この記事はDocker Advent Calendar 2016 の13日目の記事です。
AWS re:Invent2016に初参加してきたのですが、一番印象に残っているのがAmazon AIをはじめとする
Deep learningの取り組みです。
そこで今回はAWSが公式にサポートを表明したDeep learningフレームワークであるMXNetを
ECSを使ってDockerコンテナで立ち上げて処理をしてみる、という内容になります。
MXNetとは
MXNet はワシントン大学とカーネギーメロン大学によって開発されたDeep learningフレームワークです。
re:Invent 2016で発表された内容から抜粋すると、特徴としては以下です。
- 豊富な対応言語
- 学習(train)には Python/C++/R/Scala/Java/Julia が使える
- 推論(prediction)には上記に加えてMatlab/JavaScriptが使える
- すべてコンパイルされてC++で動くので高速
- スケーラビリティ
- KVSを利用しているおり、複数ノードで分散処理が実行可能
- ノードを追加するだけでスケールアウトし、16台のp2.16xlargeインスタンスでテストしたところ理想的な状態から考えても88%の効率で処理することが出来た
- Tensorflowより効率的(By AWS)
- ポータビリティ
- モデルをストアする際に効率的に格納できる。1000レイヤのモデルを4Gのメモリに収めることが出来る
- Android/iOSでも動作可能
セッション後にAWSの方に質問した所、今回発表されたAmazon AI含めて各種サービスでMXNetが既に動いているようです。
今回やること
今回やることは基本的にはre:Invent 2016内のワークショップセッションで行われた、
ECSを用いてMXNetを動かしてみるものの拡張です。
拡張している所としては、
- CPU版ではなくGPU版として動かす
というところです。
なぜならDeep learningのタスクはCPUよりもGPUを使うほうが高速で、
大規模データの学習や多層ネットワークの場合は必須といってよいからです。
また、コンテナを使うメリットとしては上記サイトにも書いていますが、ポータビリティや処理の独立性だと思います。
環境構築はCloudformationを使わずにやってみます。
それでは始めます。
ECSクラスタの準備
ECSのクラスタを作成します。
サービスからECSを選びクラスターに移動します。
クラスタ名はmxnetとします。

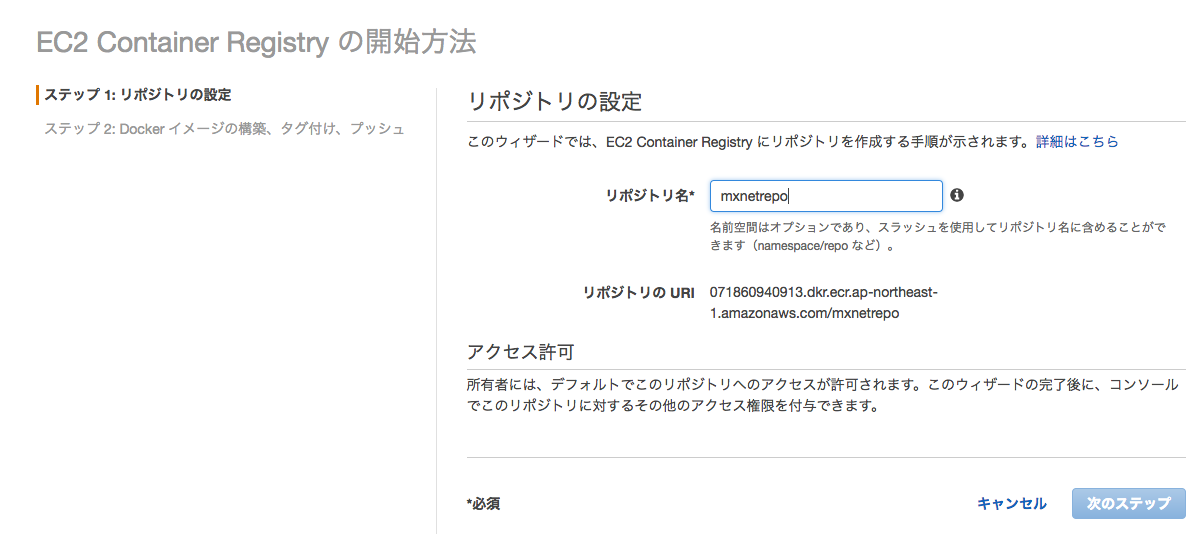
ECRのポジトリを作ります。
サービスからECSを選びリポジトリに移動します。
mxnetrepoとします。
インスタンスの準備
ベースイメージ起動
まずはGPUインスタンスを用意します。
P2インスタンスを使いたいところですが、東京リージョンでまだ使うことができず、
ちょっとお高いのでG2インスタンスを使います。
また、AMIはワークショップで使われていたAmazon ECS-optimized AMIを使っています。
Dockerとecs-agentコンテナを立てればAMIは通常のAmazon Linuxでも構いません。
起動時にuserdata(高度な詳細欄)として以下を入力します。
# !/bin/bash
echo ECS_CLUSTER=mxnet > /etc/ecs/ecs.config
nvidiaドライバのインストール
nvidiaドライバのインストールをここ
に従い行います。
まずは下準備。
sudo yum erase nvidia cuda
sudo yum update -y
sudo reboot
sudo yum install -y gcc wget aws-cli git kernel-devel-`uname -r`
次にnvidiaドライバのダウンロード及びインストールです。
P2インスタンスを使う場合はドライババージョンが違うのでご注意ください。
wget http://jp.download.nvidia.com/XFree86/Linux-x86_64/367.57/NVIDIA-Linux-x86_64-367.57.run
sudo /bin/bash ./NVIDIA-Linux-x86_64-367.57.run
sudo reboot
下記のコマンドが実行して結果が返ってくればOKです。
nvidia-smi -q | head
