下記記事のメモ。画像はリンク先から参照。
https://medium.com/google-cloud/paying-it-forward-how-bigquerys-data-ingest-breaks-tech-norms-8bfe2341f5eb
BigQueryはDremelとColossus、そしてBorgとJupiterネットワークと連携し、ユニークなアーキテクチャをしている。BigQueryでのデータロード特徴は以下のとおり。
バッチデータ投入にクエリ能力を消費しない
データ投入にはリソース(データ転送する際のネットワーク、暗号化や最適化、暗号化するためのCPUやRAM、データを書き込むためのI/O)が必要になる。HadoopやRedshiftなどでは、データ投入するのにクラスタのリソースが消費され、データ分析に影響がでる。
BigQueryではバッチ投入に使用されるリソースはクエリのリソースとは分離されてる。そのため、どれだけ大量のデータを投入しても、データ分析には影響がない。
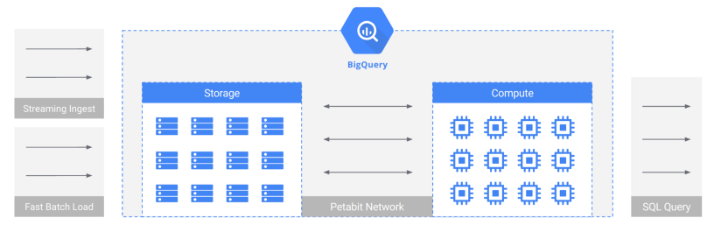
バッチ投入は無料
BigQueryのバッチ投入にはコストがかからない。Redshiftではクラスタを用意しないとデータ投入できないのでコストがかかり、AthenaだとS3上のファイル作成と管理のオーバーヘッドがある。
アトミックなデータロード
ロードに失敗する場合は100%データが失敗、すなわち中途半端にデータが残ることがないので、失敗したときのクリーンアップ処理が必要ない。ロードに失敗した場合はリトライすればよい。
BigQueryはロードに大量のCPUとRAMを消費する
BigQueryではクエリのリソースをデータロード時に消費しないが、裏では大量のリソースを使ってデータをロードしている。Capasitorストレージフォーマットは継続的にデータ全体をプロファイリングし最適化するため大量のリソースをデータロード時以外にも使用している。
データ投入は無制限
BigQueryはクォータを持っており、デフォルトでは1日当たり数十TBのデータが投入が可能である。いくつかの顧客は1日当たり1PBを超えるデータをロードしている。
Federated Queryは有償のバッチロードである
BigQueryはGCSのデータに対して直接クエリをかけることができる。このクエリは通常と同じようにクエリコストがかかる。クエリをかけた結果をBigQueryにロードすることができる。ある意味、有償のバッチロードである。