Chainer Advent Calendar 2016 の15日目の記事です(すみません遅刻しました…)。
本記事は、「Chainer のサンプルを動かして学習はできるけど、オリジナルのデータセットを学習させて、さらにそのモデルを Web API サーバのような実用的な形にするにはどうすれば良いのか?」と思っているような方向けの記事になります(比較的初心者が対象になるかと思います)。
ここでは、Chainer 公式の GitHub リポジトリにあるサンプルコード imagenet をベースに、画像分類を行う API サーバの作成を最終目標とします。
前提
本記事では、次の環境で開発を行いました。
- Python 3.5
- Chainer 1.19.0
- Flask 0.11.1
- OpenCV 3.1.0
画像を収集する
データ収集がしんどかったので、 簡単化のために「犬、猫、うさぎ」の3種類の動物を分類するニューラルネットを構築してみます。
まずは画像を集めることから始まります。今回は下記サイトから動物の画像を集めました。
収集した画像は original フォルダの中に、スクリーンショットの通りの構成で格納します(実際にはもっと大量の画像を集める必要があります)。
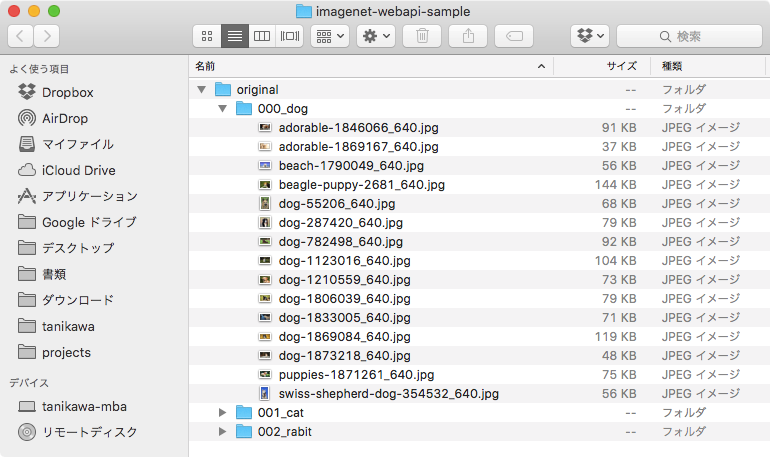
また、下記ファイルで動物とラベルの対応を管理します。各クラスに対して、ID(画像を格納するフォルダ名)、クラスの表示名、ラベル(ニューラルネットの出力ベクトルにおける index)を半角スペース区切りで記述します。
000_dog 犬 0
001_cat 猫 1
002_rabit うさぎ 2
画像の前処理を行う
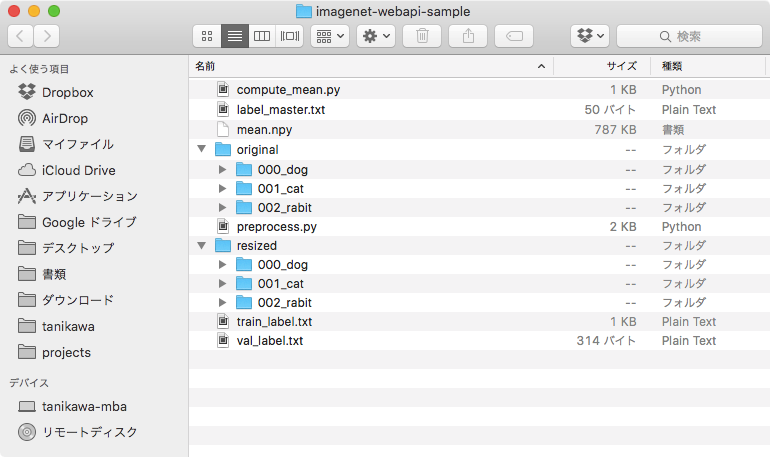
Chainer の imagenet では、256×256 の画像を扱うことが前提となっているようなので、収集した画像をリサイズします。また、imagenet で学習を行う際に、画像のパスとその画像のラベルを記述したテキストファイルが必要になるので、ここで作成します。
# coding: utf-8
import os
import shutil
import re
import random
import cv2
import numpy as np
WIDTH = 256 # リサイズ後の幅
HEIGHT = 256 # リサイズ後の高さ
SRC_BASE_PATH = './original' # ダウンロードした画像が格納されているベースディレクトリ
DST_BASE_PATH = './resized' # リサイズ後の画像を格納するベースディレクトリ
LABEL_MASTER_PATH = 'label_master.txt' # クラスとラベルの対応をまとめたファイル
TRAIN_LABEL_PATH = 'train_label.txt' # 学習用のラベルファイル
VAL_LABEL_PATH = 'val_label.txt' # 検証用のラベルファイル
VAL_RATE = 0.2 # 検証データの割合
if __name__ == '__main__':
with open(LABEL_MASTER_PATH, 'r') as f:
classes = [line.strip().split(' ') for line in f.readlines()]
# リサイズ後の画像の格納先を初期化
if os.path.exists(DST_BASE_PATH):
shutil.rmtree(DST_BASE_PATH)
os.mkdir(DST_BASE_PATH)
train_dataset = []
val_dataset = []
for c in classes:
os.mkdir(os.path.join(DST_BASE_PATH, c[0]))
class_dir_path = os.path.join(SRC_BASE_PATH, c[0])
# JPEG か PNG 画像のみ取得
files = [
file for file in os.listdir(class_dir_path)
if re.search(r'\.(jpe?g|png)$', file, re.IGNORECASE)
]
# リサイズしてファイル出力
for file in files:
src_path = os.path.join(class_dir_path, file)
image = cv2.imread(src_path)
resized_image = cv2.resize(image, (WIDTH, HEIGHT))
cv2.imwrite(os.path.join(DST_BASE_PATH, c[0], file), resized_image)
