これはElastic stack (Elasticsearch) Advent Calendar 2016の20日目の記事です(ごめんなさい、一日遅刻の上に未完成です・・・)。
はじめに
Elasticsearch for Apache HadoopはElasticsearchとHadoopソフトウェアスタックを組み合わせて利用する幾つかのプロジェクトの集合です。よく使われている成果物としてHadoop等からElasticsearchを読み書きするelasticsearch-hadoopライブラリがあります。
他方でこれに比べるとマイナーなプロジェクトとしてYARN上でElasticsearchを実行するElasticsearch on YARNがあります。このプロジェクトは現在はまだベータであり、プロジェクトのホームページにはYARNは現状Elasticsearchのようなサービスを長期間実行するための包括的なサポートに欠けるとあります。
では、長時間実行「しない」Elasticsearchに使うとして、いったいどのような用途があるでしょうか?
一つの例として、「大きなデータを一気にインデックスするための一時的なElasticsearchクラスタ」をYARN上に構築する実験をしてみました。
関連技術
※Hadoop関連の知識がある方は次の章にスキップして下さい。
YARN
YARNとは現在のHadoopで用いられている、Hadoopクラスタ上で実行される各アプリケーションにCPUやメモリといったリソースを割り当てるリソース管理システムです。過去のHadoopではジョブマネージャ・タスクマネージャという仕組みを用いて各ジョブにリソースを割り振っていましたが、この仕組みは基本的にはMapReduce専用でした。
他方でHadoopクラスターをMapReduce以外のアプリケーショにも使いたいという需要が有り、それを受けて導入されたのがYARNです。YARN上ではMapReduceはもちろん、それ以外のアプリケーションもYARNクラスタ上に作成されたコンテナ内で実行することが出来ます。例えばHadoop MapReduceに代わる計算フレームワークとして注目されているSparkもYARNで管理されたクラスター上で実行することが出来ます。
この記事では、MapReduceやSparkのように、YARNクラスタ上でElasticsearchを実行してみます。
Amazon EMR (Elastic MapReduce)
EMRとはAmazon Web Service(AWS)上で提供されるマネージドなHadoop環境です。Hadoopを利用するにはまず必要な台数のマシンを用意してクラスタを構築し必要なソフトウェアをインストールするといった導入・管理コストの高さが問題でした。他方でEMRでは何も無いところから初めて必要な台数のEC2インスタンスの起動、クラスターの構成、基本的なHadoopソフトウェアの導入までウェブ上のインターフェイスで簡単に行う事が出来ます。
また幾つかの自動化機能も提供されており、Hadoopクラスターの起動後に指定されたジョブを自動的に実行したり、ジョブの終了後にクラスターを自動的にシャットダウンする事が出来ます。
EMRは常時稼働のHadoopクラスターを構築するのにも使えますが、クラスターの構築や破棄が簡単に行える事から、計算が必要な時だけ起動して使用後にはすぐ破棄する「使い捨てのHadoopクラスター」を使用するのにも適しています。
この記事では、EMRを用いて起動したクラスター上でインデックス専用の「使い捨てのElasticsearchクラスター」を構築してみます。
Elasticsearch on YARN
Elasticsearch for Hadoopのサブプロジェクトで開発されているElasticsearchをYARNクラスタ上のコンテナの中で実行するユーティリティーです。「YARNクラスタ上に必要な数のコンテナを作成し、その中でbin/elasticsearchを実行する」が主な機能となります。
