Exponential Linear Units
問題、解決法、効果
解決したい問題は、勾配が消失して学習が進まなくなること(vanishing gradient problem)
↓
ELUは、activation関数を通ったあとの出力の平均を0に近づけることで、bias shiftを軽減している
↓
学習が速く収束する(効率がよい)
ReLUの問題点(bias shift)
・ReLUは、非負の関数(non-negative)なので、その出力の平均は0より大きくなる傾向になる(bias shift)。
・それが次の層の入力となるので、Cancelする機能がないと、さらにbias shiftが起こる
・Unit毎の相関が高いほど、bias shiftが大きくなる
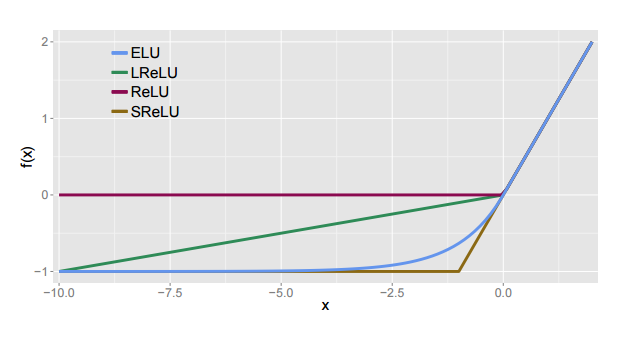
その他のActivation関数
ReLUを改良したものには、
・"Leaky ReLUs"(LReLUs)
・"Parametric ReLUs"(PReLUs)
・"Randomized Leaky ReLUs"(RReLUs)
がある。
LReLUs, PReLUs, RReLUsは、非活性領域でNoiseにrobustではない。
これは、非活性領域(負の領域)で値がSaturationしないため。
Exponential Linear Units(ELU)
f(x)= \left\{ \begin{array}{ll}
x & {\rm if}\: x > 0\\
\alpha (exp(x)-1) & {\rm if}\: x \le 0
\end{array} \right.
f'(x)= \left\{ \begin{array}{ll}
1 & {\rm if}\: x > 0\\
f(x) + \alpha & {\rm if}\: x \le 0
\end{array} \right.
・Bias Shiftを軽減するために、負の値を取るようにした
・非活性領域でNoiseにRobustになるように、一定の値でSaturationするようにした
・正の領域では入力の大きさによって出力が変わるようにし、負の領域では値の大きさは重要ではないので一定値でSaturationさせる
Experiments
Activation Function
Rectified Linear Units(ReLUs)
f(x) = {\rm max}(0,x)
Leaky ReLUs(LReLUs)
f(x) = {\rm max}(\alpha x,x)\:(0 < \alpha < 1)
Shifted ReLUS(SReLUs)
f(x) = {\rm max}(-1,x)
Exponential Linear Units(ELUs)
