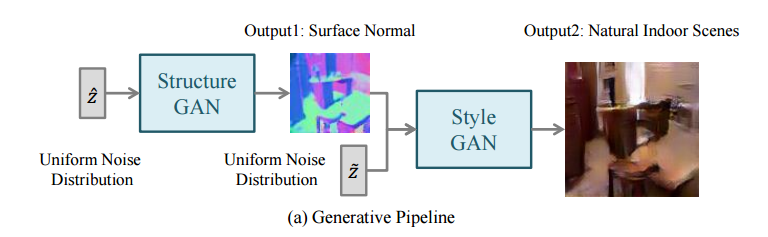
Generative Image Modeling using Style and Structure Adversarial Networks
DCGANで室内シーンのGenerative Modelを学習する問題に対し、従来より結果がRealかつ、高解像度かつ、結果が安定するように拡張を加えた論文です。
拡張の方向性としては以下の通りです。
- GANに入れるuniform noise データに加えてSurface Normalデータを入れる(Style-GAN)
- surface normalデータは別のGANにより生成する(Structure-GAN)
- さらにStyle-GANのGeneratorから生成された画像を入力としCNN(Fully Convolutional Network)にて、Surface Normalを再構成する
surface normalとは物体の表面の法線ベクトルのことです。
GAN(Generative adversarial network)は、generative modelを学習するframeworkです。GANでは2つの異なるモデルを同時に学習することでGenerative modelを得ます。
一つがuniform noiseデータからlatent random vector z(fakeデータ)を生成するGenerator $G$で、もうひとつはreal dataかGenerator Gが生成したデータか判定するDiscriminator $D$で、この相反する2つのモデルを交互に学習することでGenerative Modelが得られます。
Generative Adversarial Networks
batch size = Mとし、sample データ$X = (X_1, \dots, X_M)$、 uniform noise データを$Z=(z_1, \dots, z_M)$とします。
sample データは、real dataとGenerator Gにより生成されたデータを半々にしておきます。
Discriminator Dはrealデータをrealデータとして判定し、fakeデータをrealデータでは無いと判定した時にlossが小さくなるように学習します。
式で表すと下記のようになります。real dataのlabelは1で、fake dataのlabelは0です。
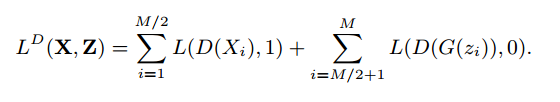
この時$L$はbinary entropyで下記のような式になります。
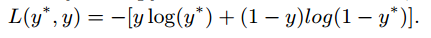
一方、Generator Gは、Discriminator Dにreal dataと思わせたいので、loss functionは下記のようになります。
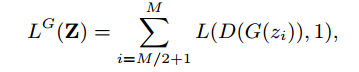
最適化するときは、Gを固定しDを最適化し、次にDを固定しGを最適化します。これを何度も繰り返します。
Structure GAN
Structure GANは100次元のuniform noiseデータ$\hat z$から72x72x3のsurface normalデータを生成します。
ネットワークの構造は下記の通りです。
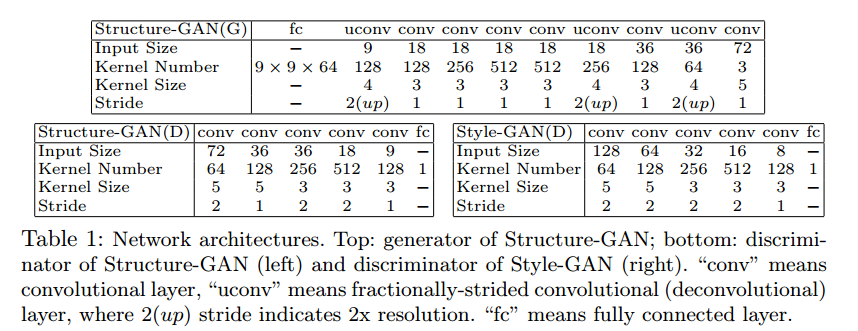
Generator
・100次元のuniform noiseデータ$\hat z$をfully connected layerで9x9x64にする
・uconvはfractionally strided convolutionまたはconvolution transposeでいわゆるdeconvolution言われている。
※deconvolutionはすでにinverse convolutionの意味ですでに使われていて名前として良くないので、convolution transposeとかfractionally strided convolutionと言われます。
・Batch Normalization使用
・Activation function: ReLU 最後のLayerはtanh
Descriminator
・6 layer (5 convolutional layer + 1 fully connected layer)
・Activatio function: LeakyReLU
・Batch Normalizationは使わない
Style GAN
GANのGeneratorとDiscriminatorの入力にsurface normalを追加したもの。
RGB image $X=(X_1,\dots,X_M)$, surface normal map $C=(C_1,\dots,C_M)$, uniform noiseデータ$\tilde Z=(\tilde z_1,\dots,\tilde z_M)$とすると、
Discriminator,Generatorはそれぞれ下記のようにする。
Discriminator $D(X_i) \rightarrow D(C_i,X_i)$
Generator $G(\tilde z_i) \rightarrow G(C_i,\tilde z_i)$
Discriminatorのloss function
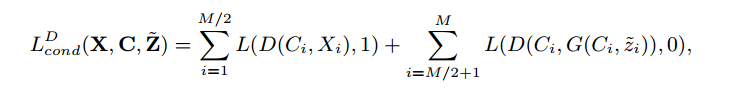
Generatorのloss function
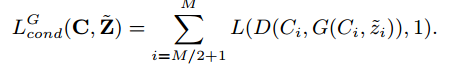
$C_i$が増えただけで基本的には変わっていない
Generator
Generatorはsurface normalと$\tilde z$を別々にConvolutionし途中で結合する。
下図の通り

