スポーツ動画認識に関する論文
この論文の流れは、以下の通りです。
1. Convolutional Neural Networkは様々な問題、特に静止画、に適応されて成果を出してきた
2. 動画のClassificationに目を向けた時に、はたしてCNNの構造のままでいいのか?検討してみよう。
3. 動画のClassification用の大規模なDatasetの不足。自分たちでDataSetを作った。
4. 作成したデータ・セットに対して、CNNを用いた3つの異なる構造のNetworkで評価を行いました。転移学習も少々
1. Convolutional Neural Networkは様々な問題、特に静止画、に適応されて成果を出してきた
適応されている領域: Image Recognition、Segmentation、Detection、Retrieval
これらの結果は、数1000万のParameterを持つネットワークと学習を支える大規模なデータセットによってもたらされたものです。
2. 動画のClassificationに目を向けた時に、はたしてCNNの構造のままでいいのか?検討してみよう。
・静止画で高い性能を出してきたCNNをそのまま動画に適応してよいのか?
・動画なので複数フレームを処理しようとすると、学習に静止画以上に時間がかかるという問題がある
3. 動画のClassificationの大規模なDatasetの不足。自分たちでDataSetを作った。
大規模なデータ・セットはCNNの学習に必要だけど、動画のDatasetは集めるのも正解データを作成するのも大変だから、十分なものがなかった
Sports-1M Dataset:
1 million のSport動画をYoutubeから集めて、487のClassに分類した
正解データは動画についているText Metadataから自動で作成した。そのせいで正解データの質があまりよくない。
正解データの間違いの原因
・tag prediction algorithmのミス、または、tagが間違っている
・soccerのtagが付いているけど、soccerのplayシーンが無い動画
4. 作成したデータ・セットに対して、CNNを用いた3つの異なる構造のNetworkで評価を行いました。転移学習も少々
Time Information Fusion
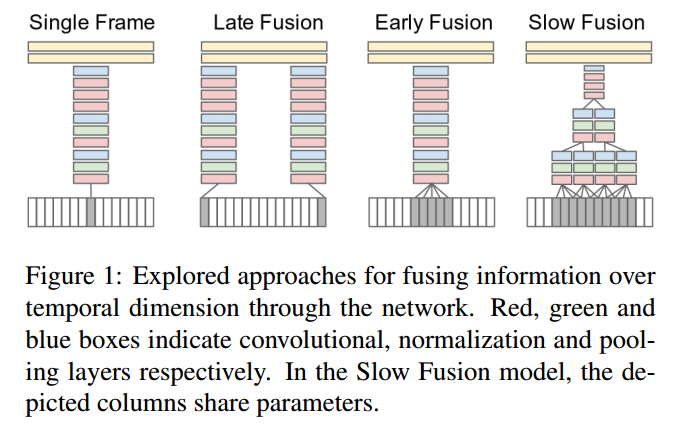
Single Frame
ベースとなるSingle Frameの構造
Input Size: 170x170x3
C(d,f,s)
d ... # of filters
f ... spatial size of filter
s ... stride
Arichitecture:
C(96, 11, 3)-N-P-C(256, 5, 1)-N-P-C(384, 3, 1)-C(384, 3, 1)-C(256, 3, 1)-P-FC(4096)-FC(4096)
下記を見るとわかりやすい。
ただし下の図はMultiresolutionを説明する図なので、細かいことは気にしてはいけない。
Red...C, Green...N, Blue...Pを表している
Early Fusion
Single FrameのFirst layerのConvolutionを11x11x3xTに拡張したもの。
TはFrame数で、10を使用
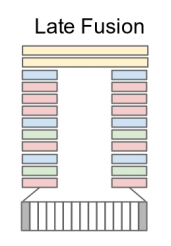
Late Fusion
15Frameの最初と最後のフレームを入力とした2つのC(256,3,1)までのCNNを最後Fully Connected Layerで結合したもの
Slow Fusion
Early FusionとLate Fusionの中間
