Tomcatは使ったことがないのですが、試しに入れてみました。
Tomcatはノード同士でマルチキャストでセッション共有ができるので、Tomcatを複数のノードで動かしておいてフロントエンドのリバースプロキシでガンガン振り分けるスタイルが一般的かと思います。
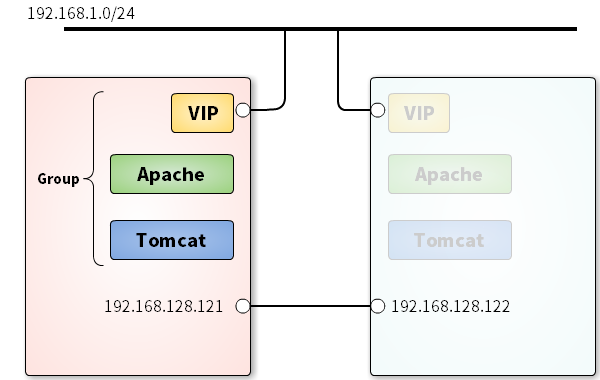
ですので、フロントエンドのApacheとかNGINXとか(もちろんデータベースも)と浮動IPアドレスをPacemakerで制御するのでしょうけど、単純にApacheとTomcatといずれかのノードで動かしそこに浮動IPアドレスを付与する、Active/Backupの構成にしてみました。
前提と初期設定
手前味噌ですがここの記事の手順でPacemaker 1.1の導入と設定を済ませておきます。
http://qiita.com/takehironet/items/ee6a50f7f9b349abd085
基本的には上の記事のとおりで、WindowsのVirtualBoxに2つ仮想マシンを作りました。
- ノード1: n1
- ノード2: n2
NICはサービス用に1枚、Pacemaker(のCorosync)の死活監視用に1枚設定しました。
CentOS 6.6はx86_64でminimalインストールしました。
特に大きな理由は無いですが、個人的に次のパッケージを追加するようにしています。
# yum install -y man wget ntp ntpdate policycoreutils-python vim
IPアドレスは、サービス用が192.168.1.0/24、死活監視用が192.168.128.0/24でそれぞれ
- ノード1
- サービス:
192.168.1.121 - 死活監視:
192.168.128.121
- サービス:
- ノード2
- サービス:
192.168.1.122 - 死活監視:
192.168.128.122
- サービス:
とし、アクセス用の浮動IPアドレスは192.168.1.120としました。
この段階でcorosync.confとcrmの設定は次のようになっています。
# Please read the corosync.conf.5 manual page
totem {
version: 2
crypto_cipher: none
crypto_hash: none
interface {
ringnumber: 0
bindnetaddr: 192.168.128.0
mcastport: 5405
ttl: 1
}
transport: udpu
}
logging {
fileline: off
to_logfile: yes
to_syslog: no
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: QUORUM
debug: off
}
}
nodelist {
node {
ring0_addr: 192.168.128.121
nodeid: 1
}
node {
ring0_addr: 192.168.128.122
nodeid: 2
}
}
quorum {
# Enable and configure quorum subsystem (default: off)
# see also corosync.conf.5 and votequorum.5
provider: corosync_votequorum
expected_votes: 2
}
CRMの設定はクラスタを構成した後で、どちらか片方のノードで行います。詳細は先の記事をご覧ください。
node 1: n1
node 2: n2
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=ignore \
stonith-enabled=false \
pe-input-series-max=3000 \
pe-error-series-max=3000 \
pe-warn-series-max=3000
rsc_defaults rsc-options: \
resource-stickiness=INFINITY \
migration-threshold=1
どちらのノードもクラスタに参加できていることをcrm_monなどで確認してください。
Java SE 8をインストール
TomcatはJavaで動作しますのでインストールします。
この作業は両方のノードで行います。
Oracle Java? OpenJDK?