他方で「bin/elasticsearchを実行する」以上のことは殆どしてくれません。例えばネットワーク設定やクラスター構成のためのディスカバリの設定はしてくれません(複数コンテナを起動する設定がある一方でディスカバリが提供されないのはちょっと驚きでした)。この辺りの設定は後述する手順で自分で行う必要があります。
実験
全体の流れ
今回行うのは、以下のように入力はS3上のデータ、出力はS3上に保存されたインデックスのスナップショットというワークフローです。

データをインデキシングするためEMRで構築したYARNクラスタ上でElasticsearchを起動し、そこに同じクラスタ上でSparkを実行してS3からElasticsearchへデータを投入します。ElasticsearchとSparkはインデックス作成中だけ実行し、スナップショットの出力後はYARNクラスタごと破棄します。
作成されたインデックスは他のElasticsearch(Elastic Cloudなど)へスナップショットをリストアする事で使用することが出来ます(今回は割愛)。
最終目標はこの一連の流れをボタンをポチッと押してしばらく待つとスナップショットが出来上がるように自動化することです。
YARNクラスタの起動
EMRのadvanced optionを用いて新しいクラスタを作成します。今回はHadoopディストリビューションとしてemr-5.2.0を選択し、ソフトウェアとしてはHadoop、Spark、クラスタの監視用にGanglia、対話的にSparkを使う環境としてZeppelinをインストールしました。
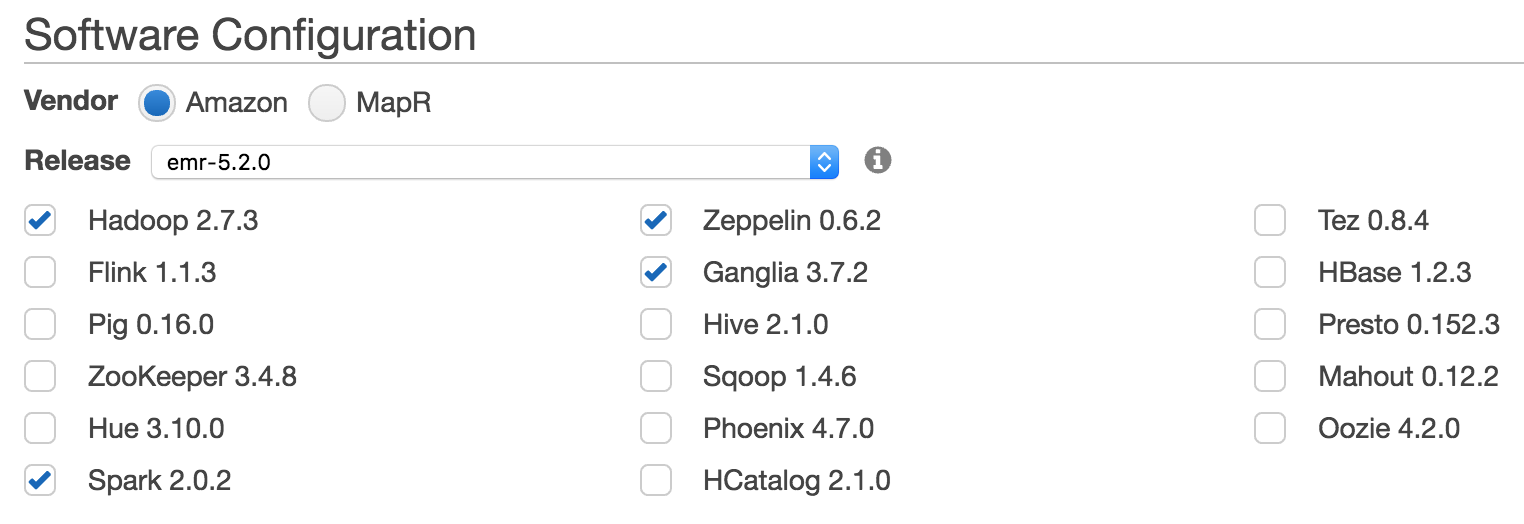
パラメーターのカスタム設定
YARN上でElasticserchを実行するにはEMRの標準の設定以外に次のパラメーターをカスタム設定する必要がありました。
YARNのyarn.nodemanager.vmem-check-enabledを無効に
YARN内でESを実行する場合にどうしても無効にする必要がありました。Software settingsに次のJSONを指定して無効に出来ます。
[
{
"classification": "yarn-site",
"properties": {"yarn.nodemanager.vmem-check-enabled":"false"}
}
]

ユーザーYARNのmmapとファイルデスクリプタの最大数を設定
Elasticsearchの起動時に事前チェックされますので、実行ユーザであるYARNに割り当てるこれらの最大数を各ノードの起動時に実行されるbootstrap actionを用いて設定します。
#!/bin/bash
sudo sysctl -w vm.max_map_count=262144
echo -e "yarn - nofile 65536\nyarn - nproc 65536" | sudo tee /etc/security/limits.d/yarn.conf > /dev/null
上記のシェルスクリプトを作成してS3上の適当な場所にアップロード、Bootstrap actionにcustom actionとして登録します。
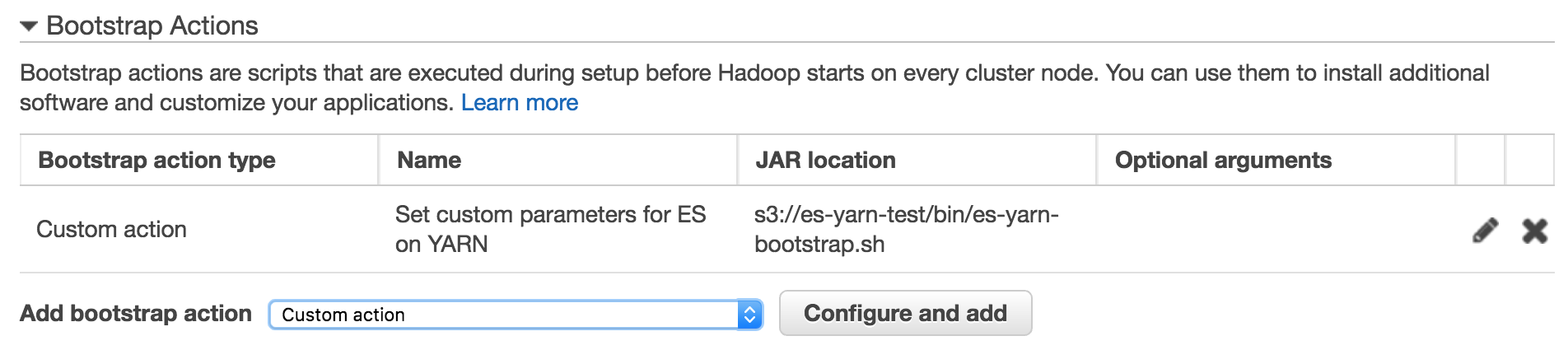
クラスタ構成用のタグを設定
今回の実験ではクラスタの構成のためにEC2ディスカバリープラグインを用います。Elasticsearchクラスターに参加するノードを特定するために適当なタグを設定します。今回はタグのキーとしてEsYarnClusterID、値としてtestを用いました。

以上でクラスタの設定は完了です。クラスタを起動します。
Elasticsearchの設定と起動
クラスターの起動後にマスターノードにSSH接続してElasticsearch on YARNのJARファイルをダウンロードします。このJARファイルはhadoopコマンドで実行可能なアプリケーションになっています。
