cuBLAS と NPP を使用して、GPUで動くNNの自前実装を行ってます。用いた関数群を紹介します。
背景
- 深層学習の理解を深めようと自前で実装を行ってます。
- GPU速い。15K¥位のgeforce GTX 1050tiでも、CPUに比べ10~100倍以上の実行速度があることを体感しました。
- GPUで演算を行わせるため、CUDA Toolkit の行列演算(cuBLAS)と 画像演算(NPP)のライブラリを活用します。
本記事では、行列演算と画像演算の活用しての、NN の全結合のAffin処理 を 公開します。
参考文献
- cuBLAS CUDA ToolKit
- About BLAS - BLASの簡単な使い方
- NPP CUDA Toolkit
- IPP インテル(R) インテグレート パフォーマンス・プリミティブ リファレンス・マニュアル(PDF)
cuBLAS
行列の積演算 図示
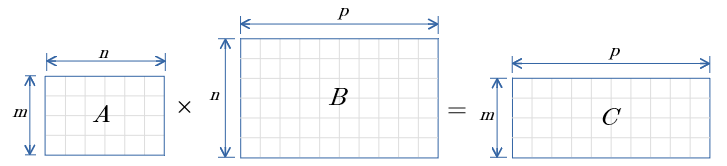
↓の図は↑の式を示します。
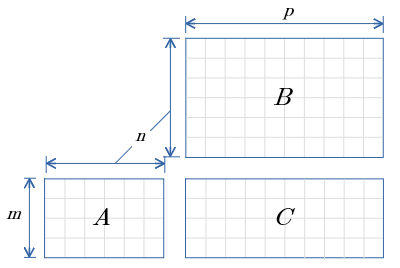
この図示方法、行数 列数の関係が一目で分かるのでいいですね。
行毎 および 列毎 の総和
gemv 関数 を用いて 行毎 または 列毎の 総和を算出する方法
gemv 関数は 行列と ベクトルの 積 を算出する関数
$y = αAx + βy$
$α,β$ はスカラ値、$x,y$はベクトル値、$A$は行列
引数で 行列$A$の 転置 の指示が可能
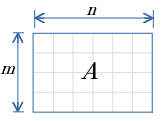
↑の行列を例に、gemv関数で 行毎 または 列毎 の総和の算出方法を示します。
行毎の総和
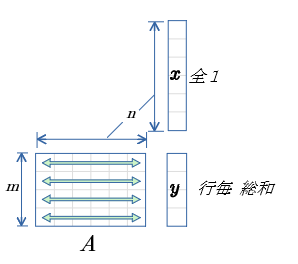
- ベクトル$x$ の値は 全て1.0
- ベクトル$y$ は、 行列$A$ の 行毎の総和 となる。
列毎の総和
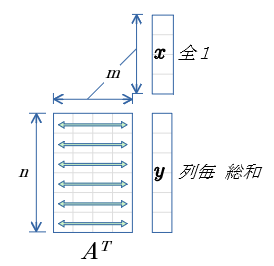
- 行列$A$ を転置。
- ベクトル$x$ の値は 全て1.0
- ベクトル$y$ は 行列$A$ の 列毎の総和 となる。
補足
- 入力画像のPixel が 整数型 の場合には、 NPP の SumWindowRow関数 , SumWindowColumn関数 が利用可能。
- 入力画像が float型 の場合に適した関数は見つからず、gemv関数で行ってますが、 適した関数があるのでしょうか?
Broadcast
ger関数 を用いて 行 または 列 のBroadcast を行う方法
ger関数は 列ベクトル と 行ベクトル の積の 行列 を算出する関数。
$A=αxy^T+A$
$α$ はスカラ値、$x,y$ はベクトル、$A$は行列。
列ベクトル の Broadcast
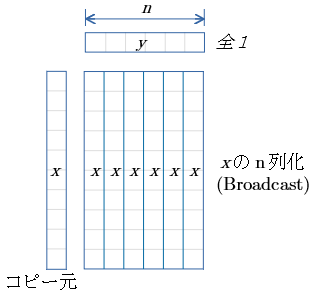
- 列ベクトル$x$ が コピー元。
- 行ベクトル$y$ は 全て1.0
- 結果行列 は $x$ をBroadcast したものとなる。
行ベクトル の Broadcast
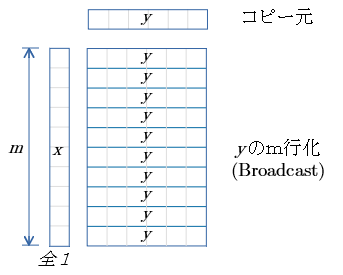
- 行ベクトル$y$ が コピー元。
- 列ベクトル$x$ は 全て1.0
- 結果行列 は $y$ をBroadcast したものとなる。
補足
もっと適した関数があるのでしょうか?