Tomcat的にはOracleのJavaを推奨しているようですが、今回はOpenJDKを入れます。
単に動作確認したいだけですし、OpenJDKでも動いてくれるはずです。
そして、せっかくなのでJDK8をいれてみます。EPELにはjava-1.8.0-openjdkが試験的に含まれるようになりました ( http://wiki.centos.org/Manuals/ReleaseNotes/CentOS6.6/Japanese )。
インストール
EPELのリポジトリを入れてからjava-1.8.0-openjdk-develパッケージを入れます。
# yum install epel-release -y
# yum install java-1.8.0-openjdk-devel -y
お約束のバージョン確認です。
# java -version
openjdk version "1.8.0_31"
OpenJDK Runtime Environment (build 1.8.0_31-b13)
OpenJDK 64-Bit Server VM (build 25.31-b07, mixed mode)
Tomcat
Tomcatを入れるだけであればCentOS6.6のリポジトリにはTomcat6が、EPELにはTomcat7がありますのでそちらで十分です。
今回は最新版のTomcat 8.0.18を入れてみます。
この作業は両方のノードで行います。
Tomcat 8の入手
Apache Tomcatの公式からバイナリアーカイブを入手します。
# wget http://ftp.jaist.ac.jp/pub/apache/tomcat/tomcat-8/v8.0.18/bin/apache-tomcat-8.0.18.tar.gz
# tar -zxf apache-tomcat-8.0.18.tar.gz
# cd apache-tomcat-8.0.18
インストール
Tomcatのインストール場所をどこにするかと悩みました。
/var/lib/tomcat/usr/share/tomcat/opt/tomcat
ということで、試しにこんなかんじで見てみたらば、どうやら/var/lib/tomcatが良さそうということに。
# semanage fcontext -l | grep tomcat
/usr/sbin/tomcat(6)? regular file system_u:object_r:tomcat_exec_t:s0
/usr/share/munin/plugins/tomcat_.* regular file system_u:object_r:munin_services_plugin_exec_t:s0