f(x)= \left\{ \begin{array}{ll}
x & {\rm if}\: x > 0\\
\alpha (exp(x)-1) & {\rm if}\: x \le 0
\end{array} \right.
DataSet
| Dataset | image | # of class | # of training data | # of test data |
|---|---|---|---|---|
| MNIST | gray image | 10 | 60k | 10k |
| CIFAR-10 | color image | 10 | 50k | 10k |
| CIFAR-100 | color image | 100 | 50k | 10k |
| ImageNet | color image | 1000 | 1.3M | 100k |
MNIST
Learning
Structure & Parameter
・ Dataset:MNIST
・ 8 hidden layer
・ SGD learning rate = 0.01
・ Minibatch size = 64
・ 300 epoch
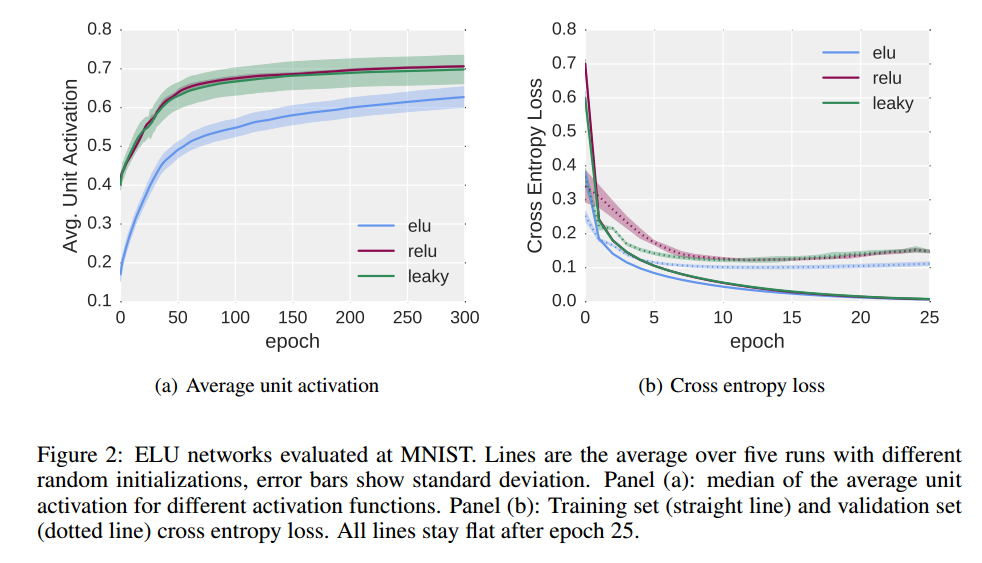
※左のグラフ:5回テストしたので薄い色で幅を表現し、平均を実線で表示
※右のグラフ:実線...Training Set、破線...Validation Set
左のグラフを見ると、activationの出力平均が他のactivation関数より0に近くなっている。
右のグラフから他のactivation関数より速く収束しているのがわかる。
Autoencoder
Structure & Parameter
・ Dataset:MNIST
・ 4 fully connected hidden layer
・ Unit Size L1:1000, L2:500, L3:250, L4:30
・ DecoderはEncoderを反対にしたもの
・ SGD Learning Rate=$10^{-2},10^{-3},10^{-4},10^{-5}$
・ Minibatch size = 64
・ 500 epoch
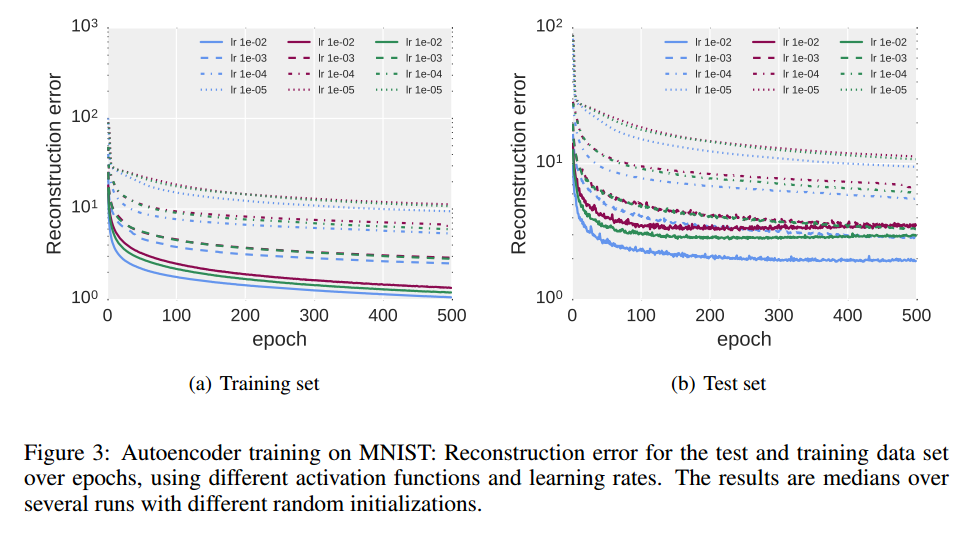
ELUが速く収束している。
負の値をとり、SaturationするSReLUもいい結果になっている。
Activation関数毎の比較
Structure & Parameter
・ Dataset:CIFAR-100
・ 11 convolutional layer