# 学習・検証のラベルデータを作成
bound = int(len(files) * (1 - VAL_RATE))
random.shuffle(files)
train_files = files[:bound]
val_files = files[bound:]
train_dataset.extend([(os.path.join(c[0], file), c[2]) for file in train_files])
val_dataset.extend([(os.path.join(c[0], file), c[2]) for file in val_files])
# 学習用ラベルファイルを出力
with open(TRAIN_LABEL_PATH, 'w') as f:
for d in train_dataset:
f.write(' '.join(d) + '\n')
# 検証用ラベルファイルを出力
with open(VAL_LABEL_PATH, 'w') as f:
for d in val_dataset:
f.write(' '.join(d) + '\n')
上記のコードを実行します。
$ python preprocess.py
うまくいけば、 resized ディレクトリ以下に 256×256 にリサイズされた画像と、プロジェクトルートに train_label.txt, val_label.txt が作成されます。
なお、preprocess.py の VAL_RATE の値をいじれば、学習データと検証データの比率を変更することが可能です。上記コードでは、学習 : 検証 = 8 : 2 の比率になっています。
画像のリサイズができたら、次に学習データセットの平均画像を作成します(入力画像から平均画像を引くのは一種の正規化処理です。そのための平均画像をここで作成します)。
Chainer の GitHub リポジトリの imagenet にある compute_mean.py をプロジェクト内に置き、次のコマンドを実行します。
$ python compute_mean.py train_label.txt -R ./resized/
実行後、mean.npy が生成されます。
学習する
リサイズ後の画像を使って学習を行います。
imagenet では、ニューラルネットのアーキテクチャがいくつか用意されていますが、今回は GoogleNetBN を使ってみます(次節で一部コードの改良を行います)。imagenet から train_imagenet.py と googlenetbn.py をプロジェクト内に置きます。
下記コマンドを実行すると学習が実行されます。 エポック数 (-E) には、データ量やタスクに応じて適切な値を指定してください。また、GPU ID (-g) も環境に合わせて指定してください(CPU で学習する場合、-g オプションは必要ありません)。
$ python train_imagenet.py -a googlenetbn -E 100 -g 0 -R ./resized/ ./train_label.txt ./val_label.txt --test
※ alex.py, googlenet.py, nin.py がローカルにない場合、train_imagenet.py をそのまま実行するとエラーが発生します。なので、これらのファイルもプロジェクト内に置くか、train_imagenet.py の問題の箇所をコメントアウトする必要があります。後者の方法に関しては こちら のコードを参照。
学習済みのモデルやログは、result フォルダに格納されます。
imagenet のコードを改良する
学習したモデルを用いて、任意の画像のクラス分類(推定)ができるようにします。imagenet のサンプルコードは、学習データおよび検証データ用のコードのみ記述されており、推定を行うコードを追加する必要があります。
といっても、基本的には __call__() の処理をベースに、loss 値を返している箇所を確率値に変えれば良いです。新たに predict() というメソッドを作成して、この処理を記述してみます。
class GoogLeNetBN(chainer.Chain):
# --- (省略) ---
def predict(self, x):
test = True
h = F.max_pooling_2d(
F.relu(self.norm1(self.conv1(x), test=test)), 3, stride=2, pad=1)
h = F.max_pooling_2d(
F.relu(self.norm2(self.conv2(h), test=test)), 3, stride=2, pad=1)
h = self.inc3a(h)
h = self.inc3b(h)
h = self.inc3c(h)
h = self.inc4a(h)
