この論文は、depth estimation, surface normal estimation, semantic labelingの3つの問題を一つのmultiscale convolutional networkで扱うという論文です。
この論文自体は、これの前の論文"Depth Map Prediction from a Single Image using a Multi-Scale Deep Network"を拡張したものになっています。
Surface normal estimationは、物体の表面の法線方向を推定する問題です。(normalは垂直のという意味があるらしいです)

Semantic Labelingは、意味的に同じ物体表面をSegmentationしてLabelingするというものです。

Architecture
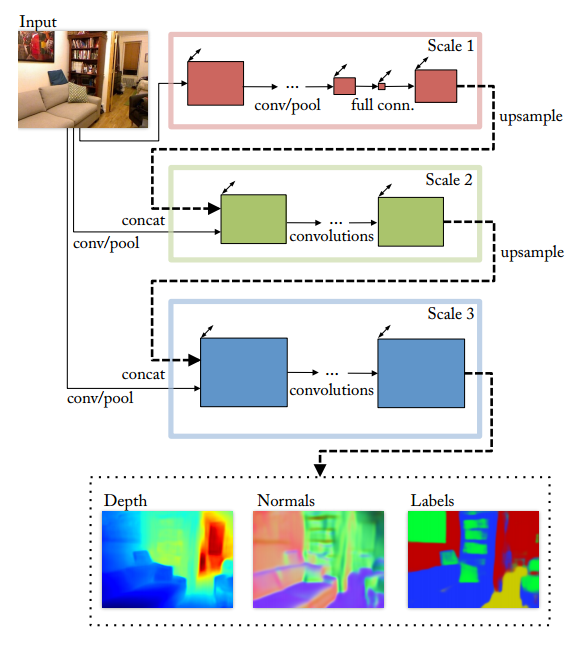
・depth prediction, surface normal estimation , semantic labelingを共通の一つのアーキテクチャで取り扱う
・Multi Scale Approachでpixel-wiseなMapを生成する
・3map出力の速度は、リアルタイム(〜30Hz)
・superpixelやcontourなどは使用しない
・前回からの拡張は、featureの抽出とRefineのために3 scaleのCNNを使用
・画像全体をみるcoarse scaleは、とくにdepthとnormalの推定で重要な役割
Model Architecture
Scale1: Full Image View
・粗く画面全体を推定するためのNetwork
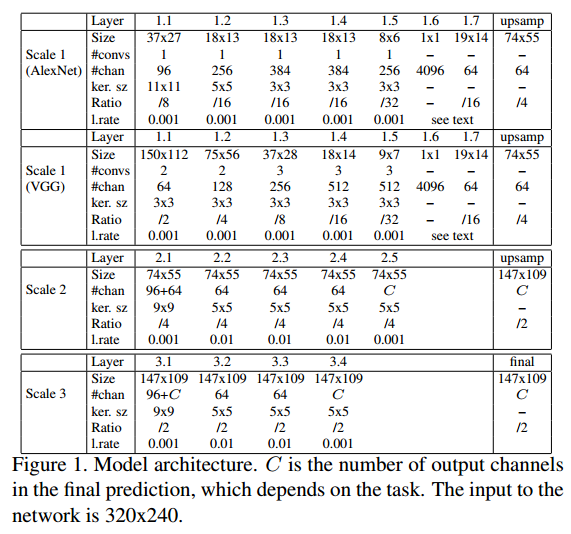
・2 fully connected layer
・最終のfully connected layerの出力を入力の1/16のサイズ、 64 featureにreshapeして4倍に線形upscaleして1/4にする
・初期値としてAlexNetとVGGを使った
Scale2: Predictions
・Scale2の役割は、精細だけど狭い範囲の画像とCoarse Networkの出力を用いて中解像度で推定すること
・出力サイズは74x55で、channel数はタスク依存とした
Scale3: Higher Resolution
・Scale3の役割は、推定MapをRefinementして、高解像度のMapを出力すること
・最終Layerの出力は入力画像サイズの1/2
Tasks
Task毎に異なるloss functionを使用します。
