はじめに
社内での発表会のネタとしてWatson Developer Cloudを使ったWebアプリ開発に挑戦したので、そのまとめと備忘録になります。
アプリについて
機能(できるとは言っていない)
テキストを入力 or しゃべって質問すると、ある地点から半径1kmほどの飲食店の中から、Watsonがオススメのお店を紹介してくれます。
「からあげ定食が食べたい」「予算4000円までで魚系の居酒屋」など、思いついた言葉で問いかけることができます。
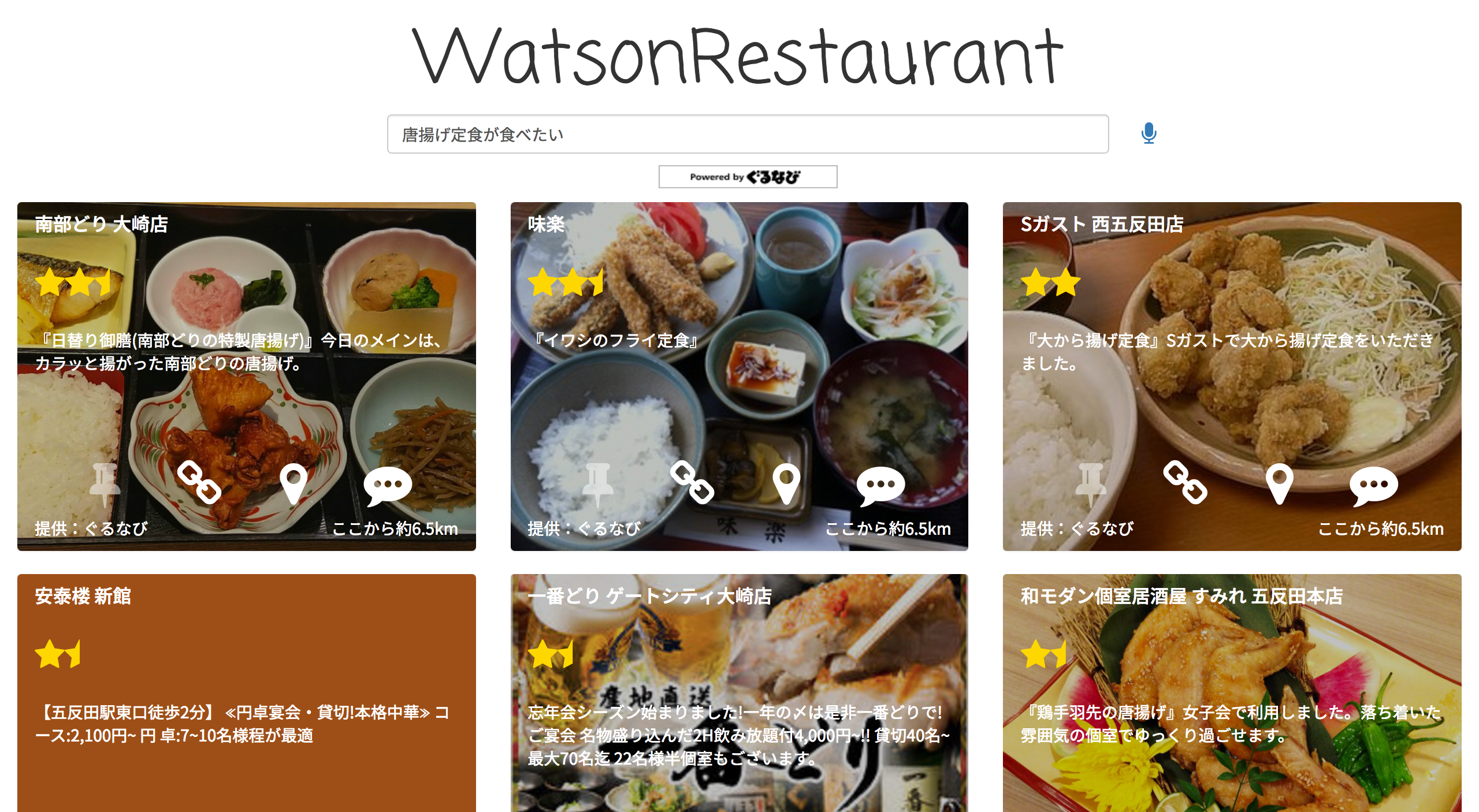
お店は一覧形式で表示されます。★が多いほどオススメの飲食店となります。
気になったお店は一覧にピン留めできるので、ぐるなびHPの情報や現在地からの距離・道順を確認しながら、訪れるお店を決めます。

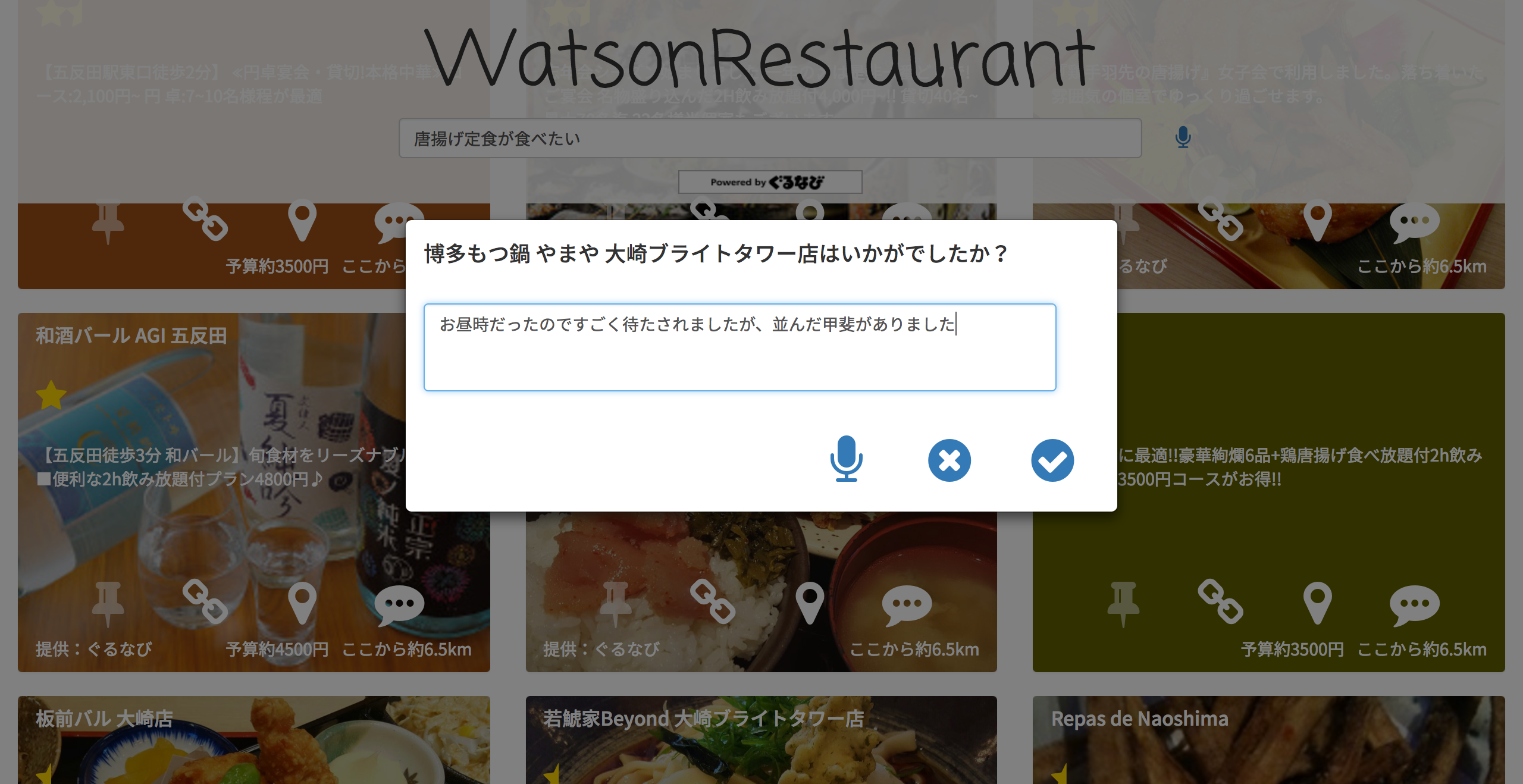
お店に行ったら(昔行ったことがある、でも構いません)、是非感想をコメントしてください。
「とっても美味しかった」なら他の人にもオススメできるお店、「店員が口喧嘩していた」ならあまりオススメできないお店など、コメントの内容を分析・学習し、検索結果が改善されます。
構成図
最初は全てBluemix上に構築しようとも考えたのですが、ClearDBの無料枠がこころもとなかった(5MB)のと、個人所有のPCの開発環境を整える意味も兼ねてこのようになりました。
クライアントのJSから適宜Node-RED上に用意したREST APIを呼び出して、検索結果表示やユーザーコメントの評価を行います。
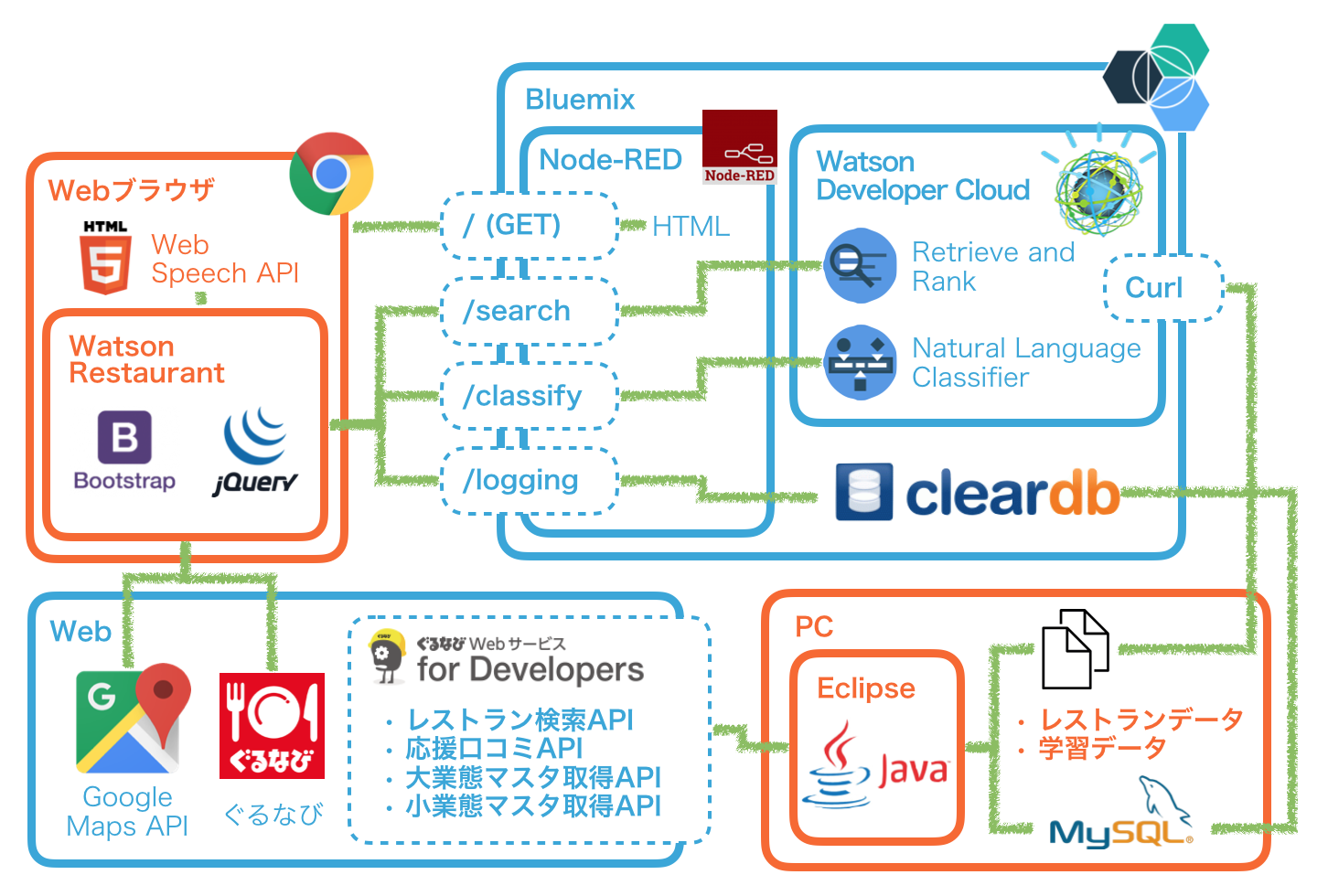
以下のような運用をイメージしています。
- ローカルにてR&R及びNLCのデータ作成・投入
- システムをユーザーが使うと、ClearDB上にログが蓄積される
- ログが溜まったらローカルにエクスポートしてきて、再度データ作成・投入
- 検索結果が改善される(されるとは言ってない)
所感
Retrieve and Rank
-
先日使ったばかりということもあって調子に乗っており、誤って高可用性クラスタを立ち上げて(=クラスタ作成時に、サイズを指定して作成)開発してしまいました。
- 数日作業したところで慌てて気づいて再作成したが、8000円ほど課金が発生…。
- 以下の要領で作成しましょう(cluster_sizeを空)
curl -k -X POST -u "**username:**password**" "https://gateway.watsonplatform.net/retrieve-and-rank/api/v1/solr_clusters" -d "{\"cluster_size\":\"\",\"cluster_name\":\"WatsonRestaurantCluster\"}"
