ディープラーニングにおける物体領域認識の必要性
最近ディープラーニングについて勉強していまして、あらかじめ人間によってトリミングや処理された認識しやすい下記のような画像の認識は90%以上の高確率で出来るようになりました。
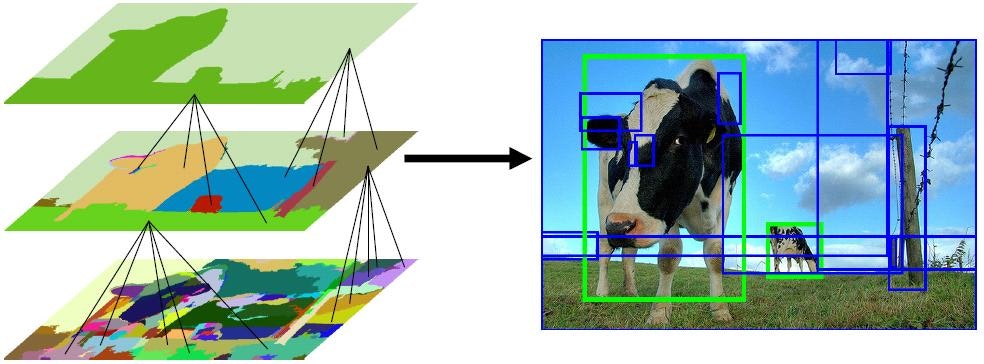
しかしこの前処理を人間がやっていたのではディープラーニングを使う利点が大きく削がれてしまいます。そこで複数の物体を含む画像からそれぞれの物体領域を認識し、その領域ごとにニューラルネットワークによる認識を行うプロセスいわゆるR-CNN(Regions with Convolutional Neural Network)を使う必要があります。R-CNNを使用する事で下の画像のような検出が可能になります(まだできてないけどCaptcha Breakerを作ってます)。

そこで、物体領域認識にはいくつかの方法があるので簡単にまとめてみようと思います。
Objectness
古くから使われている物体認識方法です。1枚の画像を10,000枚以上に分割して顕著度、エッジ、色や場所を基としたスコア付けがなされたのち、スコアが高い部分が物体領域として認識されるという方法です。スコア付けは割と緩く行われるが精度は高く、処理速度も良好のようです。出力として画像中の座標と物体らしさのスコアが得られます。問題点として一度検出がスルーされてしまうと再帰させるのが難しいという点、物体の詳細な輪郭は得られない点があります。古くからある方法のため論文やドキュメントが多く、参照しやすいです。

CPMC(Constrained Parametric Min-Cuts)
Objectnessと同様に古くからある物体認識方法です。前景として配置された点(Seeds)の周囲にグラフカット処理が行われ、それらを基に物体領域を認識するという方法。処理速度が非常に遅いがかなりの高精度で物体領域が検出できるようです。また強みとしてObjectnessでは得られない物体の輪郭が高精度で得られるという点があり、目的の物体を背景から切り離して処理したい時などに適しています。