Depth
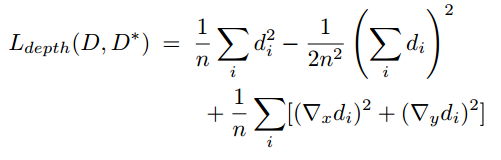
・$d=D-D^*$
・基本的には前の論文と同じ
・$\nabla_xd_i$と$\nabla_yd_j$の項を追加
・追加する前の式がscale invariant difference項
・追加したgradientの項は値が近くなるだけでなく、局所的な構造も似せる効果もある。
(差分の勾配が小さくなるので、正解データと突然かけ離れたりしないで差が一定に保たれる効果があると言うことだと思われる)
Surface Normals
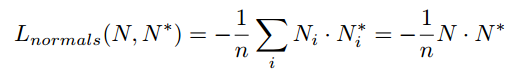
・ surface normalを推定するために、Depthでは1 channelだったけどsurface normalではx,y,zの3 channelにした
・ surface normalはl2ノルムで正規化する
・ surface normalは法線ベクトルなので、ベクトルの類似度を計算するために正解データとの内積をとっている。
Semantic Label
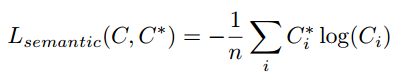
・ 画素のclass labelを推定する
・ その画素がどのLabelかをsoftmaxで出す(object recognitionと同じ、objectがlabelになっただけ)
・ softmaxで出した確率を使ってcross entropyをだしてlossにする
・ 入力には、NYUDepth RGB-D Datasetをlabelingするときは、groundtruthのdepthとnormalをRGBの他に使った
・ RGB,depth, normalそれぞれに32x9x9のfilterでconvolutionし、出てきた3つの結果を結合して、次のLayerの入力とした。
Training
Traningは2段階で実施:
- scale1, scale2の両方をトレーニング
- 1,2のパラメーターを固定して、scale3をトレーニング
・ここで、scale3はscale2に比べて4倍の画素数なので、トレーニングが大変だから、画像全体ではなく、74x55のサイズでRandom Cropする
・scale1, scale2を画像全体でforward propagationして、出力をupsamplingして、そこからcropしたものをScale3の入力とする。この時原画像も同じ場所をcropする。
・3タスクは同じ初期値、learning rateを使用。
設定の違いは
(i) normal taskのlearning rateはdepth, labelの10倍