- コレクションは以下のようにしました。
- 先達を真似しているだけなのですが、記事を書くにあたってTutorialを見たところ、違う書き方が例示されていたので、間違っているのかもしれません…
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="shop_id" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="vote_id" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="shop_name" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="shop_name_kana" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="menu_name" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="menu_name_kana" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="latitude" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="longitude" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="shop_url" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="image_url" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="pr_text" type="string" indexed="false" stored="true" required="true" multiValued="false" />
<field name="shop_text" type="watson_text_ja" indexed="false" stored="true" required="true" multiValued="false" />
<field name="budget" type="int" indexed="true" stored="true" required="true" multiValued="false" />
<fieldType name="watson_text_ja" indexed="true" stored="true" class="com.ibm.watson.hector.plugins.fieldtype.WatsonTextField">
<analyzer type="index">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" tokenizerFactory="solr.JapaneseTokenizerFactory" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.JapaneseTokenizerFactory" mode="search" userDictionary="lang/userdict_ja.txt" />
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true" tokenizerFactory="solr.JapaneseTokenizerFactory" userDictionary="lang/userdict_ja.txt"/>
<filter class="solr.JapaneseBaseFormFilterFactory"/>
<filter class="solr.JapanesePartOfSpeechStopFilterFactory" tags="lang/stoptags_ja.txt"/>
<filter class="solr.CJKWidthFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="lang/stopwords_ja.txt"/>
<filter class="solr.JapaneseKatakanaStemFilterFactory" minimumLength="4"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
ドキュメントデータをどのように生成したか(Retrieve)
- ぐるなびAPIを元ネタに1500件ほど生成
- ぐるなびのお店のPR文からドキュメント生成
- APIから連携される店舗ID毎に1ドキュメント
- ぐるなびの応援口コミからドキュメント生成
- 店舗ID+応援口コミIDに1ドキュメント
- システム利用者のコメントからドキュメント生成
- 店舗ID+ユーザーコメントからドキュメント生成(NLCにてポジティブ評価されたもののみ)
{
"id" : "5497472",