==============NVSMI LOG==============
Timestamp : Sat Dec 10 09:46:59 2016
Driver Version : 367.57
Attached GPUs : 1
GPU 0000:00:03.0
Product Name : GRID K520
Product Brand : Grid
nvidia-dockerのインストール
確認のためにnvidia-dockerをインストールします。詳細はこの記事をご参照ください。
wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.0-rc.3/nvidia-docker_1.0.0.rc.3_amd64.tar.xz
sudo tar --strip-components=1 -C /usr/bin -xvf /tmp/nvidia-docker*.tar.xz && rm /tmp/nvidia-docker*.tar.xz
起動します。
sudo mkdir -p /run/docker/plugins/
sudo -b nohup nvidia-docker-plugin > /tmp/nvidia-docker.log
再起動したときも使えるようにします。
sudo sh -c "cat << EOF > /etc/init.d/nvdocker-plugin
# !/bin/sh
# chkconfig: 345 98 20
# description: NVIDIA-docker plugin
nvidia-docker-plugin > /tmp/nvidia-docker.log
EOF"
sudo chmod +x /etc/init.d/nvdocker-plugin
sudo chkconfig --add nvdocker-plugin
確認します。以下の2つのコマンドは実質的に同じことです。
nvidia-docker run --rm nvidia/cuda nvidia-smi
docker run --rm --privileged --volume=nvidia_driver_367.57:/usr/local/nvidia:ro nvidia/cuda nvidia-smi
今のECS Agentは一度落としておきます。
docker rm -f ecs-agent
AMI作成
ここでイメージを作成します。
できあがったAMIからEC2を起動
作成したAMIをベースに選びます。
Userdata(高度な詳細欄)に以下を記載して実行します。
今回は3つインスタンスを起動しました。
# !/bin/bash
echo ECS_CLUSTER=mxnet > /etc/ecs/ecs.config
start ecs
ECSのmxnetクラスタに追加されていることが確認できればOKです。
MXNetコンテナの作成と登録
コンテナイメージ作成
MXNetのコンテナイメージをビルドします。
ワークショップで言うとLab2に当たります。
git clone https://github.com/awslabs/ecs-deep-learning-workshop.git
cd ecs-deep-learning-workshop/lab-2-build/mxnet
Labで公開されているイメージはCPU用なので、GPU用に置き換えます。
CUDAとCUDNNを有効にして、CUDAのPATHを指定します。
diffをとると次のような感じ。
- && echo "USE_CUDA=0" >>config.mk \
- && echo "USE_CUDNN=0" >>config.mk \
+ && echo "USE_CUDA=1" >>config.mk \
+ && echo "USE_CUDNN=1" >>config.mk \
&& echo "USE_BLAS=atlas" >>config.mk \
+ && echo "USE_CUDA_PATH=/usr/local/cuda" >>config.mk \
ビルドします。
docker build -t mxnet .
結構時間がかかります。
完了次第、docker imagesするとmxnetのイメージが出来上がっています。
ECRにプッシュ
まずdocker loginコマンドを取得します。
aws ecr get-login --region ap-northeast-1
次に返ってきたコマンドを実行します。
docker login....