NPP
画像演算用のライブラリです。
cuBLASと補い合って使え便利です。
抜粋したものを下記します。
・ 下表内の"画像"は、画像内の各Pixel値 を示す。
・ 画像どうしの演算は、Width Height Channel bit数 が等しい前提で。
・ 各Pixel値 を float で扱える関数を抽出。
算術演算
| 関数識別名 | 概要 | 備考 |
|---|---|---|
| Add | 画像 + 画像 | |
| AddC | 画像 + スカラ値 | |
| Sub | 画像 - 画像 | |
| SubC | 画像 - スカラ値 | |
| Mul | 画像 × 画像 | アダマール積 |
| MulC | 画像 × スカラ値 | |
| Div | 画像 ÷ 画像 | |
| DivC | 画像 ÷ スカラ値 | |
| Abs | 画像の絶対値 | |
| Sqr | 画像$^2$ | |
| Sqrt | $\sqrt{画像}$ | |
| Ln | 自然対数 | |
| Exp | 指数関数 | |
| AddSquare | $B=A^2+B$ | $A,B$は画像 |
| AddProduct | $C=A×B+C$ | $A,B,C$は画像 バイアスありのアダマール積 |
| AddWeighted | $B=αA+(1-α)B$ | $A,B$は画像 $α$はスカラ値 |
| AbsDiff | Abs( $A-B$ ) | $A,B$は画像 |
| AbsDiffC | Abs( $A-α$ ) | $A$は画像 $α$はスカラ値 |
気づき
- cuBLAS には アダマール積がなく、GPUのカーネル関数を書くのかと思いましたが、NPPのMulはまんまアダマール積ですね...。
- GPUのカーネル関数を書かなくても、NPPの関数の組み合わせれば、NN用の演算は実現できそうですね。
比較演算
| 関数識別名 | 概要 | 備考 |
|---|---|---|
| Threshold | 各Pixelと閾値を比較演算し、真ならば、閾値に置き換える | 比較演算は「より大きい」と「より小さい」 |
| threshold_Val | 各Pixelと閾値を比較演算し、真ならば、引数値に置き換える | 比較演算は「より大きい」と「より小さい」 |
| Threshold_LTValGTVal | 各Pixelと2つの閾値(上限,下限)を比較演算し、真ならば、上限側,下限側のそれぞれの引数値に置き換える |
気づき
- Threshold関数で ReLUができますね!
- LeakyReLUも算術演算と組み合わせでできますね。
NPP 関数のサンプルコード
NPPのMUL関数のサンプルコードを示します。
内容
- float型 100×100 Pixel の2画像のMUL
- 画像A 全て 2.0 の値 を初期値とする
- 画像B 全て 4.0 の値 を初期値とする
- MUL演算の結果はBに格納されてくる
- Bの値を表示し 値が 8.0 になっている事を確認する
# include <cuda_runtime.h>
# include <npp.h>
int nppMul_example()
{
int matMean = (100*100);
size_t sz = sizeof(float) * matMean;
float *hA , *hB;
float *dA , *dB;
hA = (float *)calloc(matMean,sizeof(float));
if (hA == NULL){fprintf(stderr,"[%s L:%d]: calloc Error.\n",__FILE__,__LINE__);return -1;}
hB = (float *)calloc(matMean,sizeof(float));
if (hB == NULL){fprintf(stderr,"[%s L:%d]: calloc Error.\n",__FILE__,__LINE__);return -1;}
for(int i=0;i<matMean;i++)
{
hA[i] = 2.0;
hB[i] = 4.0;
}
if (cudaMalloc((void **)&dA, sz ) != cudaSuccess)
{
fprintf(stderr, "!!!! device memory allocation error (allocate A)\n");
return -1;
}
if (cudaMalloc((void **)&dB, sz ) != cudaSuccess)
{
fprintf(stderr, "!!!! device memory allocation error (allocate B)\n");
return -1;
}
// ホストのメモリからビデオメモリに配列をコピー
cudaMemcpy( dA, hA, sz, cudaMemcpyHostToDevice);
cudaMemcpy( dB, hB, sz, cudaMemcpyHostToDevice);
// Mul
NppiSize roi = {100,100};
NppStatus nppRet;
nppRet = nppiMul_32f_C1IR (
dA, //const Npp32f ∗ pSrc,
100*sizeof(float), //int nSrcStep,
dB, //Npp32f ∗ pSrcDst,
100*sizeof(float), //int nSrcDstStep,
roi //NppiSize oSizeROI
);
fprintf(stdout,"nppRet:%d\n",nppRet);
// ビデオメモリからホストのメモリにデータをコピー
cudaMemcpy( hA, dA, sz, cudaMemcpyDeviceToHost);
cudaMemcpy( hB, dB, sz, cudaMemcpyDeviceToHost);
// Aの確認 先頭の 10値を表示
printf("hA: ");
for(int i=0;i<10;i++) { printf ("%2.2f ",hA[i]); }
printf("\n");
// B(結果)の確認
printf("hB: ");
for(int i=0;i<10000;i++)
{
if (i%100==0){printf("\n");}
printf ("[%02d]%2.2f ",i%100,hB[i]);
}
printf("\n");
// B(結果)は意図通り 全て 8.0 になっている。
cudaFree(dA);
cudaFree(dB);
free(hA);
free(hB);
return 0;
}
// 省略
補足
- cuBLAS と同様に メモリ転送と NPP の目的の関数を呼び出すのみです。お手軽!