/var/cache/tomcat6?(/.*)? all files system_u:object_r:tomcat_cache_t:s0
/var/lib/tomcat6?(/.*)? all files system_u:object_r:tomcat_var_lib_t:s0
/var/log/tomcat6?(/.*)? all files system_u:object_r:tomcat_log_t:s0
/var/run/tomcat6?\.pid regular file system_u:object_r:tomcat_var_run_t:s0
追記:間違っていましたね。
tomcatは/usr/share/tomcat
Tomcatユーザの追加
Tomcatを動作させるユーザとグループを追加しておきます。/usr/share/doc/setup-2.8.14/uidgidを参考にしました。
# groupadd -g 53 -r tomcat
# useradd -u 53 -r -s /sbin/nologin -d /var/lib/tomcat -g tomcat -c "
Apache Tomcat" tomcat
Tomcatファイル群の移動
展開したTomcatのディレクトリを/var/lib/tomcatとして移動します。
# mv ./apache-tomcat-8.0.18 /var/lib/tomcat
# restorecon -R /var/lib/tomcat
# chcon -R -u system_u /var/lib/tomcat
# chown tomcat. -R /var/lib/tomcat
一応動作確認をしておきます。
# service iptables stop
# sudo -u tomcat /var/lib/tomcat/bin/startup.sh
ブラウザでノードのIPアドレスを直接書いて8080番ポートにアクセスし、図のようなページが表示されればひとまずOKです。
一旦Tomcatは停止して置きます。
# sudo -u tomcat /var/lib/tomcat/bin/shutdown.sh
# service iptables start
Apache HTTP Server
TomcatのフロントエンドとしてApache HTTP Serverをインストールします。
CentOS 6.6に含まれるhttpd-2.2.15をそのまま使います。
この作業は両方のノードで行います。
インストール
Tomcat連携に必要なリバースプロキシモジュールやAJPモジュールも標準で入るので、次のコマンド一発でOKです。
# yum install -y httpd
Tomcat連携の設定
ここでは簡単のため、WebサーバへのアクセスをすべてTomcatへ回してしまいます。
/etc/httpd/conf.d/ajp.confを作成して次の内容で設定します。
<Location />
ProxyPass ajp://localhost:8009/
</Location>
ファイアウォールの設定
動作確認ではservice iptables stopなどとしても良いのですが、せっかくなのでここで設定します。
TCP 80番への接続を許可する設定を追加して、こんなかんじです。
# Firewall configuration written by system-config-firewall
# Manual customization of this file is not recommended.
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [0:0]
-A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 22 -j ACCEPT
-A INPUT -i eth1 -m udp -p udp --dport 5405 -j ACCEPT
-A OUTPUT -o eth1 -m udp -p udp --dport 5405 -j ACCEPT
-A INPUT -j REJECT --reject-with icmp-host-prohibited
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
COMMIT
設定したら適用しておきます。
# service iptables restart
動作確認
TomcatとApache HTTP Serverをそれぞれ動かしてブラウザからアクセスしてみます。
# sudo -u tomcat /var/lib/tomcat/bin/startup.sh
# service httpd start
今度はアクセス先のポートが変わって、80番になります。http://192.168.1.121/やhttp://192.168.1.122/を開いて、先ほどと同じページが表示されればとりあえず動作確認はOKです。
両方のノードで動作確認しておきましょう。
ひとまず停止
動作確認が済んだら、ひとまずTomcatとApache HTTP Serverを停止しておきます。
# service httpd stop
# sudo -u tomcat /var/lib/tomcat/bin/shutdown.sh
Pacemakerのリソース設定
ここから本題です。
Pacemakerがどんなリソース(サービス)をどこでどのように動かすか、という設定をしていきます。
基本的なコンセプトは、「TomcatとApacheをどちらか一方のノードで動作させ、クライアントは仮想IPアドレス経由でApacheにアクセスする」。
必要なリソースはなにかしら
Pacemakerはリソースを「リソースエージェント」を通じてコントロールします。どのリソースエージェントをつかって制御するかを挙げておきます。
- tomcat
- apache
- IPaddr2
- VIPcheck
tomcat, apacheは名前のとおりです。IPaddr2は仮想IPアドレスをNICに割り当てるもの、VIPcheckはすでに仮想IPアドレスがどこかで使われていないかを確かめるものです。
リソースの連携
それぞれのリソースがどのノードにどのように配置されるか、どのように連携するかを考えます。
リソースの配置ですが、今回はすべてのリソースをひとつのノードに集めてしまいます。クラスタの構成が単純になりますし、障害時のキャパが見積もりやすくもなります。
いずれかのリソースが欠けても全体がフェイルオーバーするようにします。例えばapacheが落ちたら仮想IPアドレスもtomcatもまとめて移動します。
次にリソースの起動や停止の順番を考えてみます。これはなにを重んじるかによって変わります。
今回は、このように考えてみました。
- 仮想IPアドレスは諸々の準備が出来てから付与する
- 仮想IPアドレスがそもそも付与できない状況(すでに存在する)場合には何をしても無駄になる
-
tomcatとapacheの順番はどちらでも良いが、下層から起動するならばtomcatが先 - 停止順は起動の逆で問題ない
すると、起動順はこうなります。
VIPchecktomcatapacheIPaddr2
CRM設定
ここから実際に設定を書いていきます。
現状動いている設定をテキストファイルに書き出して、それを編集していきます。
# crm configure save crm.txt
カレントディレクトリにcrm.txtというファイルができているので、慣れたエディタで開いて編集します。
今はこんなかんじになっているはずです。
node 1: n1
node 2: n2
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=ignore \
stonith-enabled=false \
pe-input-series-max=3000 \
pe-error-series-max=3000 \
pe-warn-series-max=3000
rsc_defaults rsc-options: \
resource-stickiness=INFINITY \
migration-threshold=1
ターミナルを2つ開いてSSHでログインし、ひとつはエディタ、ひとつはシェルにしておくとやりやすいですが、この辺りはおこのみでどうぞ。
VIPcheckリソースの定義
VIPcheck RAがどのようなパラメータを取るのか、調べてみます(以後は割愛します。必要に応じてお調べください)。
# crm ra info ocf:heartbeat:VIPcheck
VIPcheck resource agent (ocf:heartbeat:VIPcheck)
This is a VIPcheck Resource Agent.
Parameters (*: required, []: default):
target_ip* (string): target ip
ping target VIP address.