"shop_id" : "5497472",
"vote_id" : "",
"shop_name" : "天下一品 五反田店",
"shop_name_kana" : "テンカイッピンゴタンダテン",
"menu_name" : "",
"menu_name_kana" : "",
"latitude" : "35.624377",
"longitude" : "139.723394",
"shop_url" : "http://r.gnavi.co.jp/b5tzzw2g0000/",
"image_url" : "",
"pr_text" : "鶏と数種類の素材を時間をかけて煮込んだスープです。美容と健康にいいコラーゲンがいっぱいです。",
"shop_text" : "天下一品五反田店。テンカイッピンゴタンダテン。ラーメン 麺料理 その他。美容と健康にいいコラーゲンを豊富に含んでおり、他では絶対に味わうことができないスープです。他にも半チャーハンと中華そばがセットになった定食。ギョウザ、半ライス、中華そばがセットになったギョウザ定食。半チャーハン、ギョウザ、中華そばがセットになったサービス定食などメニューも豊富に取り揃えています。",
"budget" : -1
}
学習データをどのように生成したか(Rank)
- 初期移行(ユーザーのシステム利用に伴い発生する学習データなし)の段階で750件ほど作成
- カテゴリーから質問文を生成し、ドキュメントに加点
- 「イタリアン」という検索に対して、「イタリアン」を含むドキュメントに加点
- メニュー名から質問文を生成し、ドキュメントに加点
- 「唐揚げ定食」という検索に対して、「唐揚げ定食」を含むドキュメントに加点
- 詳細情報が閲覧されたドキュメントに加点
- ユーザーが検索したあるクエリに対する検索結果の中で、GoogleMap表示やぐるなびHPへのリンクが押下されたドキュメントに加点
- コメントが実施されたドキュメントに加減点
- コメントをNLCで解析した結果がポジティブ評価だった場合加点、ネガティブ評価だった場合減点
- ユーザー評価の高いドキュメントに加点
- ユーザーが検索した全てのクエリの検索結果の中で、ぐるなびで応援口コミが多くついているお店に加点
- NLCの判断結果に基づいて加減点
"%E3%83%AF%E3%83%83%E3%83%91%E3%83%BC","6364602.681550","2"
"%E3%82%BF%E3%82%A4%E3%82%AC%E3%83%91%E3%82%AA","7255599","1","7255599.4618610","3"