# a = F.average_pooling_2d(h, 5, stride=3)
# a = F.relu(self.norma(self.conva(a), test=test))
# a = F.relu(self.norma2(self.lina(a), test=test))
# a = self.outa(a)
# a = F.softmax(a)
h = self.inc4b(h)
h = self.inc4c(h)
h = self.inc4d(h)
# b = F.average_pooling_2d(h, 5, stride=3)
# b = F.relu(self.normb(self.convb(b), test=test))
# b = F.relu(self.normb2(self.linb(b), test=test))
# b = self.outb(b)
# b = F.softmax(b)
h = self.inc4e(h)
h = self.inc5a(h)
h = F.average_pooling_2d(self.inc5b(h), 7)
h = self.out(h)
return F.softmax(h)
改良版 googlenetbn.py の完全なコードはこちらをご参照ください。
上記のコードを見ると、__call__() の処理とほとんど同じであることがわかると思います。
ただし、GoogleNet には出力が3つ(メイン+補助2つ)ありますが、推定時には補助の2つの出力は必要ありません(この補助分類器は、学習時の勾配消失の対策として導入されているものです)1。コメントアウトの部分がその箇所に該当します。
上記のコードでは、最後に softmax 関数を適用しますが、softmax を省略して return h としても問題ありません。スコアを 0〜1 の範囲に正規化する必要がなく、計算量をできるだけ抑えたい場合は、省略した方が良いです。
ここでは GoogleNetBN を使いましたが、もちろん、AlexNet など imagenet のサンプルにある他のアーキテクチャも同じようにコードを改良すれば OK です。また、ResNet などを構築するのも良いと思います。
Web API サーバを作る
次に、Web API サーバを作ります。ここでは、Python の Web フレームワーク Flask を使って、サーバを構築します。
イメージとしては、クライアントから HTTP POST でサーバに画像を送ると、サーバ側で画像分類を行い、結果を JSON で返すといった処理を行うコードを記述します。
# coding: utf-8
from __future__ import print_function
from flask import Flask, request, jsonify
import argparse
import cv2
import numpy as np
import chainer
import googlenetbn # 他のアーキテクチャを使いたい場合はここを書き換えてください
WIDTH = 256 # リサイズ後の幅
HEIGHT = 256 # リサイズ後の高さ
LIMIT = 3 # クラス数
model = googlenetbn.GoogLeNetBN() # 他のアーキテクチャを使いたい場合はここを書き換えてください
app = Flask(__name__)
# JSON 中の日本語を ASCII コードに変換しないようにする (curl コマンドで見やすくするため。ASCII に変換しても特に問題ない)
app.config['JSON_AS_ASCII'] = False
# train_imagenet.py PreprocessedDataset の get_example() を参考
def preproduce(image, crop_size, mean):
# リサイズ
image = cv2.resize(image, (WIDTH, HEIGHT))
# (height, width, channel) -> (channel, height, width) に変換
image = image.transpose(2, 0, 1)
_, h, w = image.shape
top = (h - crop_size) // 2
left = (w - crop_size) // 2
bottom = top + crop_size
right = left + crop_size
image = image[:, top:bottom, left:right]
image -= mean[:, top:bottom, left:right]
image /= 255
return image
@app.route('/')
def hello():
return 'Hello!'