count (integer, [1]):
repeat times
wait (integer, [10]):
wait times
Operations' defaults (advisory minimum):
start timeout=60s
stop timeout=60s
monitor timeout=60s interval=10s start-delay=0s
*がついたパラメータは必須項目で、この場合はtarget_ipだけですね。
VIPcheckの実装はpingコマンドで、countとwaitはそれぞれ-cと-wに対応します。
したがって、wait秒以内にcount回のECHO_REPLYを受け取ったらpingが成功です。
pingに成功してしまうということはVIPcheckは失敗ということになります。
今回はtarget_ip=192.168.1.120 count=3 wait=5として設定します。するとリソースの定義は次のようになります。
primitive vipcheck ocf:heartbeat:VIPcheck \
params \
target_ip="192.168.1.120" \
count=3 \
wait=5 \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=60 on-fail="restart" start-delay=0
primitiveの後のvipcheckは管理用の名前です。一意であれば自由です(それなりに)。
この設定をproperty cib-bootstrap-options: \の前に割り込ませます。
opで始まる行はリソースの開始や停止、監視についての設定です。
今回はcrm ra infoの値をそのまま採用しました。
on-failはそれぞれのアクションに失敗した時の動作です。
restartは別のノードでリソースの再起動を試みます。
blockはそれ以後の処理を中断し、再起動は行いません。
ignoreは問題を無視し、処理を続行します。
今はこうなっています。
node 1: n1
node 2: n2
primitive vipcheck ocf:heartbeat:VIPcheck \
params \
target_ip="192.168.1.120" \
count=3 \
wait=5 \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=60 on-fail="restart" start-delay=0
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=ignore \
stonith-enabled=false \
pe-input-series-max=3000 \
pe-error-series-max=3000 \
pe-warn-series-max=3000
rsc_defaults rsc-options: \
resource-stickiness=INFINITY \
migration-threshold=1
tomcatリソースの定義
tomcat RAが求める必須オプションはjava_home, catalina_homeです。追加でtomcat_userを設定します。他にもログファイルやPIDファイルの置き場所を設定できますが今回は割愛します。
各アクションのタイムアウト値はゆったり目にします。環境によって調整が必要かもしれません。
設定に落としこむと次のようになります。
primitive tomcat ocf:heartbeat:tomcat \
params \
java_home="/usr/lib/jvm/java-1.8.0-openjdk" \
catalina_home="/var/lib/tomcat" \
tomcat_user="tomcat" \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=120 on-fail="ignore" \
op monitor interval=10 timeout=30 on-fail="restart"
こちらも適当な場所に追加して、こんなかんじになります。
node 1: n1
node 2: n2
primitive vipcheck ocf:heartbeat:VIPcheck \
params \
target_ip="192.168.1.120" \
count=3 \
wait=5 \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=60 on-fail="restart" start-delay=0
primitive tomcat ocf:heartbeat:tomcat \
params \
java_home="/usr/lib/jvm/java-1.8.0-openjdk" \
catalina_home="/var/lib/tomcat" \
tomcat_user="tomcat" \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=120 on-fail="ignore" \
op monitor interval=10 timeout=30 on-fail="restart"
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=ignore \
stonith-enabled=false \
pe-input-series-max=3000 \
pe-error-series-max=3000 \
pe-warn-series-max=3000
rsc_defaults rsc-options: \
resource-stickiness=INFINITY \
migration-threshold=1
apacheリソースの定義
apache RAはオプションの指定は任意です。
もし設定ファイルが/etc/httpd/conf/httpd.confになかったり、実行ファイルが/usr/sbin/httpdではなかったりする場合には適宜設定してください。
設定は次のようになります。
primitive apache ocf:heartbeat:apache \
op start interval=0 timeout=40 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=20 on-fail="restart"
全体は長くなってきたので割愛します。
IPaddr2リソースの定義
IPaddr2 RAの必須オプションはipです。目的のIPv4やIPv6のアドレスを指定します。
IPアドレスを付与するNICを指定するnicと、CIDRのプリフィックスを指定するcidr_netmaskを明示することが多いですが、今回はルーティングテーブルから判断させます。
設定は次のようになります。
primitive vip ocf:heartbeat:IPaddr2 \
params ip="192.168.1.120" \
op start interval=0 timeout=20 on-fail="restart" \
op stop interval=0 timeout=20 on-fail="ignore" \