"%E5%A1%A9%E3%83%AC%E3%83%A2%E3%83%B3%E3%82%AC%E3%83%91%E3%82%AA","e584801.1192601","2","6408790.4601796","2","geyc200.4614278","4","g044108.4609358","4","6085706.1451291","1"
辞書データ(Solr機能)
- 辞書の生成にあたってKuromoji neologdを使ったのですが、Kuromojiと比較して色々な語を認識できており、これが無料で使えるなんて…と感じ入りました。
- お店の名前は、ぐるなびAPIから読みと合わせて取得できたので、それを用いています。
- 店名、メニュー名、カテゴリ名からユーザー辞書を生成
- 「こってりラーメン」という語で天一が検索上位に出て欲しい。
- カテゴリ大分類で検索された時に、内包されるカテゴリ小分類が検索されるように、シノニム辞書を生成
- 「イタリアン」で検索した時に「ピザ」を含むドキュメントが検索されるようにする。
- ストップワード辞書を適当に編集
- 「美味しい」、「お店」などの語は取り除いた方が良いような気がします。
- (有無で結果比較してないのでなんとも言えませんが…)
天下一品,天下一品,テンカイッピン,カスタム名詞
鶏々味鳥,鶏々味鳥,トリドリミドリ,カスタム名詞
魚匠五反田店,魚匠五反田店,ウオショウゴタンダテン,カスタム名詞
〆サバ,〆サバ,〆サバ,カスタム名詞
ラフテー,ラフテー,ラフテー,カスタム名詞
オーガニック => 薬膳料理 オーガニック料理 野菜料理 オーガニック
創作 創作料理 => 創作和食 創作料理 無国籍料理
イタリアン => イタリアン イタリア料理 パスタ ピザ
フレンチ => フレンチ フランス料理 ビストロ
Natural Language Classifier
- R&Rに比べれば、随分簡単に使えました。(ちゃんと判定されるとは言ってない)
ポジネガ判定用の学習データをどのように作成したか
- ポジ、ネガの2クラスに対して合計1600件ほど学習データを生成。
- R&Rは否定の言葉をうまく汲み取ってくれない(例:「美味しくない」という検索に「美味しい」が引っかかる)印象がありましたが、(学習データでカバーされていれば)ややこしい言い方でも正しく判定されるのが面白いと思いました。
- ポジティブ(yummy)
- ぐるなびAPIの応援口コミから、点数が高かったりイイねが多くついているレビューを句点毎に一定の長さに分割して登録。
- ネガティブ(yacky)
- ポジティブの逆(応援口コミ低評価)で生成できるのが期待値でしたが、ネガティブな評価が口コミにほとんど登録されておらず困惑…検閲でしょうか?