- GPU内のスレッド等は隠蔽されてます。
全結合NN の Affin の 行列演算
順伝播
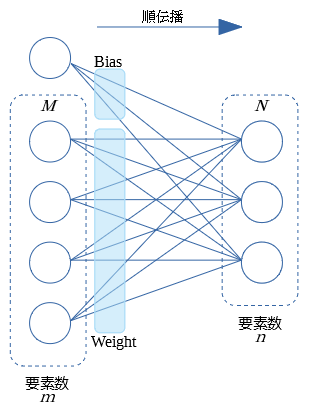
- $M$ は前層からの順伝播の値 $m$個のパーセプトロン
- $N$ は今層での Affin 後の値 $n$個のパーセプトロン
- 個々のパーセプトロンの式は、以前の記事にも記してあります。参考に...。
オンライン
$N=(Weight)M + Bias$
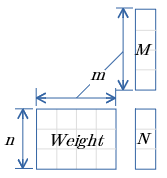
ミニバッチ
$N=(Weight)M + Bias$
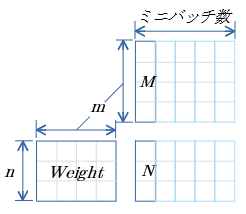
- cuBLASのgemm関数 $C=αAB+βC$ ( $A,B,C$ は行列、$α,β$はスカラ値)を用いる。
- $α=1.0$ $β=1.0$
- $C$(上図$N$)は、初期値として$Bias$を ミニバッチ数の Broadcast を行っておく。
ミニバッチ用行列 の 行優先メモリイメージ
cuBLASでは メモリを列優先として扱うが、C言語では行優先で扱うため、上記行列(列優先)の行優先の表記も示します。
行優先表記
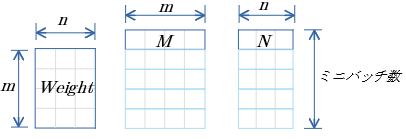
前記事での(行優先・列優先)実装の話も参考に...。
逆伝播
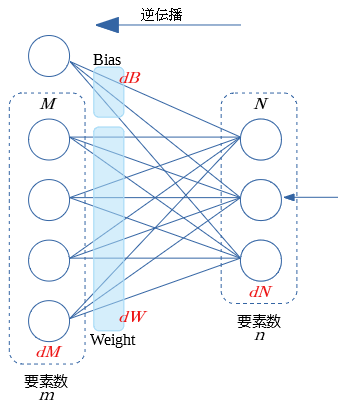
- $dN$ は後続層からの逆伝播の入力値
- $dM$ $dW$ $dB$ を算出する
dM
$dM=(Weight)^TdN$
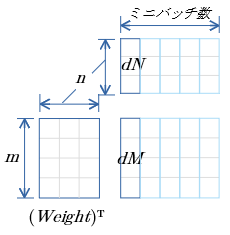
- $Weight$ は 転置
- cuBLASのgemm関数 $C=αAB+βC$ ( $A,B,C$ は行列、$α,β$はスカラ値)を用いる。
- $α=1.0$ $β=0.0$
dM 行優先メモリイメージ
行優先表記
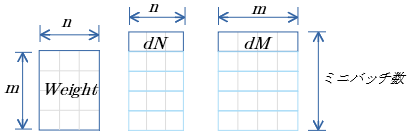
dW
$dW=dN(M)^T$
- $M$ は 転置
- cuBLASのgemm関数 $C=αAB+βC$ ( $A,B,C$ は行列、$α,β$はスカラ値)を用いる。
- $α=1.0$ $β=0.0$
dW 行優先メモリイメージ
行優先表記
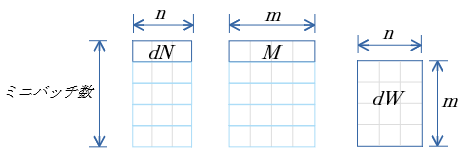
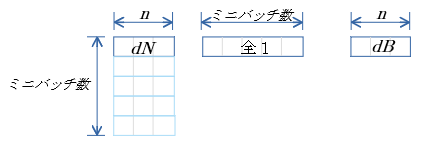
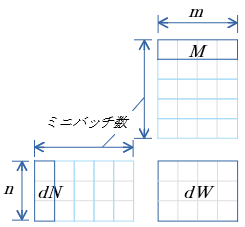
dB
$dB=\sum^{ミニバッチ数}_{i=1} dN$
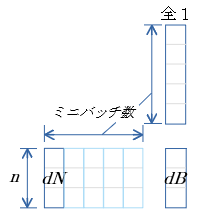
- gemv 関数 を用いて 行列$dN$ の 行毎の総和 を算出する
dB 行優先メモリイメージ
行優先表記