さあ、vte.cx engine(ブイテックスエンジン)のadvent calendarが始まりました。
これから25日間、余すところなく記述していきますので、よろしくお願いいたします。
BaaSの現状とvte.cx
ところで皆さん、BaaSってご存知ですか?
知っているけれども機能が不十分だしなんとなく使えない、ベンダーロックインが心配など、いろいろな理由があってまだ使っていないという方がほとんどではないでしょうか。
はっきりいってBaaSは今幻滅期にあると思います。
数年前まではこぞって新しいBaaSがでてきていたのですが、今ではあまりいい話を聞きません。USでは胡散臭くなるという理由でBaaSという言葉自体、あまり使わないようにしているとのことです。
そうなってしまったのは、一言でいえばベンダーが中途半端なものしか提供してこなかったからだと思っています。次節でも述べますが、何でもかんでもAPIにして、あまり深く考えないで公開してきた結果といえなくもない。でもそんなことしたら後でユーザが苦労するのはわかりきっていますよね。

vte.cxは後発ですが、おそらく最も早くから開発が始まったBaaSだと思います。
ReflexWorksを基盤としているので、その開発期間を合わせると5〜6年はかかっています。
ReflexWorksはオンプレミス向けですが、あるお客様のミッションクリティカルなWebアプリケーションで、600tps(※)という高スループットのトランザクション処理を捌いています。平均レスポンスは100ms以下です。
つまり、それだけの実績があるBaaSだということです。
(※)APIリクエスト数なのでDBに換算したらその10倍以上になると思います。

SPAがよい理由
話は変わって、Webアプリケーションのアーキテクチャーについて。
今、SPA(Single Page Application)というアーキテクチャーが注目されています。
これは、優れたUI/UXを提供することを目的とする1つのWebページで提供されるアプリケーションです。
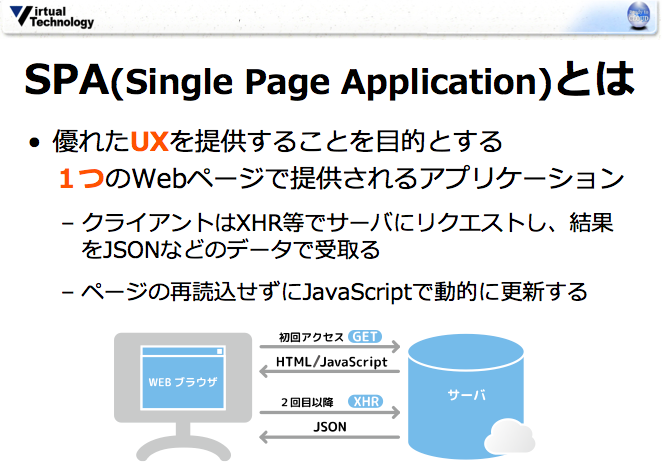
SPAではサーバサイドではレンダリングをせずAPIによってデータだけを返します。
それは、サーバーでHTMLを生成するよりもクライアントで動的に画面を更新する方が効率的だからです。
また、ユーザーの操作に応じてインタラクティブに動くリッチクライアントを実現できます。

APIもフロントエンドで開発する
では、HTML、CSS、JavaScriptなどのフロントエンドコーディングだけでWebシステムを作れないものでしょうか?
そうすれば、フロントエンジニアだけでWeb開発できるようになり、開発者はUI/UXなどクリエイティビティな作業に集中できるようになります。また、短期間で開発しなければならないようなプロトタイプ作りの要求にも応えることができます。
SPAにすることでコードの大部分をフロントエンドに持ってくることができます。
しかし、依然としてAPIはサーバ側にあります。
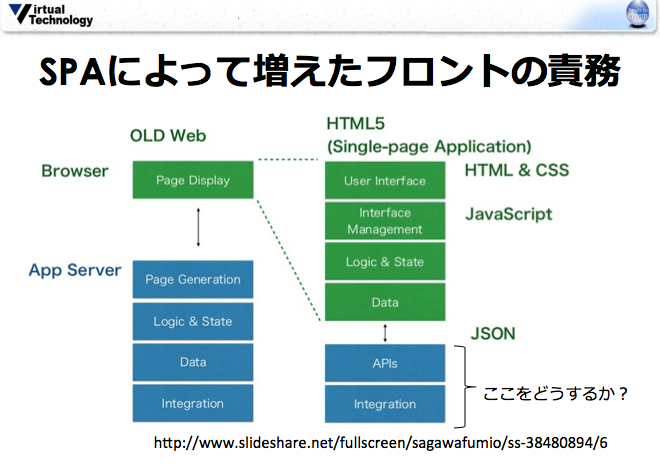
サーバサイドでAPIを実装するのは大変です。サーバの導入・設定、テーブルの設計、O/Rマッピングの設計等々、やるべきことがたくさんあります。
そこで私たちはサーバサイドのAPIもフロントエンジニアが自由に作れるようなBaaSを作ることを考えました。
それが、vte.cxです。
ベンダーロックインのリスクを回避するために
世の中には様々なBaaSが存在しますが、APIが固定的であることが多いように思います。
APIの仕様がきちんとしていればフロントエンジニアが開発するのは難しいことではありませんが、怖いのはベンダーにロックインされてしまうことです。
ロックインの弊害はベンダーに依存してしまうことだけではありません。
既存のアプリケーションへの影響を与えたくないという理由からベンダーは大きな仕様変更ができなくなります。つまり、機能改善がなかなか進まないという状況に陥り、負の遺産を抱え込んだ状態になります。
vte.cxでは規約に基づいたREST操作がすべてです。固定のAPIはありません。
またSDKライブラリを提供していないのでベンダーロックインの心配はありません。
vte.cxは、これまでの「バックエンドAPIを提供することだけに特化している」というBaaSの概念を覆す、極めて自由度の高いBaaSです。
ロックインについては、新BaaS論 ~ロックインされない仕組みを考える~ で詳しく述べていますのでぜひご覧ください。
URIとスキーマの設定だけでAPIを作る