op monitor interval=10 timeout=20 on-fail="restart"
試しに動かしてみる
ここらで試しに動かしてみます。
設定を流し込んでみましょう。
# crm configure load update crm.txt
crm_mon -DArで見ているとリソースが起動していく様子が見えます。
私のところではこうなりました。
Online: [ n1 n2 ]
Full list of resources:
tomcat (ocf::heartbeat:tomcat): Started n1
vipcheck (ocf::heartbeat:VIPcheck): Started n2
apache (ocf::heartbeat:apache): Started n1
vip (ocf::heartbeat:IPaddr2): Started n2
Node Attributes:
* Node n1:
* Node n2:
tomcatとapacheがノードn1で動作し、vipcheckとvipはノードn2で動いています。
場合によっては違った形になるかもしれません。
ひとまずStartedになっていて動いているのが確認できました。
(リソースの間に「共有ディスクへの接続」と「共有ディスク上のファイルシステムのマウント」のような依存関係があると、このような動作確認は出来ません)
さて、これらバラバラに動作しているリソースを束ねていきます。
グルーピング
CRMではgroupキーワードでリソースのグループを作れます。
groupは次のような機能を持っています。
- リソースを必ず同居させる (
colocationの機能) - リソースを必ず指定した順序で起動する (
orderの機能) - リソースを起動とは必ず逆の順序で停止する (
orderの機能)
ちょっと凝ったことをしたい場合にはカッコ書きで示した機能をバラバラに使って組み合わせます。
例えばグループをグループでまとめることは出来ませんので、それぞれのグループをcolocationとorderで制御します。
今回はとてもシンプルなので、こうかきます。
group web-grp \
vipcheck tomcat apache vip
グループ名はweb-group、起動順序は左から右、停止順序は右から左です。
動作確認する
ここまでで、今回の設定は完了とします。
設定ファイルcrm.txtはこうなりました。
node 1: n1
node 2: n2
primitive vipcheck ocf:heartbeat:VIPcheck \
params \
target_ip="192.168.1.120" \
count=3 \
wait=5 \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=60 on-fail="restart" start-delay=0
primitive tomcat ocf:heartbeat:tomcat \
params \
java_home="/usr/lib/jvm/java-1.8.0-openjdk" \
catalina_home="/var/lib/tomcat" \
tomcat_user="tomcat" \
op start interval=0 timeout=60 on-fail="restart" \
op stop interval=0 timeout=120 on-fail="ignore" \
op monitor interval=10 timeout=30 on-fail="restart"
primitive apache ocf:heartbeat:apache \
op start interval=0 timeout=40 on-fail="restart" \
op stop interval=0 timeout=60 on-fail="ignore" \
op monitor interval=10 timeout=20 on-fail="restart"
primitive vip ocf:heartbeat:IPaddr2 \
params ip="192.168.1.120" \
op start interval=0 timeout=20 on-fail="restart" \
op stop interval=0 timeout=20 on-fail="ignore" \
op monitor interval=10 timeout=20 on-fail="restart"
group web-group \
vipcheck tomcat apache vip
property cib-bootstrap-options: \
dc-version=1.1.12-561c4cf \
cluster-infrastructure=corosync \
no-quorum-policy=ignore \
stonith-enabled=false \
pe-input-series-max=3000 \
pe-error-series-max=3000 \
pe-warn-series-max=3000
rsc_defaults rsc-options: \
resource-stickiness=INFINITY \
migration-threshold=1
この設定を流し込みましょう。
# crm configure load update crm.txt
しばらくcrm_mon -DArfで見ていると、どちらかのノードですべてのリソースが動作するはずです(多分vipcheckが動いていたノード)。
Online: [ n1 n2 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n2
tomcat (ocf::heartbeat:tomcat): Started n2
apache (ocf::heartbeat:apache): Started n2
vip (ocf::heartbeat:IPaddr2): Started n2
Node Attributes:
* Node n1:
* Node n2:
Migration summary:
* Node n1:
* Node n2:
私の場合にはノードn2で動いています。
このままでも問題ありませんが気持ち悪い場合にはノードn1にリソースを移動します。
コマンドを打てばノードn1に移動することも出来ますが、ちょっとした罠があるので、ノードn2でPacemakerを再起動してしまいます。
# initctl restart pacemaker.combined
仮想IPアドレスにブラウザからアクセスしてみます。
相変わらずのページが表示されれば成功です。
リソースのプロセスを強制停止してみる
ここからは異常系のテストです。
Apache HTTP Serverのプロセスを強制停止してみます。
今、ノードn1でリソースが動いているので、ノードn2でcrm_mon -DArfしておき、ノードn1でプロセスをkillallします。
# killall -9 httpd
ノードn2ではまずこうなります。
Online: [ n1 n2 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n1
tomcat (ocf::heartbeat:tomcat): Started n1
apache (ocf::heartbeat:apache): FAILED n1