プッシュるためにtagを変えます。
AWSACCOUNTIDは皆さんのAWSアカウントIDを入れます。
docker tag mxnet:latest AWSACCOUNTID.dkr.ecr.ap-northeast-1.amazonaws.com/mxnetrepo:latest
プッシュします。
docker push AWSACCOUNTID.dkr.ecr.ap-northeast-1.amazonaws.com/mxnetrepo:latest
コンソールで確認できればOKです。
コンテナデプロイとDeep learning実行
コンテナのデプロイと実行を行います。Lab3とLab4に当たります。
ECSでコンテナデプロイ
ECSのサービスのページからタスク定義を開き、タスクを作成します。
事前にボリュームのところでnvidiaドライバを設定しておきます。

コンテナの追加でmxnetを選びます。
AWSACCOUNTIDはみなさんのAWSアカウントIDです。
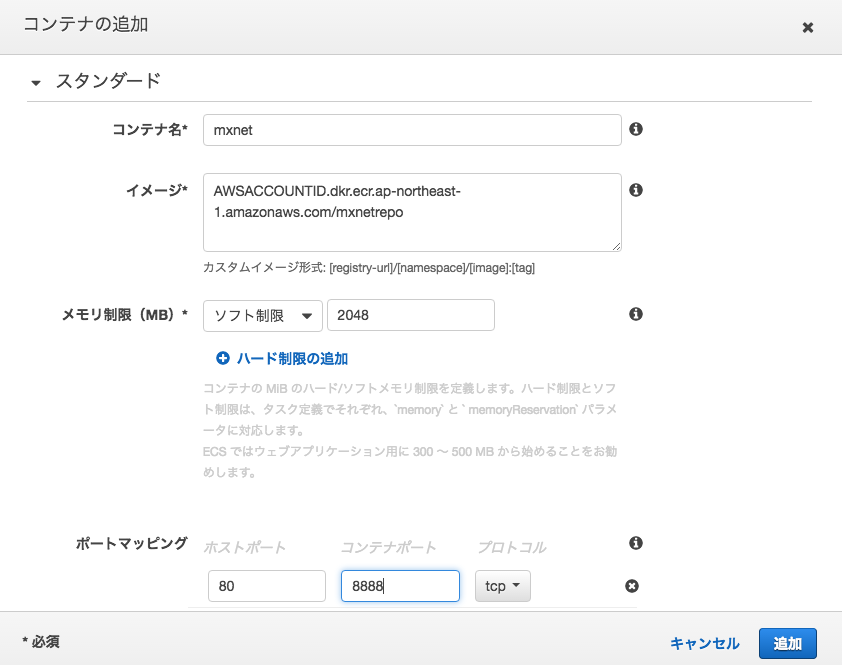
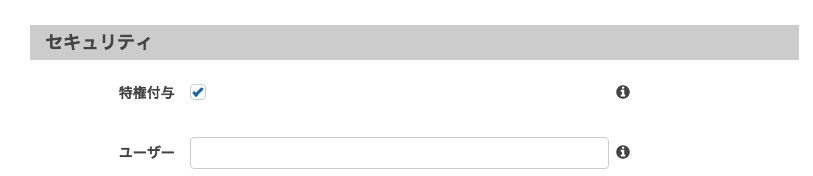
特権付与をONにします。
マウントポイントを指定します。
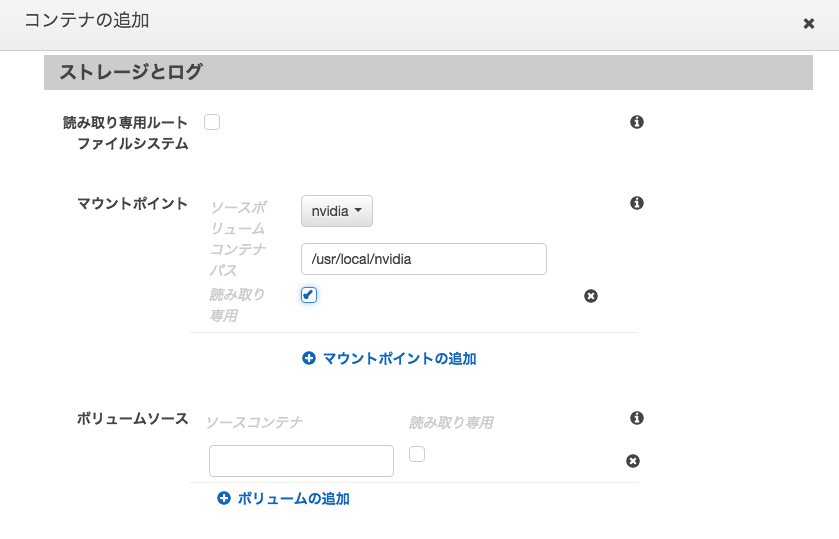
作成し終わったらタスク実行します。
タスクの数は分散処理を今後することを考えてEC2と同じ数で3としました。

タスクが実行されると3つ立ち上がります。
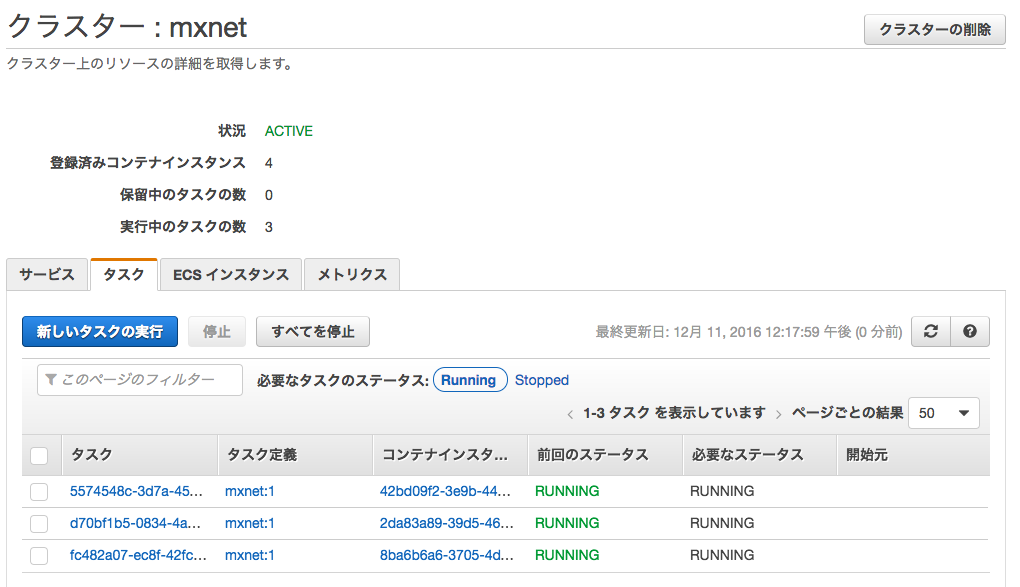
EC2にSSHでログインし、docker psコマンドを打つとイメージがあるのが確認できます。
[ec2-user@ip-172-22-1-30 mxnet]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
31253a08201d 071860940913.dkr.ecr.ap-northeast-1.amazonaws.com/mxnetrepo "/usr/local/bin/dumb-" 3 minutes ago Up 3 minutes 0.0.0.0:80->8888/tcp ecs-mxnet-2-mxnet-c298f8eda0beea8ced01