# 画像分類 API
# http://localhost:8090/predict に画像を投げると JSON で結果が返る
@app.route('/predict', methods=['POST'])
def predict():
# 画像読み込み
file = request.files['image']
image = cv2.imdecode(np.fromstring(file.stream.read(), np.uint8), cv2.IMREAD_COLOR)
# 前処理
image = preproduce(image.astype(np.float32), model.insize, mean)
# 推定
p = model.predict(np.array([image]))[0].data
indexes = np.argsort(p)[::-1][:LIMIT]
# 結果を JSON にして返す
return jsonify({
'result': [[classes[index][1], float(p[index])] for index in indexes]
})
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--initmodel', type=str, default='',
help='Initialize the model from given file')
parser.add_argument('--mean', '-m', default='mean.npy',
help='Mean file (computed by compute_mean.py)')
parser.add_argument('--labelmaster', '-l', type=str, default='label_master.txt',
help='Label master file')
parser.add_argument('--gpu', '-g', type=int, default=-1,
help='GPU ID (negative value indicates CPU')
args = parser.parse_args()
mean = np.load(args.mean)
chainer.serializers.load_npz(args.initmodel, model)
with open(args.labelmaster, 'r') as f:
classes = [line.strip().split(' ') for line in f.readlines()]
if args.gpu >= 0:
chainer.cuda.get_device(args.gpu).use()
model.to_gpu()
app.run(host='0.0.0.0', port=8090)
分類結果の JSON は次の構造を想定しています。内側の配列は、最初の要素がクラス名、次の要素がスコアです。各クラスはスコアが高い順にソートされます。
{
"result": [
[
"犬",
0.4107133746147156
],
[
"うさぎ",
0.3368038833141327
],
[
"猫",
0.2524118423461914
]
]
}
また、定数 LIMIT で、上位何個分のクラスを取得するかを指定できます。今回は動物が3種類しかないので、LIMIT = 3 としていますが、例えば、クラスが全体で100種類あり、そのうち上位10個分が欲しい場合は LIMIT = 10、1位だけで良い場合は LIMIT = 1 といったような指定が可能です。
コードが完成したので、実際にサーバを立ち上げてみます。
$ python server.py --initmodel ./result/model_iter_120
* Running on http://0.0.0.0:8090/ (Press CTRL+C to quit)
この状態でもう1つ別のシェルを用意し、curl コマンドを使ってサーバに画像を送ってみます(テスト画像は適当に用意します)。結果が返ってきたら成功です。
$ curl -X POST -F image=@test.jpg http://localhost:8090/predict
{
"result": [
[
"うさぎ",
0.4001327157020569
],
[
"猫",
0.36795011162757874
],
[
"犬",
0.23191720247268677
]
]
}
これで API サーバは完成です!あとは、自由にフロントエンドを作成し、API サーバにアクセスする仕組みを実装すれば、Web サービスとしても公開できます。
フロントエンドを作るには
TODO: 後日、別途記事を作成する予定です。
おわりに
本記事では、Chainer を使ったニューラルネットの学習方法から Web API サーバの作成について、一通り手順を追ってみました(初心者対象と言いつつ、説明が適当なところもありましたが、ここまで読んでいただきありがとうございました)。
エラーハンドリングや細かい調整などを考慮すると、もう少ししっかりと作り込まないといけませんが、ざっくりとはこんな感じだと思います。また、画像の処理も結構適当な方だと思うので、精度の面でもかなり改善の余地はあります。
みなさんも Chainer をどんどん使って、ディープラーニングのプロダクトを作っていきましょう!