細かい設定は無視して、とりあえず並列分散処理環境を作ってアプリを動かしてみたい人用まとめ。という名の自分用メモ。
インフラ屋さんよりアプリ屋さん向けです。
想定
- Linux上で分散処理環境を実現するHadoopを導入する。
- 分散処理フレームワークであるMapReduceのサンプルアプリが動くことを確認する。
- 1台のPCで擬似的に分散処理する「擬似分散モード」で構築します。
注)今回はHadoopのバージョン1系です
準備
Windows8.1付属のHyper-VにてCentOS7を構築して試します。
(参考までに)最小限インストールで互換性ライブラリと開発ツールを追加しました。
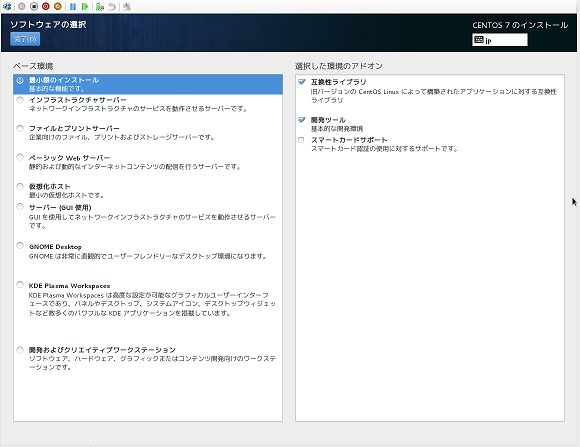
以下の2つのrpmをダウンロードしておきます。
ユーザの設定
CentOS7インストール時にrootと一般ユーザ(userとする)が設定できるので設定。
sudoしたいのでuserをwheelグループへ。
usermod -G wheel user
id user #確認
JDKのインストール
おもむろにrpmでインストールします。
sudo rpm -ivh jdk-8u25-linux-x64.rpm
java -version #動作の確認
Hadoopのインストール
またもrpmでインストールします。
sudo rpm -ivh hadoop-1.2.1-1.x86_64.rpm --force
非常に楽。
Hadoop各種XML設定
core-site.xml
ファイル分散のためのファイルシステムHDFS関連の設定を記述
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoop</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hadoop.tmp.dirでデータ保存領域を指定します。デフォルトだと/tmpの下に作られるので注意。
fs.default.nameではNameNodeを設定するところですが、1台で構築擬似分散なのでlocalhostで大丈夫。
hdfs-site.xml
レプリケーションの設定。1で。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
Hadoop起動
HDFS領域のフォーマットを行って、読み書きの準備をします。
まずhadoopのrpmをインストールするとhdfsユーザが作られています。このユーザでフォーマットを行います。(rootではフォーマット実行できないので注意)
sudo passwd hdfs #パスワード設定
・・・
su - hdfs
/etc/init.d/hadoop-namenode format #フォーマット実行
必要なデーモンを起動します。1つずつ確認。
/etc/init.d/hadoop-namenode start
/etc/init.d/hadoop-datanode start
/etc/init.d/hadoop-jobtracker start
/etc/init.d/hadoop-tasktracker start
HDFS領域をだれでも書き込めるようにしておきます。これもhdfsユーザで。
hadoop fs -chmod 777 /
サンプルアプリ実行
今回、wordcountというサンプルを動かします。名前の通り単語の数カウントです。
テスト用の入力ファイルを作ります。
aaa aaa bbb a vbbbb dccc aa baa aaa
ddd gg bbb aaa aaa bbb a vbbbb dccc aa baa aaa ddd gg bbb
こんな感じ。準備出来たら早速実行。
hadoop fs -put input.txt . #HDFS上にファイルをコピー
hadoop fs -rmr output #出力先をクリア
hadoop jar /usr/share/hadoop/hadoop-examples-1.2.1.jar wordcount input.txt output
hadoop fs -cat output/part-r-00* | sort -t $'\t' -n -k2,2 -r > out.csv
hadoop-examples-1.2.1.jar wordcount [入力ファイルorディレクトリ] [出力先]
です。
最終行は出力結果を結合して単語数順にソートして持ってきているだけです。
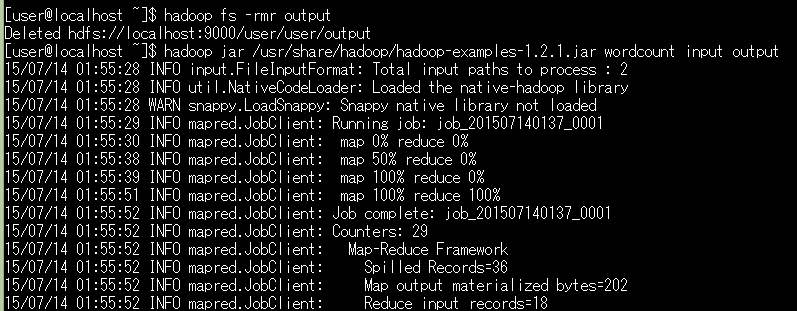
こんな感じにmapとreduceが100%になると正常動作しています。
最後のout.csvはこんな感じに出力されています。
[user@localhost ~]$ cat out.csv
aaa 6
bbb 4
vbbbb 2
gg 2
よーし、動いた。
設定おまけ
mapとreduceの並列処理数を設定したい場合以下の項目で設定できます。
<configuration>
<property>
<name>mapred.tasktracker.map.tasks.maximum</name>
<value>2</value>
</property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximum</name>
<value>2</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>10</value>
</property>
<property>
<name>mapred.reduce.tasks</name>
<value>10</value>
</property>
</configuration>