何をするか
ベイズ統計を用いた二項分布B(n,p)のnの推定をRを使ってします。
二項分布 B(n,p) 推定の歴史
二項分布B(n,p)では歴史上、pに興味がある場合が多かった。一方パラメータnに興味があるケースは稀であり、あまり研究は進んでいない。さらに、推定量の構成が難しく、漸近正規性をもたない場合がある。
頻度論的アプローチでは近年DasGupta and Rubin(2005)「Estimation of binomial parameters when both n, p are unknown」において順序統計量と期待値などを組み合わせて、安定性の高い推定量の構築と漸近分布の導出を行っている。
ベイズ統計学を用いたアプローチも存在しRaftery(1988)「Inference for the binomial N parameter: A hierarchical Bayes approach. 」でベイズ統計を用いた推定量の構築と事後分布の構成を行っている。
本ページではベイズ統計を用いた手法のコードを書く。
コード
#nの信頼区間構成、通常
nn.def<-1000
pp.def<-0.5
NN.def<-10
nn.max.def<-nn.def*3
a.error<-0.05
#観測の生成、平均、分散、最大値
mm.obs<-rbinom(NN.def,nn.def,pp.def)
plot(mm.obs)
mean(mm.obs);var(mm.obs)
mm.sum<-sum(mm.obs)
mm.max<-max(mm.obs)
#nnのサポート生成
nn.min<-mm.max
nn.max<-nn.max.def
nn.vec<-nn.min:nn.max
#事後分布
##choose
lchoose.vec<-rep(0,length(nn.vec))
for(ii in 1:NN.def){
lchoose.vec<-lchoose.vec+lchoose(nn.vec,mm.obs[ii])
}
##beta
lbeta.vec<-lbeta(mm.sum,NN.def*nn.vec-mm.sum)
#propto
L.nn.propto<-lchoose.vec+lbeta.vec
plot(exp(L.nn.propto))
##確率に書き直す
gg<-exp(L.nn.propto-max(L.nn.propto))
nn.posterior<-gg/sum(gg)
nn.posterior.cumsum<-cumsum(nn.posterior)
nn.interval.min<-max(which(nn.posterior.cumsum<(a.error/2)))+mm.max
nn.interval.max<-min(which(nn.posterior.cumsum>(1-a.error/2)))+mm.max
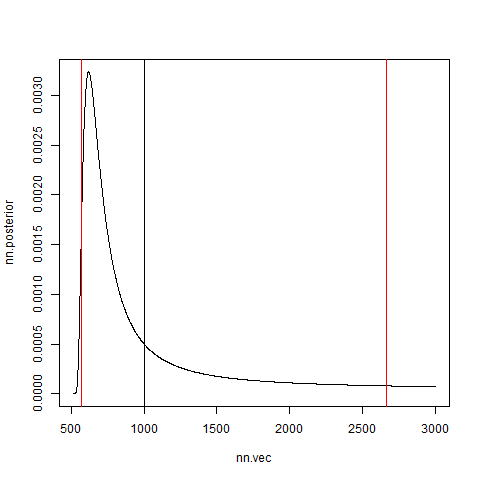
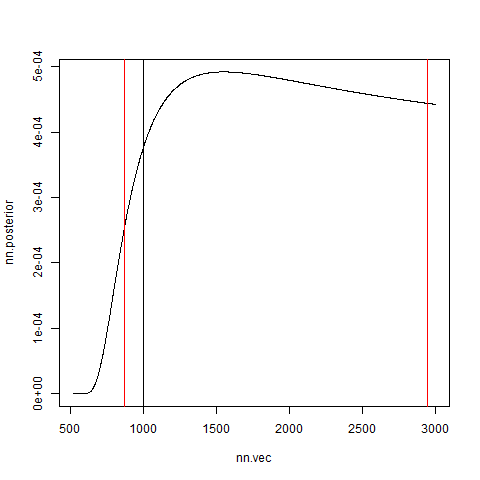
plot(nn.vec,nn.posterior,type="l")
abline(v=nn.def)
abline(v=nn.interval.min,col=2)
abline(v=nn.interval.max,col=2)
出力結果
黒線が真のn,赤線が両側95%信用区間です。それっぽく見えますが、裾が非常に重たく、サンプル数が多くないとうまくいきません。
画像1は裾がはやめに落ちてますが、画像2は裾が重たく、信頼区間の計算にも失敗しています。
結論
B(n,p)から十分多くの観測があれば推定が安定するが、少ないときわめて不安定という問題は結構ついて回ります。
する機会はあまりないと思いますが、かなり注意して扱う必要があります。