・128x128x3のsurface normal mapは、2 layerのconvolutionを経て、32x32x128になる。
・100次元の$\tilde z$は、fully connected layerで8x8x64にして、fractionally strided convolutionで32x32x64になる。
・結合した後は上記の通りで最終t機には128x128x3 RGB imageになる
Discriminator
Structure GANとほとんど同じだが、入力がRGBとsurface normalを結合した6 channelになっている
Multi-task Learning with Pixel-wise Constractions
このままだと出力画像が、NoisyでEdgeがそろっていなかったり不自然なので、さらなる制約条件を追加する。
下図は制約条件を入れていない時の出力

この制約条件のアイディアは、「もし生成画像がRealならば、surface normal mapの再構成として使えるだろう」というところから来ています。
まず生成画像を入力としてFully Convolutional Network(FCN)に入れてsurface normal mapを推定します。
このときsurface normal mapはそのままの値ではなく、k-means clusteringで40 classに量子化したものを使用します。
loss functionは下記のようになります。
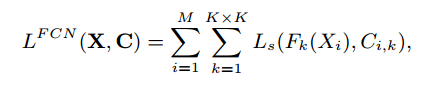
$L_s$はsoftmax lossで、surface mapの解像度は$K \times K$で$K=128$です。
$F_k(X_i)$はi番目の画像のk番目の画像のsurface normalの推定値です。$C_{i,k}$はそれに対応するlabelです。
FCNの学習には、RGBDデータを使用します。
FCN architecture
standardなAlexNetを使用しています。若干変更を加えていて、kernel数が1024と512の2 layer+最後にfractionally strided convolutional layer(stride=2)で大きくしています。最終的にはその出力をbilinearで4倍拡大したものを最終出力とします。
FCNはGeneratorの制約条件にします。
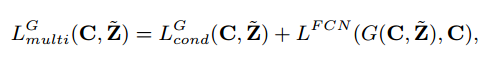
Trainingでは3つのstepを行います。
(a) Generator Gを固定し、Discriminator Dをoptimizeする
(b) FCNとDiscriminator Dを固定し、Generator Gをoptimizeする
(C) Generator Gを固定しFCNをfine tuneします
Joint Learning for S^2-GAN
Structure GANとStyle GANを別々にTrainingした後は、すべてのNetworkを統合して同時にTrainingします。
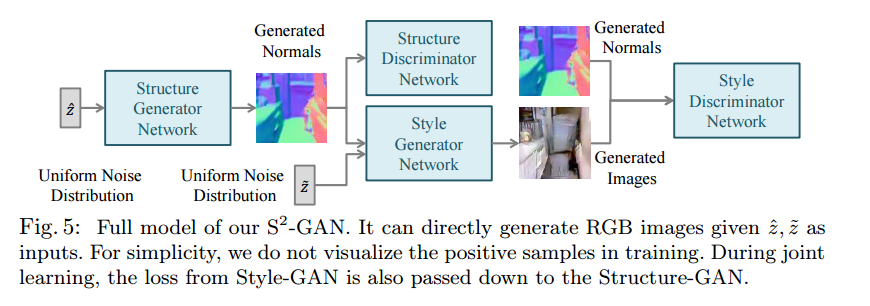
・Structure GANにより生成されたsurface normal mapはbilinearでupsamplingしてStyle GANに渡されます
・Ground truthのsurface normal mapは使わないのでStyle-GANの制約条件から外します
・Style GANのDiscriminatorにはfakeデータとして、生成したsurface normal mapと生成した画像、real dataとしてground truthのsurface normal mapとreal画像を与えます
・Structure GANのgenerator networkは、Structure GANのDiscriminatorの勾配だけでなく、Style GANのGeneratorの勾配も受け取ります。Structure GANのGeneratorのloss functionは下記のようになります。$\lambda=0.1$
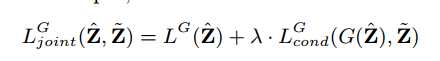
Experiments
実験パラメータの説明は割愛
Style GANにGround TruthのSurface normal mapを入力した時の結果