552b9821ff48 amazon/amazon-ecs-agent:latest "/agent" About an hour ago Up About an hour ecs-agent
実行
コンテナの中に入り、Deep learningを実行してみます。
docker exec -it 31253a08201d /bin/bash
コンテナの中でnvidia-smiを実行してみます。
root@31253a08201d:~/ecs-deep-learning-workshop# nvidia-smi
Sun Dec 11 03:48:12 2016
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 367.57 Driver Version: 367.57 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID K520 Off | 0000:00:03.0 Off | N/A |
| N/A 27C P8 17W / 125W | 0MiB / 4036MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
GPUが見えています。
ジョブを実行します。
実行するジョブは既に用意されているmnist(手書き文字)のトレーニングです。
cd /root/ecs-deep-learning-workshop/mxnet/example/image-classification/
python train_mnist.py
CPUでジョブが実行されます。
timeで実行時間をはかるとこんな感じです。
real 1m44.029s
user 1m54.208s
sys 0m18.404s
次にGPUを利用した場合を試してみます。
GPUで実行する場合はオプションを付けるとすぐです。
python train_mnist.py --gpus 0
実行時間の結果は以下です。
real 0m40.438s
user 1m25.152s
sys 0m11.612s
CPUよりも高速に学習ができています。
おわりに
Deep learningフレームワークのMXNetをコンテナとして実行する事ができました。
Amazon AIによって気軽にDeep learningの恩恵をうけられるようになりましたが、
どのようなことが行われているか、また自分で試してみたい場合には便利かと思います。
今後もし機会があれば分散処理実行を試してみたいです。