Selective Search
最近何かと流行っている物体認識方法。色やテクスチャ特徴を基に類似度が高い近接領域を段階ごとに結合していき、最終的に一枚の画像を一つの結合体にします。その段階的な変化を基に物体領域を認識するという方法。精度が高く、処理速度も高速ですがパラメータ調整が大変なようです。複数のパラメータ設定で並列処理することで認識率を上げることができます。物体の輪郭も得る事ができますがCPMCにの精度には及びません。物体の詳細な輪郭を得る必要がない場合は良い選択肢の一つになりそうです。
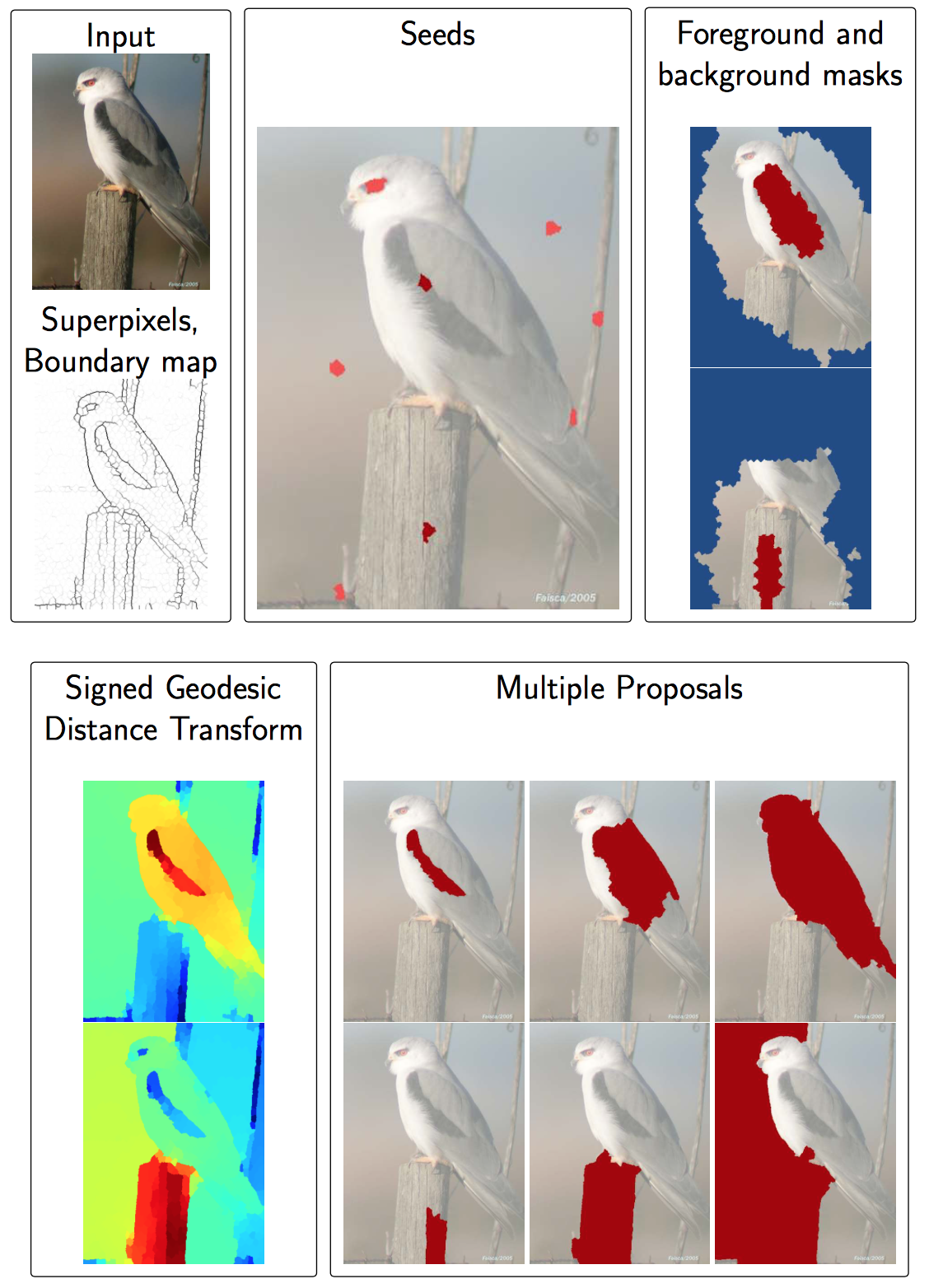
Object Proposals
CPMCと類似している物体認識方法です。前景として配置された点(Seeds)からピクセルごとの結合を基に物体の境界予測を複数作成しその全体の傾向から物体領域を認識するという方法。CPMCと同様の長所、短所を持っていて処理速度はCPMCと同様遅いですが高精度の認識ができ、物体の輪郭も得る事ができます。物体をパーツごとに認識できる(鳥の羽の部分のみや人の顔の部分のみなど)ためより細かい画像分類などに向いています。動植物の分類などを目的としている場合は良い選択肢となりそうです。
まとめ
物体領域認識はCNNによる認識の上流にくるので、CNNのチューニング以上に画像認識率に関わってきます。これらの他にも様々な方法があり、用途によって最適な物体領域認識方法を選択する必要が有ります。またこれらの物体領域検出方法も学習により精度が改善されるみたいなので色々と試してみたいです。
他に方法を見つけ次第随時追加していこうと思います。
何か問題点、改善点ありましたら教えてください。
参考文献
- Objectness measure V2.2
- Homepage of Koen van de Sande
- CPMC: Automatic Object Segmentation Using Constrained Parametric Min-Cuts By Joa ̃o Carreira and Cristian Sminchisescu
- [Geodesic Object Proposals By Philipp Kr ̈ahenbu ̈hl and Vladlen Koltun] (http://www.philkr.net/home/gop)