illumination、色、Textureのことなる画像が得られている。
pixel-wise constraintありとなしの比較

pixel-wise constraintが無いとnoisyで絵が不自然
Full Modelの結果

Walking the latent space
$\hat z$と$\tilde z$を徐々に変えた時の変化

Image Retrival
AlexNetに生成した画像と原画像を入れてPool5のFeatureを取り出す。AlexNetは5 convolutional layerなので、最後のConvolutionのあとのMaxPoolingの値(fully connected layerの前)をFeatureとしている。
FeatureをQueryにNearest NeighborでRetrivalした結果が下の図。

生成した画像のRealisticを評価
生成した画像を最新のClassifierとDetectorに入れてScoreが高ければRealityな画像が生成できているとする。
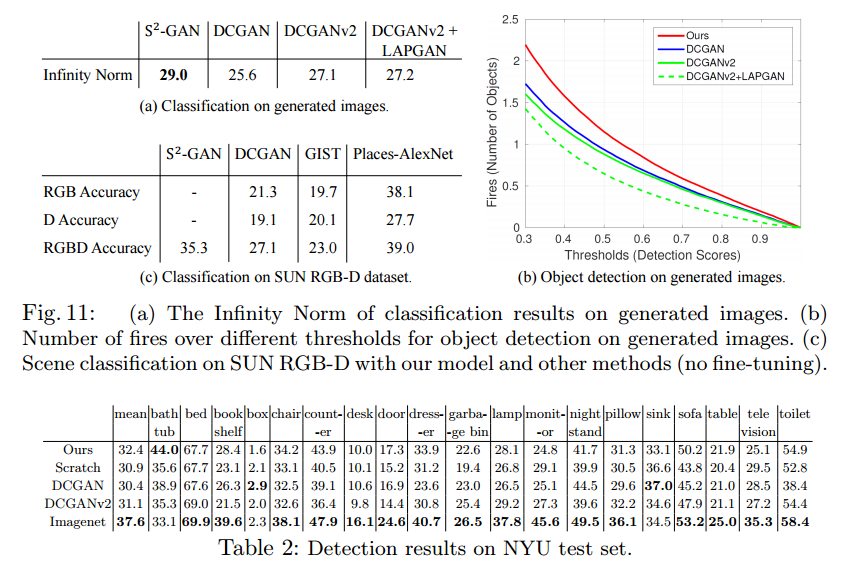
Classification
ClassifierにはPlaceデータで学習したAlexNetを使用。
もし画像がRealならば、どこか一つのクラスの反応だけが高くなるはずなので、infinity normで評価する。infinity normは要素の絶対値の最大値。
Detection
DetectorにはFast-RCNNを使用。
もし画像がRealならば、意味のあるObjectを沢山検出するはず。
(b)のグラフは横軸がobjectを検出したとするThresholdの値。小さければ甘めのThreshold。
縦軸は検出したObjectの数
Style GANのDiscriminatorのLayerの値をFeatureにしてScene ClassificationとDetectionに適応した結果
ClassificationではStyle GANのDiscriminatorのSecond LayerからLast LayerのFeatureを抽出してSVMで学習したものを使用。
Detectionではlast layerの後に4096次元の2 fully connected layerをつけて学習したものを使用。