vip (ocf::heartbeat:IPaddr2): Started n1
Node Attributes:
* Node n1:
* Node n2:
Migration summary:
* Node n1:
* Node n2:
Failed actions:
apache_monitor_10000 on n1 'not running' (7): call=44, status=complete, last-rc-change='Sun Feb 8 22:30:44 2015', queued=0ms, exec=0ms
問題なく検知されました。
しばらく見ているとノードn2で再起動が完了します。ブラウザでも確認してみましょう。
Online: [ n1 n2 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n2
tomcat (ocf::heartbeat:tomcat): Started n2
apache (ocf::heartbeat:apache): Started n2
vip (ocf::heartbeat:IPaddr2): Started n2
Node Attributes:
* Node n1:
* Node n2:
Migration summary:
* Node n1:
apache: migration-threshold=1 fail-count=1 last-failure='Sun Feb 8 22:30:44 2015'
* Node n2:
Failed actions:
apache_monitor_10000 on n1 'not running' (7): call=44, status=complete, last-rc-change='Sun Feb 8 22:30:44 2015', queued=0ms, exec=0ms
Failed actions:に異常検知が記録され、その上のMigration summary:にもapache: .... fail-count-1と表示されています。
Pacemakerはapacheリソースがn1で障害を起こしたことを覚えていますので、仮にn2でもkillall -9 httpdしてしまうと、もうどのノードでもリソースを起動できなくなってしまいます。
やってみると、実に中途半端な状態で止まってしまいます。
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n2
tomcat (ocf::heartbeat:tomcat): Started n2
apache (ocf::heartbeat:apache): Stopped
vip (ocf::heartbeat:IPaddr2): Stopped
障害の原因を取り除いたらPacemakerに教えてあげる必要がありますが、ひとつは障害のあるノードでPacemaker自体を再起動する方法、もうひとつはfailcountをリセットする方法です。
後者のコマンドは次のように使います。
# crm resource cleanup apache
どちらのノードで打っても構いません。apacheはリソース名で、web-groupのようなグループ名でもOKです。
Online: [ n1 n2 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n2
tomcat (ocf::heartbeat:tomcat): Started n2
apache (ocf::heartbeat:apache): Started n2
vip (ocf::heartbeat:IPaddr2): Started n2
Node Attributes:
* Node n1:
* Node n2:
Migration summary:
* Node n1:
* Node n2:
綺麗になりました。
興味がある方は同じようにtomcatもお試しください。
仮想IPアドレスを故障させるには、ip addr del 192.168.1.120/24 dev eth0などとします。
死活監視LANのケーブルを抜いてみる
Pacemakerが死活監視に使っているLANのケーブルを抜いて、お互いに状況が見えなくなったらどうでしょう。
VirtualBoxではLANケーブルの挿抜がお手軽に出来ます。
iptablesをつかっても大丈夫ですが、この場合は「一方通行にならないようにする」必要があります。
「ifdownとかip link set downとかでもよいのでは」と思うのですが、実はこれをやるとCorosyncのプロセスが落ちます。
さて、両方のノードでcrm_mon -DArfしながらケーブルを抜くと、こうなります。
Online: [ n1 ]
OFFLINE: [ n2 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Started n1
tomcat (ocf::heartbeat:tomcat): Started n1
apache (ocf::heartbeat:apache): Started n1
vip (ocf::heartbeat:IPaddr2): Started n1
Node Attributes:
* Node n1:
Migration summary:
* Node n1:
Online: [ n2 ]
OFFLINE: [ n1 ]
Full list of resources:
Resource Group: web-group
vipcheck (ocf::heartbeat:VIPcheck): Stopped
tomcat (ocf::heartbeat:tomcat): Stopped
apache (ocf::heartbeat:apache): Stopped
vip (ocf::heartbeat:IPaddr2): Stopped
Node Attributes:
* Node n2:
Migration summary:
* Node n2:
vipcheck: migration-threshold=1 fail-count=1000000 last-failure='Sun Feb 8 22:49:19 201
5'
Failed actions:
vipcheck_start_0 on n2 'unknown error' (1): call=186, status=complete, last-rc-change='
Sun Feb 8 22:49:16 2015', queued=0ms, exec=2782ms
両方のノードでお互いがOFFLINEになっています。
ノードn1では動作していたリソースはそのままで、ノードn2ではすべてのリソースが停止しています。
よくみるとvipcheckの起動に失敗していますね。狙いどおりの動作です。
STONITHが使えない場合にはVIPcheckを使うことで簡易的かつ限定的ではありますが両方でリソースが起動することを防止できます。
このようなスプリットブレインからデータ(の整合性)を守りたい場合にはSTONITHが必須です。システムやデータの価値と、費用を比べて検討しましょう。
注意
- セキュリティはほとんど考慮していません。
- 実用的な構成ではありません。
- データベースもなく、デプロイは両方で行わなければなりません。