vte.cxではフロントエンジニア自身がAPIを作成することを前提にしています。
サーバサイドのビジネスロジック実装やテーブルの設計はこれまでバックエンドエンジニアの仕事でしたが、これらすべてをフロントエンジニアの手によって実装してしまおうというのがvte.cxの考え方です。
そもそもSPAではビジネスロジックの大部分をクライアントサイドで実装します。
vte.cxでは一部のサーバサイドで実装すべきロジックについてはサーバサイドJavaScriptによって実装できますが、サーバサイドのAPIが既にあることが前提で開発することが多いフロントエンジニアに、いきなりAPIを作れといって戸惑うかもしれません。また、これは実質的にサーバサイドを作らされているのと同じ意味であり大きな負担であることは間違いありません。
しかし、vte.cxにおいては、URIとスキーマだけを設定すればAPIが作成できるため、ゼロからサーバサイドを立てるよりはるかに楽なはずです。
vte.cxではテーブルの設計は必要ありませんが、その代わり、スキーマ設計を行う必要があります。
スキーマは画面の項目をそのままスキーマの項目に落としていけばよく、RDBのテーブル設計に伴う正規化などは一切考える必要はありません。正規化が必要ないのはデータベースにNoSQLを採用している強みといえるでしょう。
メタデータとATOM
API設計の話の前にメタデータについて少し触れておきます。
メタデータは一般のデータとは区別され、例えば、データのid、ACL、更新日時、ページネーションのnextlinkなどを表現するために使われます。
JSONのメタデータ表現は様々なものがありますが標準的なものはまだありません。
vte.cxでは古くからXMLでよく使われているATOM feedを採用しており、title、subtitle、summary、rights、linkなどのATOM項目をメタデータとして利用しています。また、ATOM標準項目以外にもユーザ定義項目をスキーマにより自由に定義することができます。詳しくは、ATOM項目とユーザ定義項目を参照してください。
URI設計の実際
vte.cxのAPI設計はURIとスキーマだけを設計すればいいことを述べました。
URIの設計ではエンドポイントとなるURIを決めてそのエントリーを作成するだけです。
例えば、/_html/server というエンドポイントを決めたらそのエントリーを登録します。登録はHTTP(s)のPOSTかPUTでできます。
以下はvtecxblankプロジェクトのsetupフォルダにある/_html/serverエントリです。
これはデプロイ時に実際にPUTされます。(ちなみに以下のエントリはxmlですがjsonでも表現できます)
<feed>
<entry>
<contributor>
<uri>urn:vte.cx:acl:/_group/$admin,CRUD</uri>
</contributor>
<contributor>
<uri>urn:vte.cx:acl:+,R.</uri>
</contributor>
<link rel="self" href="/_html/server" />
</entry>
</feed>
ATOM標準タグであるlinkタグのrel="self" hrefにエンドポイントを指定します。これをキーと呼びます。前述したように、ATOM linkタグをメタデータとして利用しています。
キーの/_html/serverはクライアントからのアクセスでは/_htmlが省略されて/serverになります。
つまり、これは http://{サービス名}.1.vte.cx/server にマッピングされます。(※ /_htmlは特殊なフォルダでありコンテキストルート/にマッピングされます)
また、contributorタグのuriにはACLを指定できます。これもATOM標準タグでありメタデータです。
このエントリでは管理者グループ(/_group/$admin)にCRUD権限(登録C、読込R、更新U、削除D)と、ログインユーザ(+)に読込R権限を与えています。
ACLについての詳しい説明は、アクセスコントロールを参照してください。
スキーマ設計
以下はvtecxblankプロジェクトのサンプルプログラムで定義されているスキーマです。(_settings/templateファイルが該当します)
userinfo
id(int)
email
favorite
food!=^.{3}$
music=^.{5}$
hobby{}
type
name
updated(date)
文法
- 改行してスペースを空けると子要素になります。idやemailは、userinfoの子要素です。