(ii) 1.6. 1.7layerのlearning rateはdepth/normalで0.1, 0.1, semantic labelは0.1と0.01
(iii)1.6layerのdropoutはdepth/normal 0.5, semantic label 0.8
・Scale1のconvolutional layerはImageNetの値で初期化、full connected layerとScale2,Scale3のすべてのlayerはランダム
・batch sizeはalexNet初期化したモデルが32 ,VGG で初期化したモデルがメモリ制限のため16とした
・learning rateは2M step後に1/10,にして、追加で0.5M step学習した
5.2 Data Augmentation
・random scaling
・in-plane rotation
・translation
・color
・flips
・contrasts
Experiments
Depth
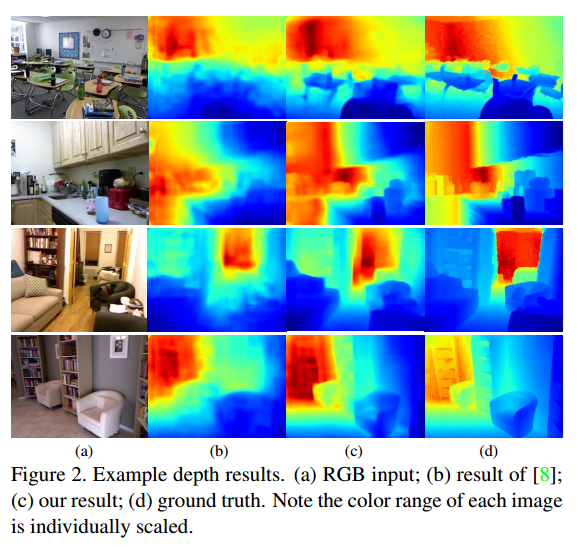
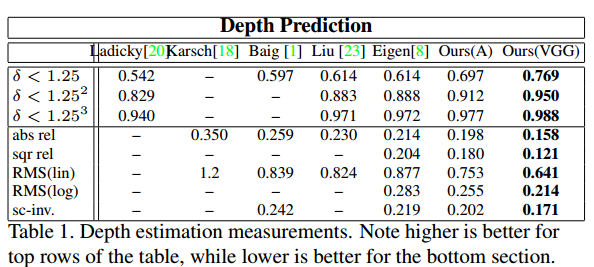
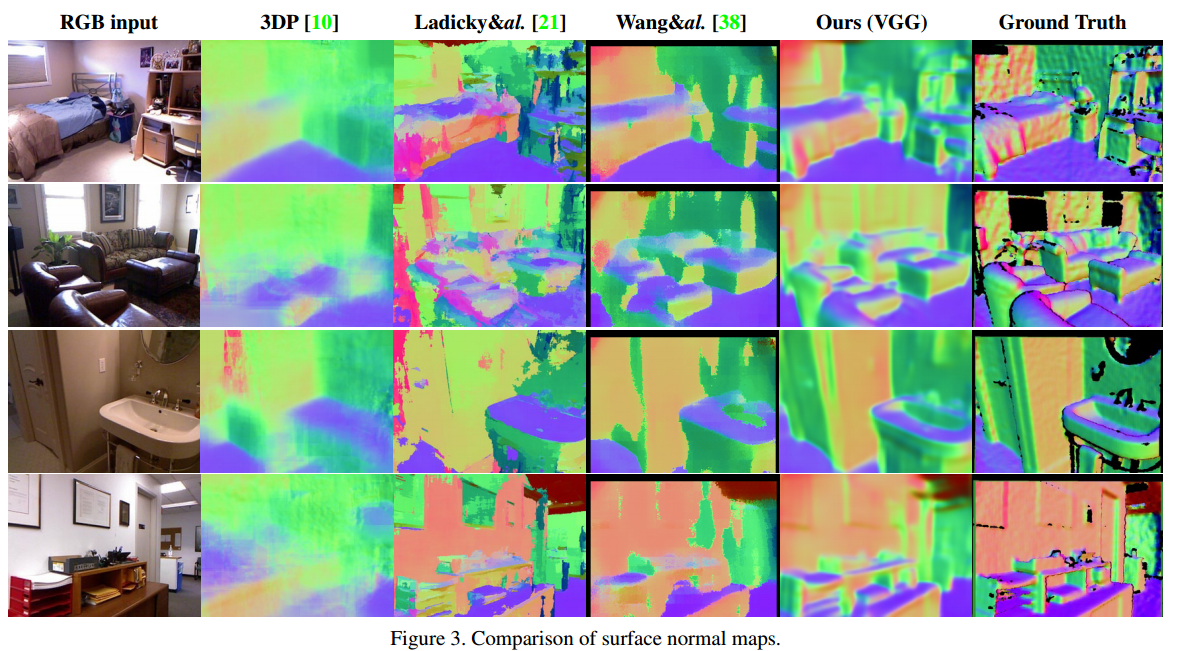
Surface Normals
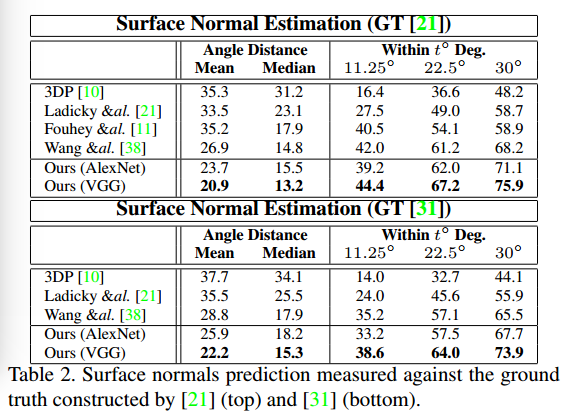
Semantic Labels
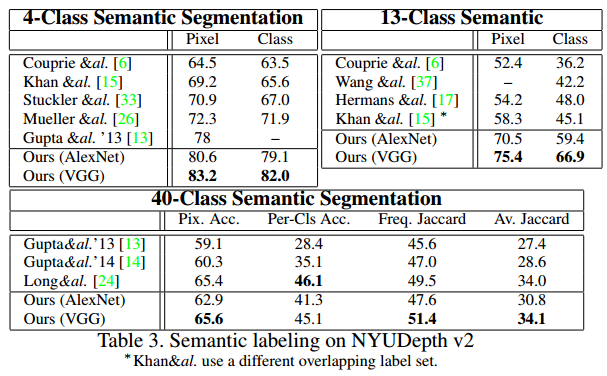
Semantic Labelは、4、13、40Labelで評価した
Sift Flow
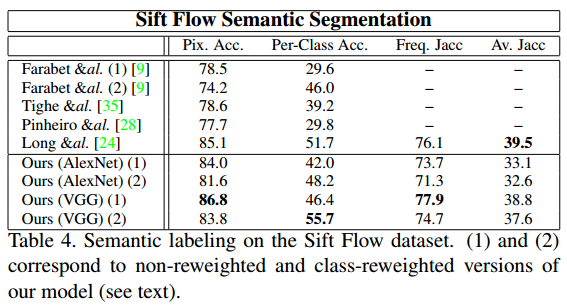
Sift Flow Datasetで試した結果
Pascal VOC
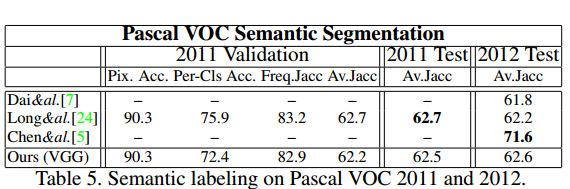
Pascal VOC Datasetで試した結果
Contributions of Scales
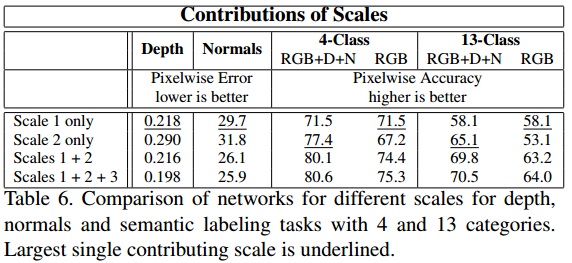
Single ScaleとMulti Scaleで性能比較
MutlScaleの方が良くなっている
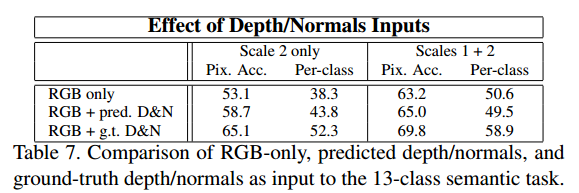
Effect of Depth and Normals Inputs
DepthとNormalsの推定値がSemantic Labelにどのくらい影響があるか調べた
DepthとNormalが推定値の時と、正解値を使った時で性能を比較