# Maven centralからダウンロード
wget http://central.maven.org/maven2/org/elasticsearch/elasticsearch-yarn/5.1.1/elasticsearch-yarn-5.1.1.jar
# コマンドラインオプションの確認
hadoop jar elasticsearch-yarn-5.1.1.jar
No command specified
Usage:
-download-es : Downloads Elasticsearch.zip
-install : Installs/Provisions Elasticsearch-YARN into HDFS
-install-es : Installs/Provisions Elasticsearch into HDFS
-start : Starts provisioned Elasticsearch in YARN
-status : Reports status of Elasticsearch in YARN
-stop : Stops Elasticsearch in YARN
-help : Prints this help
Elasticsearchの設定
Elasticsearch on YARNはESの配布パッケージ(elasticsearch-x.x.x.zip)からElasticsearchを起動します。プラグインを使用したりelasticsearch.ymlに必要な設定を書き込むためにカスタムの配布パッケージを作成する必要があります。
まず-download-esコマンドをつかって配布パッケージをダウンロードします。現在のElasticsearch on YARNにはバグがあるらしくダウンロード元を明示的に指定する必要があります。
hadoop jar elasticsearch-yarn-5.1.1.jar -download-es download.es.url=https://artifacts.elastic.co/downloads/elasticsearch/
ダウンロードされた配布パッケージは~/downloads以下に保存されます。次にこれを解凍し、必要なプラグインのインストールや設定の編集を行います。今回はクラスタ構成とスナップショット作成に必要なプラグインの導入と最小限の設定を行います。
# ZIPファイルの解凍
cd downloads
unzip elasticsearch-5.1.1.zip
# EC2ディスカバリープラグインのインストール
./elasticsearch-5.1.1/bin/elasticsearch-plugin install discovery-ec2
# S3リポジトリのプラグイン
./elasticsearch-5.1.1/bin/elasticsearch-plugin install repository-s3
# 設定の編集
vi elasticsearch-5.1.1/config/elasticsearch.yml
network.host: _global_
# AWSリージョンの設定
cloud.aws.region: us-west-2
discovery:
# EC2ディスカバリの使用
zen.hosts_provider: ec2
ec2:
# EMRのスレーブノードを検索
groups: ElasticMapReduce-slave
# 事前定義したタグでフィルタリング(タグの値は環境変数を用いて起動時に設定)
tag:
EsYarnClusterId: ${ES_YARN_CLUSTER_ID}
以上の変更が完了したら同名のZIPファイルとしてアーカイブし直します。
rm elasticsearch-5.1.1.zip
zip -r elasticsearch-5.1.1.zip elasticsearch-5.1.1
cd ..