- ()には型を指定します。
- !で必須、=の右側にバリデーションのための正規表現を指定できます。(foodとmusic)
- hobbyの{}は配列を意味します。
- スキーマの項目名の変更や新しい項目の追加は可能ですが削除はできません。
記述についての詳しい説明は、テンプレートによるスキーマ定義を参照してください。
上記スキーマにより以下のようなJSONとして扱えるようになります。
ただし、entryやfeedはATOM feedの仕様に準拠します。つまり、1エントリはentryで表現されます。また、複数件を対象にするためentryの配列をfeedで括る形になります。
実際に、GET https://{サービス名}.1.vte.cx/d/registration?f を実行すると以下を取得できます。?fはfeedという意味です。
{
"feed": {
"entry": [
{
"userinfo": {
"id": 1,
"email": "abc@def"
},
"favorite": {
"food": "たまご",
"music": "ロックだよ"
},
"hobby": [
{
"type": "屋外",
"name": "テニス"
},
{
"type": "屋内",
"name": "卓球"
}
],
"author": [
{
"uri": "urn:vte.cx:created:11"
}
],
"id": "/registration/0-4-2-4-1-4-2,1",
"link": [
{
"___href": "/registration/0-4-2-4-1-4-2",
"___rel": "self"
}
],
"published": "2015-10-16T17:29:20.938+09:00",
"updated": "2015-10-16T17:29:20.938+09:00"
}
]
}
}
デプロイされるフォルダとデータについて
デプロイはgulpコマンドで実行できます。また、CircleCIに設定することでGithubにpushすれば自動的にデプロイを実行させることもできます。
gulp deploy -h http://{サービス名}.vte.cx -k アクセストークン
デプロイされるフォルダとデータは以下の通りです。
- dist (サーバの/配下に置かれるhtmlやcss、javascriptなどのコンテンツ)
- setup
- _html (コンテンツのACLをセットするためのエントリ情報)
- login.html
- ・・・
- _settings
- template(スキーマ情報)
- registration (これはユーザ定義のフォルダ。先頭に_が付かないので)
- food (registration配下にセットしたいユーザデータ)
- _html (コンテンツのACLをセットするためのエントリ情報)
環境設定や実際のインストール方法については明日以降の記事で紹介します。
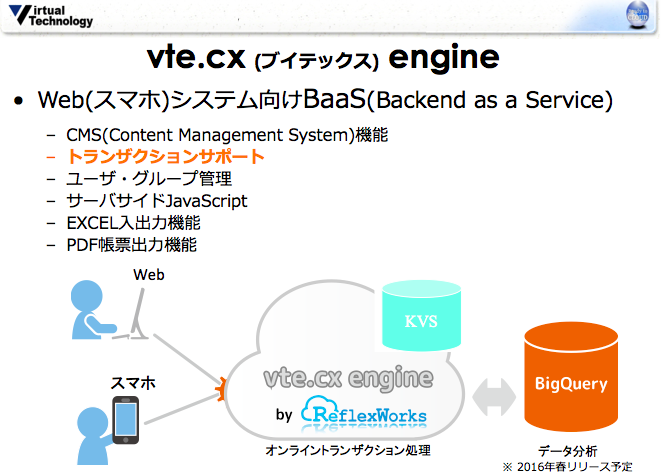
vte.cxがサポートする主な機能
vte.cxはオンライントランザクション処理基盤を提供します。
つまり、Feed単位のACIDトランザクション(分離レベル:REPEATABLE READ)、かつ、Entry単位のバージョン比較(分離レベル:SNAPSHOT ISOLATION)により、データの一貫性を確保しつつ高いスループットを実現します。
トランザクション処理についての詳しい説明は、一貫性をご覧ください。

また、これまで述べたように、vte.cxはHTMLやJavaScript、画像といったコンテンツをデータと同じように登録でき、CMSとしても利用することができます。
ユーザ・グループ管理を持っており、サーバサイドJavaScriptを実行できます。
EXCELデータの入出力やPDF帳票の出力なども可能です。
将来的にはBigQueryと連携してデータ分析を可能にします。
その他の概要についてもご参照ください。
これら機能の一つ一つについて、明日以降、Qiitaで紹介していきます。
不具合や改善点など何かお気づきの点がありましたら、githubのISSUEに入れてもらえると幸いです。
また、12/16(水)にセミナーをやるので、ご興味ある方はぜひご参加ください。
フロントエンドエンジニアの価値を高めるBaaS(vte.cx)
~ フロントエンドだけで作るこれからのWebシステム開発 ~
http://acrovision.connpass.com/event/22816/
このセミナーは終了しました。