[1 × 192 × 5], [1 × 192 × 1, 1 × 240 × 3], [1 × 240 × 1, 1 × 260 × 2], [1 × 260 × 1, 1 × 280 ×
2], [1 × 280 × 1, 1 × 300 × 2], [1 × 300 × 1], [1 × 100 × 1]
[]の中の意味は、[layers x units x receptive fields(kernel size)]
・ 2×2 max-pooling with a stride of 2
・ drop-out rate = (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.0)
・ L2-weight decay regularization term 0.0005
・ learning rate schedule 0 − 35k[0.01], 35k − 85k[0.005], 85k − 135k[0.0005], 135k − 165k[0.00005]
・ Preprocessing: global contrast, ZCA whitening
・ image padding 4 zero pixels at all borders
・ 32 × 32 random crop
・ random horizontal flipping
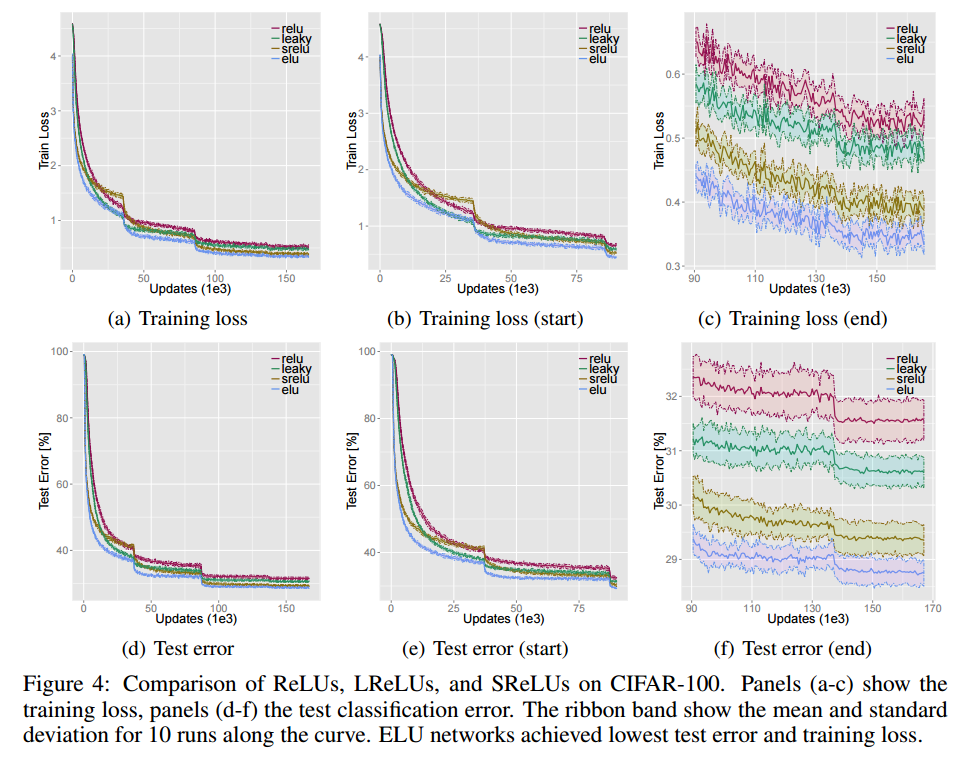
| Activation Function | Test Error |
|---|---|
| ELUs | $28.75(\pm0.24)%$ |
| SReLUs | $29.35(\pm0.29)%$ |
| ReLUs | $31.56(\pm0.37)%$ |
| LReLUs | $30.59(\pm0.29)%$ |
ELUsが収束が速く、Test Errorも一番いい結果になっている。
負の値をとり、SaturationするSReLUもいい結果になっている。
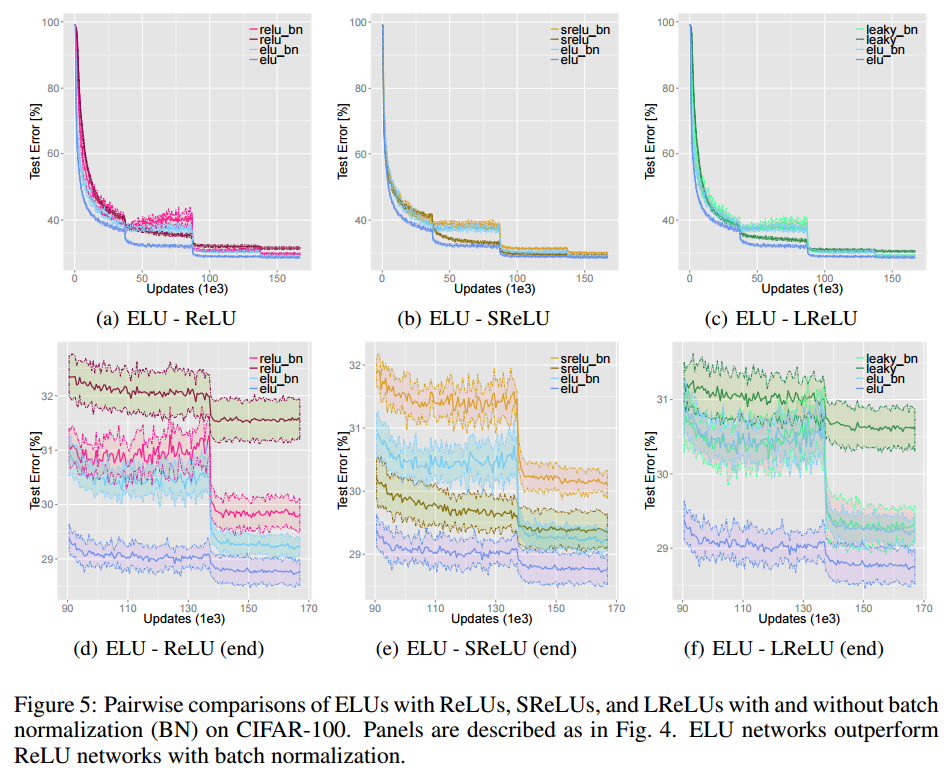
CIFAR-10/CIFAR100
Structure & Parameter
・ Dataset:CIFAR-100
・ 18 convolutional layer
[1×384×3], [1×384×1, 1×384×2, 2×640×2], [1×640×1, 3 × 768 × 2], [1 × 768 × 1, 2 × 896 × 2], [1 × 896 × 3, 2 × 1024 × 2], [1 × 1024 × 1, 1 × 1152 × 2], [1 × 1152 × 1], [1 × 100 × 1]