- 結局2ちゃんねるや飲食店のレビューブログから手コピペで登録。
"お腹も満足","yummy"
"息子の大好物です","yummy"
"新鮮職人さんたちの威勢のよさも、気持ちいい","yummy"
"でかいおなかいっぱい","yummy"
"懐かしい味","yummy"
"ひどい店でした","yacky"
"お刺身の鮮度が悪くまずかった","yacky"
"品質が悪い。微妙","yacky"
"中途半端で良いところがない","yacky"
"美味しくない。安っぽい","yacky"
クライアント周り
- R&R、NLCよりも、フォントやアイコンを整理したり、興味本位で導入したbootstrapやGoogleMapsAPIの理解に時間がかかりました…
- 予算による検索の絞り込みは、作り込みで検索文より金額を取得し、Solrのフィルタ機能を使ってやりました。
function getBudgets(query) {
var B_MIN = 0;
var B_MAX = 100000;
var B_RANGE = 500;
var budgets = null;
query = query.replace(/0-9/g, function(s) {
return String.fromCharCode(s.charCodeAt(0) - 0xFEE0);
});
var matches = query.match(/\d+(?=円)|(から|以上)|(まで|以内|未満|以下|足らず)/g);
if (matches) {
var yens = matches.filter(function(y) {
if (isFinite(y)) {
return y > B_MIN && y < B_MAX
} else {
return false;
}
});
if (yens.length == 1) {
var condition;
try {
condition = matches[matches.indexOf(yens[0]) + 1];
} catch (e) {
condition = null;
}
yens = yens.map(function(y) {
return Number(y.replace(/^0+/g, ""));
});
if (condition) {
if (/から|以上/g.test(condition)) {
budgets = {
budget_min: yens[0],
budget_max: B_MAX
};
} else {
budgets = {
budget_min: B_MIN,
budget_max: yens[0]
};
}
} else {
budgets = {
budget_min: yens[0] - B_RANGE,
budget_max: yens[0] + B_RANGE
};
}
} else if (yens.length >= 2) {
budgets = {
budget_min: Math.min(yens[0], yens[1]),
budget_max: Math.max(yens[0], yens[1])
};
}
}
if (budgets) {
budgets.budget_min = Math.max(B_MIN, budgets.budget_min);
budgets.budget_max = Math.min(B_MAX, budgets.budget_max);
return budgets;
} else {
return null;
}
}
サーバ周り、開発環境
- Node-REDは以下のような感じ。
- ~~R&RはHTTPノード、NLCは専用ノードでないとちゃんと動いてくれませんでした…。~~そもそもノードのフォームに資格情報を書いたのですが、今調べたところ、Bluemix側でサービス接続設定してれば専用ノードでそのまま動くんでしょうか?