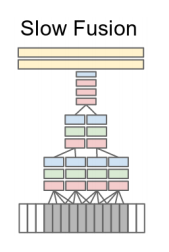
入力Frame数は、10Frame
First Convolutional Layerはそれぞれ4Frameを入力とする
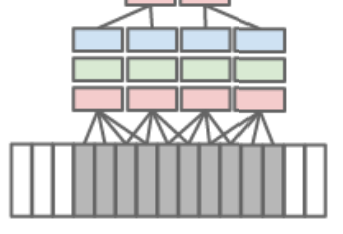
Second Convolutional Layerは2Frameを入力とする
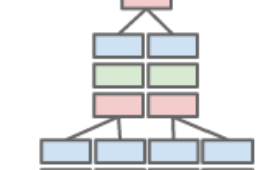
Third Convolutional Layerも2Frameを入力とする
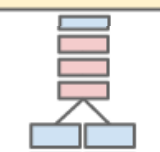
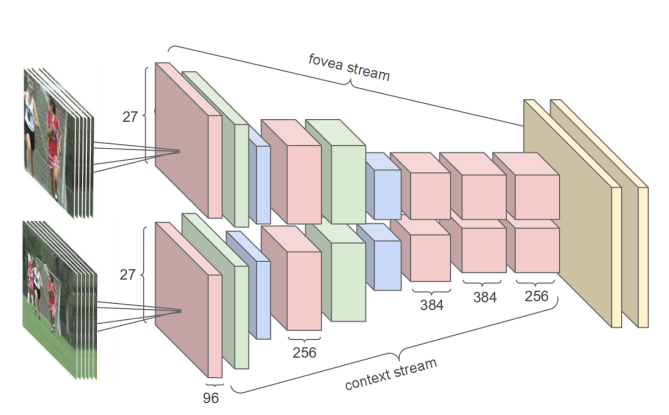
Multiresolution CNNs
速いGPUを使っても学習に数週間かかるので、性能を犠牲にしないで、学習のスピードアップをする必要ある。
方向性としては、Layer数と各LayerのNeuronの数を減らす
やったことは以下の通り
・入力の画像サイズを89x89にした。(178x178がもともとのサイズ)
・Low Resolution用(Context stream)とHigh Resolution用fovea stream)のMultiresolution CNNにした
・Low Resolutionの入力は178x178の入力をDownsamplingしたもの
・High Resolutionの入力は、178x178の中心89x89を切り出したもの
Learning
・minibatch size 32
・momentum 0.9
・weight decay 0.0005
・learning rate 0.0001
・data augmentation and preprocessing
動画の中心を切り出して、200x200にResizeして、170x170にRandom Samplingして、50%の確率でHorizontal Flipping、最後117を引く(117は全動画の平均値)
Experiments
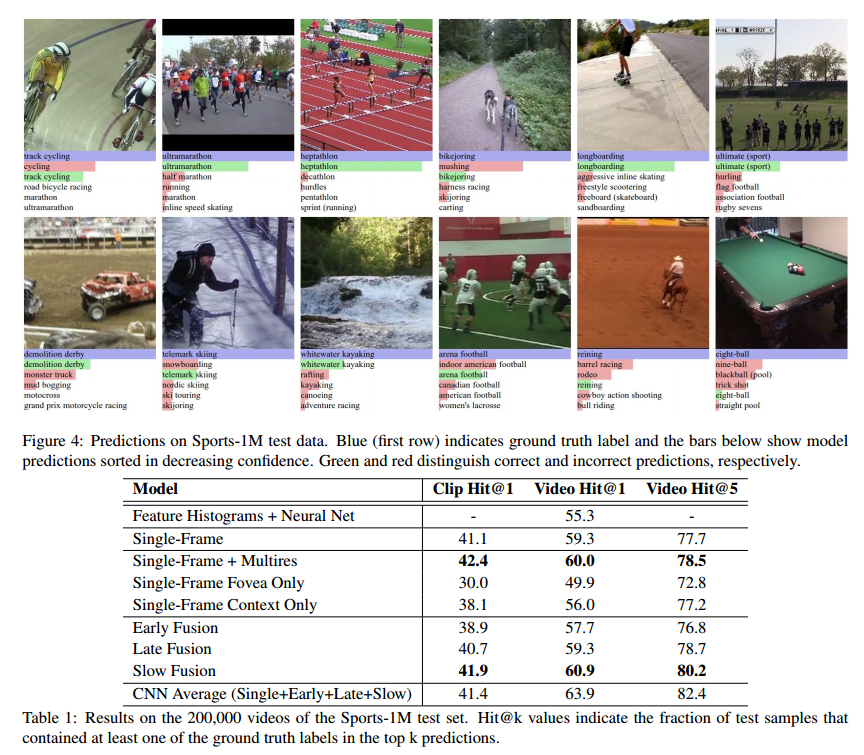
3つのArchitectureの中ではSlow Fusionが一番性能がよい
###動きを使った効果

Single Frame(上)とSlow Fusion(下)の比較
動きを使うと左3つのシーンでは正しく分類できている。ただしカメラモーションがあるとうまく分類できない(一番右)
Transfer Learning
Sports-1M datasetで学習した結果をUCF-101で評価した結果。
Fine Tuningとしていくつかのパターンを実施
・Fine-tune top layer: 最終Layerだけ再学習
・Fine-tune top 3 layers: 最終3Layersだけ再学習
・Fine-tune all layers: 全部のLayerを再学習
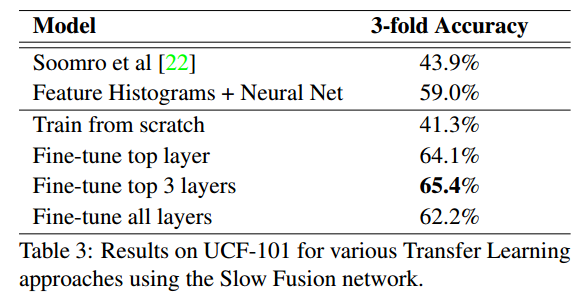
・Fine-tune top layerは、おそらくHigh Level FeatureがSportに特化していたためベストのPerformanceではなかった
・Fine-tune all layersは、Overfittingのためかも
・Fine-tune top 3 layersが一番バランスがよくBestなPerformanceになった
動画データの内容ごとに比較
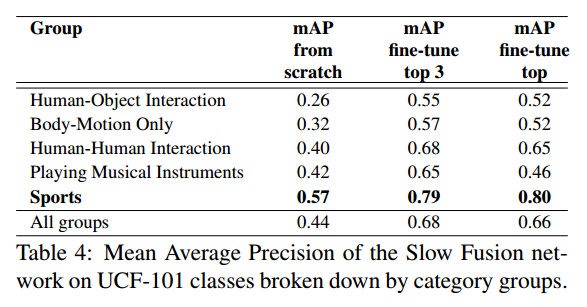
Sport以外のデータでは、より多くの層を再学習した方が性能がよい。
逆にSportのデータでは、最終層だけ再学習した方が性能がよい。