk -F'age' '{ print $2 }' > result03.txt
$ cut -c9-11 result03.txt > result04.txt
おしまい。