Elasticsearchの実行に必要なファイルのHDFSへの配置
YARN上でアプリケーションを実行するのに必要なリソースは事前にHDFS上に配置する必要があります。これは-installと-install-esコマンドで行う事が出来ます。
# Elasticsearch on YARNのJARファイルをHDFS上へコピー
hadoop jar elasticsearch-yarn-5.1.1.jar -install
# ./downloads以下のESの配布パッケージをHDFS上へコピー
hadoop jar elasticsearch-yarn-5.1.1.jar -install-es
Elasticsearchの起動
お疲れ様でした。これでようやくElasticsearchをYARN上で実行する用意が出来ました。実行は-startコマンドで行います。沢山オプションが必要です。
hadoop jar elasticsearch-yarn-5.1.1.jar -start \
am.mem=256 containers=3 container.vcores=4 container.mem=8192 \
env.ES_JAVA_OPTS="-Xm6g -Xmx6g" \
env.ES_YARN_CLUSTER_ID="test"
-
am.mem=256アプリケーションマスタに256MBを割り当て。デフォルトの64MBでは足りませんでした。 -
containers=3今回はスレーブノードが3台のクラスタを使用したため、各スレーブノードにコンテナを1つ、計3つを作成しました。 -
container.vcores=4 container.mem=8192各コンテナにCPU4つとメモリ8GBを割り当てます。 -
env.ES_JAVA_OPTS="-Xm6g -Xmx6g"ESに固定量のヒープメモリを割り当てるお馴染みの環境変数設定です。やや余裕を持ってコンテナに割り当てたメモリ量より少なめの値を指定するのがお薦めです。 -
env.ES_YARN_CLUSTER_IDクラスタ構成用のタグの値です。前のステップで編集したelasticsearch.ymlから参照されます。
起動に成功すればYARNのResource Manager上でElasticsearchが実行中なのが確認出来ると思います。

サンプルデータのインデキシングとスナップショット作成
今回はサンプルとして世界の様々な出来事を時系列データとしてまとめたGDELT Event Databaseをelasticsearch-sparkライブラリを使ってESに取り込んでみます。
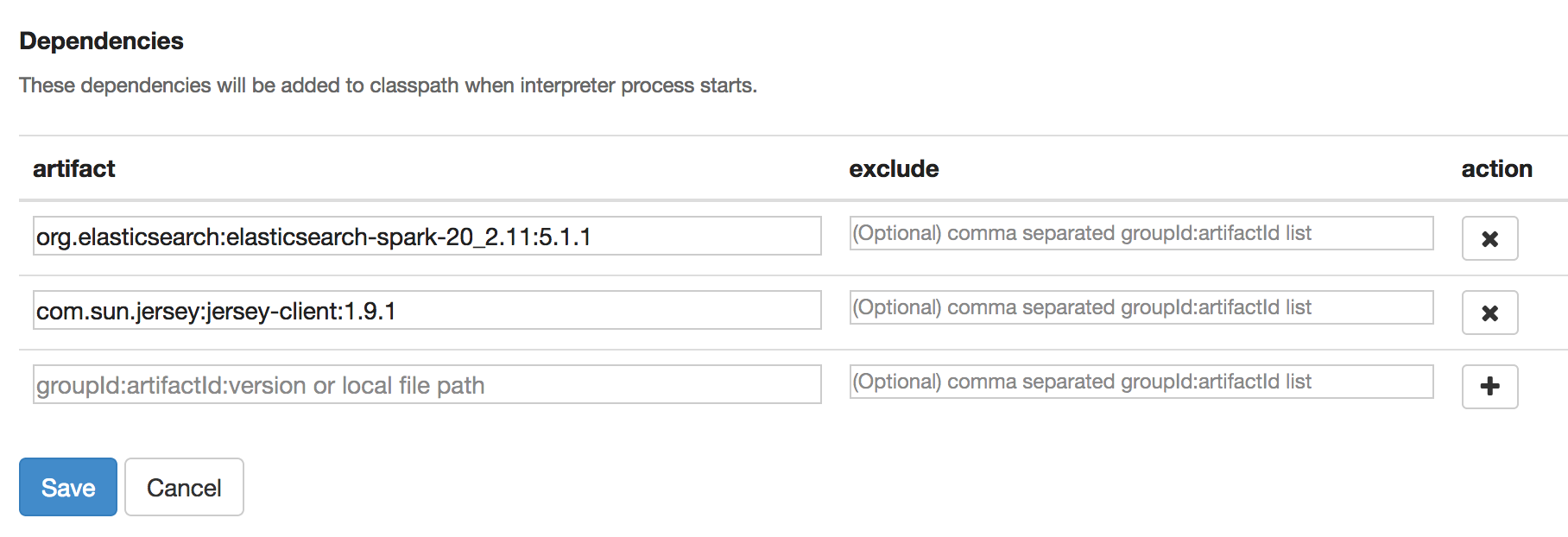
自動化の前にZeppelinの対話環境を使ってインデキシングを試してみます。まずEMRのクラスター情報ページからZeppelinを起動して、右上のanonymous -> Interpreterと選択し、Spark interpreterの設定を編集し以下のdependencyを追加します。
- org.elasticsearch:elasticsearch-spark-20_2.11:5.1.1
- com.sun.jersey:jersey-client:1.9.1 (YARN clientを使用するのに必要)
新しいノートブックを作成し、S3上で公開されたCSVファイルから2016年11月分のデータの一部の項目についてDataFrameを作成します。
import java.text.SimpleDateFormat
// スキーマをcase classとして作成