・ Initial drop-out rate, Max-pooling after each stack, L2-weight decay, momentum term, data preprocessing, paddingは前と同じ
・ Learning Rateは初期値0.01を35K回まで、そのあとは0.01を1/10
・ Minibatch Size = 100
・ 最後の50K回のdrop out rateは、(0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.0)、さらにそのあと40K回はdrop out rateを1.5倍
Learning RateとDrop out rateを学習回数により変えているがたしかに、Test Error Rateのグラフがそのあたりで変化している。

CIFAR-10では2番、CIFAR-100では1番の結果になっている
ImageNet
Structure & Parameter
・ Dataset:ImageNet
・ 15 layer CNN
1 × 96 × 6, 3 × 512 × 3, 5 × 768 × 3, 3 × 1024 × 3, 2 × 4096 × F C, 1 × 1000 × F C
・ 2×2 max-pooling with a stride of 2
・ 最初のFully Connected Layerの前で、3 levelのspatial pyramid pooling (SPP)
・ L2-weight decay term 0.0005
・ FC Layerでdrop out 50%
・ 画像を256x256にResizeして、224x224 random crop と random horizontal flipping
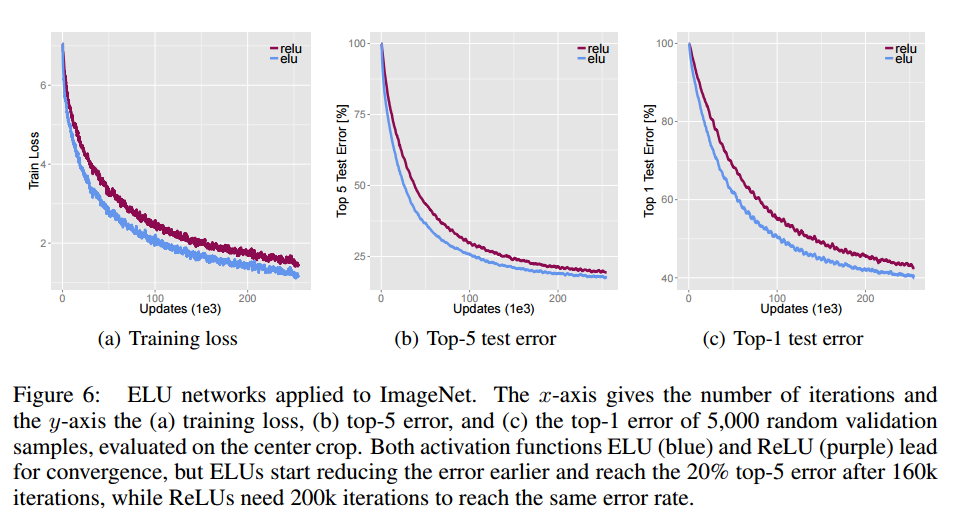
・ReLUと比較して収束も速く、Error Rateも低い
・ReLUと比較してELUは5%遅い
10k回に要する時間:ELUs 12.15h, ReLUs 11.48h
最後に
Batch Normalizationも平均0、分散1になるようにしているので、次のLayerでbias Shiftを軽減する効果がありそうです。
ELUとBatch Normalizationは効果がかぶっている部分があるのかな思います。
なので、併用してもそれほど効果がないと言うことなのかな?
一緒に使っても別に悪い影響は無いとは思いますが。
(On CIFAR-100 ELUs networks significantly outperform ReLU networks with batch normalization while batch normalization does not improve ELU networks.)