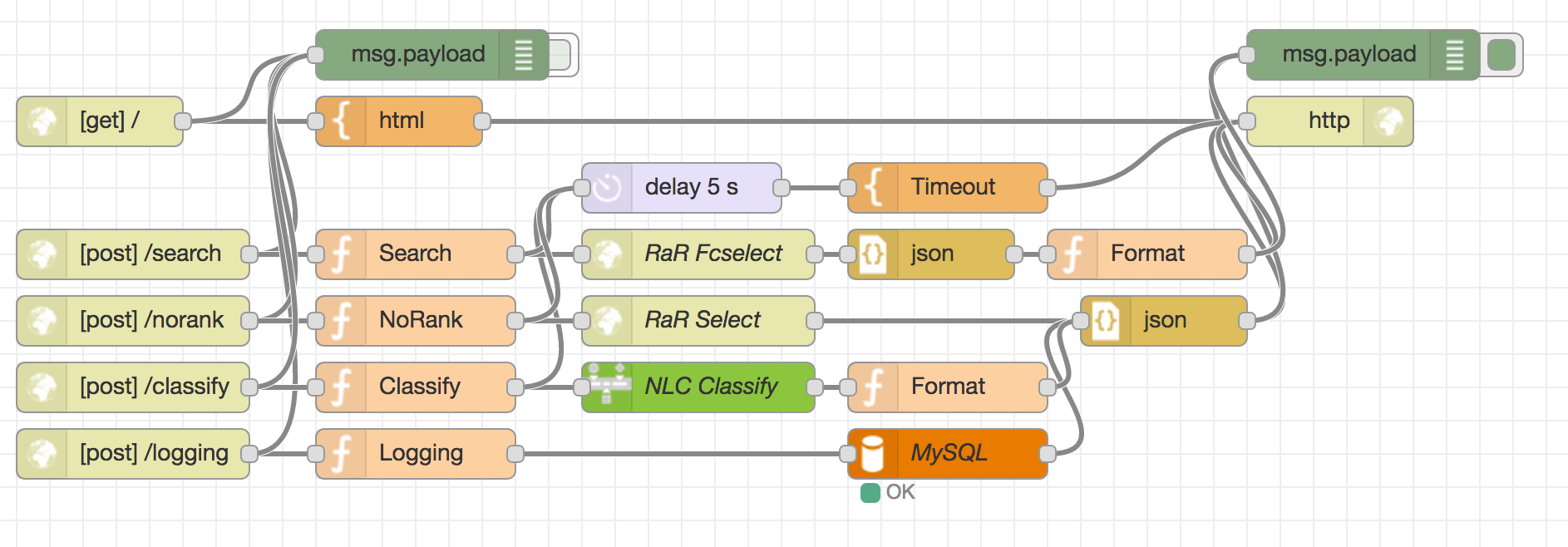
-
Javaは仕事であまり触れられてなかったのですが、REST呼び出し、JSON→DB、DB→JSONorCSVなど色々できて楽しかったです。
- EclipseのMavenが参照追加や削除のたびにエラーとなり、と思えば唐突に治り、よくわからず。
- 作業中生じたストレスの3/5ほどはMaven起因の気がします…
-
Ranker作成用学習データの生成にあたって、ある検索文の検索結果に対して返却されないドキュメントに加減点しようとするとtrain.pyにてエラーとなるため、JavaからSolrに対して検索をかけて、返却されるドキュメントを選別しています。
雑記
- 年末年始にだらだらやって4~5人日ほどで完成。
- 無料枠を考慮しなかった場合、維持費は〜5000円/月程度か?(Ranker1インスタンス1000円+NLC1インスタンス2000円+Node-RED〜1500円+学習API)
- 無料枠あり&作成しているアプリがこれだけの場合は維持費は0円にできる(はず?)
- 本番稼働時はこちらと言われている、高可用性クラスタを使うと…
- 肝心の学習の部分(RankerやNLCの仕組み・より良い作り方)については、よくわからず…。
- 特にR&Rについては、見た目に納得のいく検索結果にはなりませんでした。Ranker生成がお粗末だからだと思います…。
- 課金も気にしつつ、できれば近く改修したいと思います。
ソースコード
Githubに公開してみました。