case class Event(
id:Long, date:java.sql.Date,
a1Code:String, a1Name:String, a1Country:String, a1Group:String,
a2Code:String, a2Name:String, a2Country:String, a2Group:String,
url:String)
// 2016年11月分のCSVファイル(s3a://gdelt-open-data/events/201611*.csv)を読み込み
// 作成したcase classにマップ
val events = spark.read
.options(Map("quote"-> null, "sep" -> "\t"))
.csv("s3a://gdelt-open-data/events/201611*.csv")
.map(r => Event(
r.getString(0).toLong, new java.sql.Date(new SimpleDateFormat("yyyyMMDD").parse(r.getString(1)).getTime),
r.getString(5), r.getString(6), r.getString(7), r.getString(8),
r.getString(15), r.getString(16), r.getString(17), r.getString(18),
r.getString(57))
)
events.createOrReplaceTempView("events")
作成したDataFrameはcreateOrReplaceTempViewを用いてSQLコンテキストに登録することでSpark SQLを使って操作できるようになります。
%sql
SELECT * FROM events
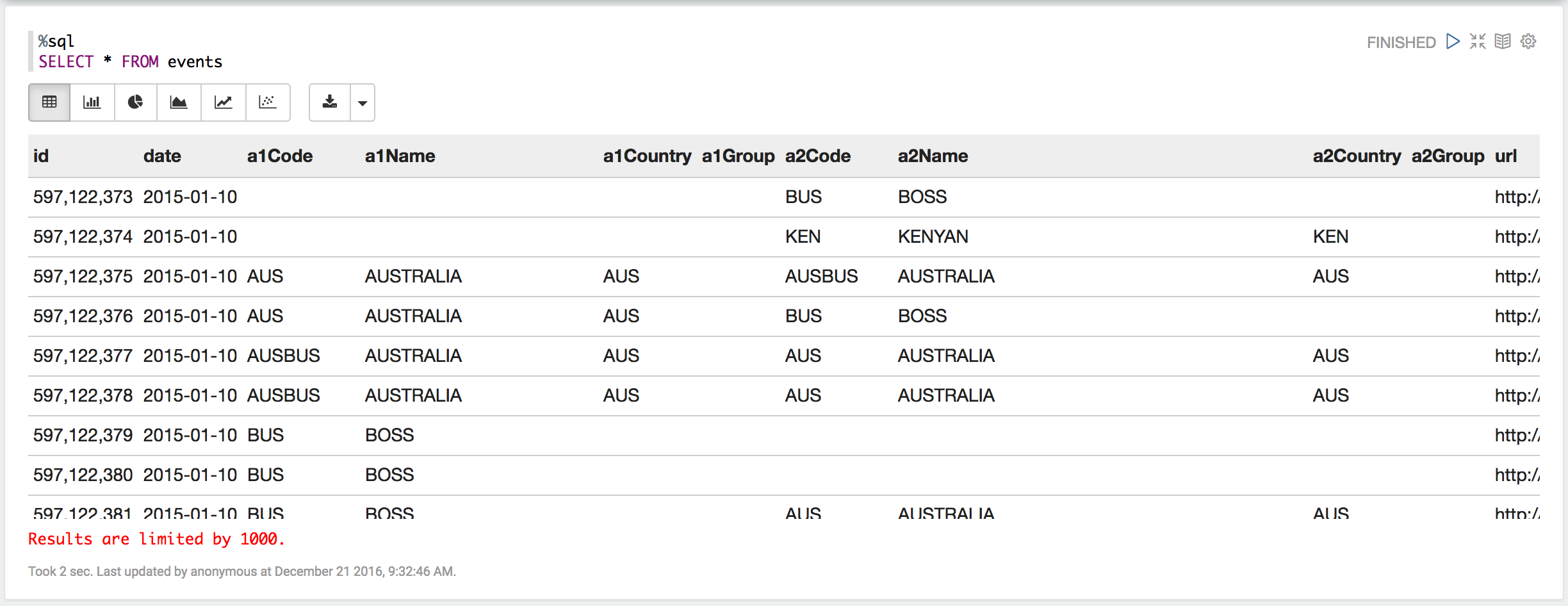
(本当は他のデータセットと結合したりネストしたJSONを作成したりとSpark SQLはESへの投入データを作成するのに大変便利なのですが今回は省略・・・)
SQLで確認したデータが良いようであれば早速インデキシングです。まずYarnClientを使ってElasticsearchの各ノードのホスト名を取得します。
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.yarn.api.records.YarnApplicationState
import org.apache.hadoop.yarn.client.api.YarnClient
import scala.collection.JavaConversions._
// YarnClientの作成
val yarn = YarnClient.createYarnClient()
yarn.init(new Configuration())
yarn.start()
// YARN上で実行中のElasticsearchを取得
val es = yarn.getApplications()
.filter(a => a.getApplicationType == "ELASTICSEARCH")
.filter(a => a.getYarnApplicationState == YarnApplicationState.RUNNING)
.head
// Elasticsearchを実行しているコンテナのIDを取得
val nodeIds = yarn.getContainers(es.getCurrentApplicationAttemptId)
.map(c => c.getAssignedNode)
.distinct
// 各コンテナを保持するノードのホスト名を取得
val hosts = yarn.getNodeReports()
.filter(n => nodeIds.contains(n.getNodeId))
.map(n => n.getHttpAddress.split(":", 2)(0)) // ポート名を削除
ホスト名が取得出来たらインデキシングしてみます。DataFrameのsaveToEsメソッドを呼ぶとSparkが複数のExecutorを起動しESへ並列にバルク書き込みを行います。
import org.elasticsearch.spark.sql._
val esConf = Map(
"es.nodes" -> hosts.mkString(","), // ノードのホスト名一覧(カンマ区切り)
"es.batch.size.bytes" -> "10mb", // Batch indexingのバッチサイズ (10MB)
"es.batch.size.entries" -> "0" // Batch indexingの各バッチの最大レコード数(無制限)
)
events.saveToEs("gdelt/event", esConf) // インデキシング (インデックス名/タイプ名, 設定)
インデキシングが終わったらスナップショットをS3に書き出してみます。まず予めインストールしたS3 Repository Pluginを使用してS3上にリポジトリを作成します。これは取得したノードの一つにレポジトリ設定をPUTする事で行います。
import org.apache.http.client.methods.HttpPut
import org.apache.http.entity.StringEntity
import org.apache.http.impl.client.HttpClients
val client = HttpClients.createDefault()
val repoUri = s"http://${hosts.head}:9200/_snapshot/s3"
// S3上にスナップショットレポジトリを作成
val createRepo = new HttpPut(repoUri)
createRepo.setEntity(new StringEntity("""
{
"type":"s3",
"settings":{
"region":"us-west-2",
"bucket":"es-yarn-test",
"base_path":"/snapshots"
}
}
"""))
client.execute(createRepo)
次にスナップショットを作成します。これも取得したノードの一つにPUTリクエストを送る事で行います。
// スナップショット名
val snapshotName = "gdelt_201611"
val snapshotUri = s"$repoUri/$snapshotName"
// スナップショットを作成
// (wait_for_completion=trueを指定して作成終了まで処理をブロック)
val createSnapshot = new HttpPut(snapshotUri + "?wait_for_completion=true")
client.execute(createSnapshot)
自動化
・・・工事中・・・