#Apache Drillの導入〜サンプル実行〜カスタマイズ(完全版)
- とても面白いです。
System requirements
| Software | Version |
|---|---|
| OS | Cent OS 6.0(final) |
| Java | Open JDK 6 |
| ------------ | ----------- |
The system will be ...
| Software | Version |
|---|---|
| OS | Cent OS 6.0(final) |
| Java | Open JDK 8 |
| Apache Drill | 0.7.0 |
| ------------ | ----------- |
##0 Javaのアップグレード
現在インストールされているJDKの削除
- 確認
su
java -version
#>java version "1.6.0_33"
#>OpenJDK Runtime Environment (IcedTea6 1.13.5) (rhel-1.13.5.1.el6_6-x86_64)
#>OpenJDK 64-Bit Server VM (build 23.25-b01, mixed mode)
- 削除&最新版のJDKを確認
yum -y remove java-1.6.0-openjdk
yum search java | grep 'java-'
最新版のJDKをインストール
yum -y install java-1.8.0-openjdk-devel.x86_64
sed -i -e 's/^export\ JAVA_HOME/#export\ JAVA_HOME/g' /etc/profile;
sed -i -e '/^#export\ JAVA_HOME/a export\ JAVA_HOME=\/usr\/lib\/jvm\/java-1\.8\.0-openjdk-1\.8\.0\.25-3\.b17\.el6_6\.x86_64\/' /etc/profile;
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.25-3.b17.el6_6.x86_64
echo "export PATH=\$PATH:$JAVA_HOME/bin" >> /etc/profile
export PATH=$PATH:$JAVA_HOME/bin
alternatives --install /usr/bin/java java /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.25-3.b17.el6_6.x86_64/bin/java 2
alternatives --install /usr/bin/javac javac /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.25-3.b17.el6_6.x86_64/bin/javac 1
alternatives --config java
alternatives --config javac
#1 ダウンロードおよび解凍
Drillの最新版を公式ページからダウンロードします。
su
mkdir /usr/local/download/
cd /usr/local/download/
wget http://getdrill.org/drill/download/apache-drill-0.7.0.tar.gz
tar xzvf apache-drill-0.7.0.tar.gz
mv apache-drill-0.7.0 ../
cd ../
ln -s apache-drill-0.7.0 drill
echo "PATH=\$PATH:/usr/local/drill/bin" >> /etc/profile
export PATH=$PATH:/usr/local/drill/bin
#2 サンプルデータの準備
今回はYelp Dataset Challengeのデータを利用します。
cd /usr/local/download/
wget https://www.OneDrive.com/s/xg9r2msqj9ufa83/yelp_dataset_challenge_academic_dataset.tar?dl=0
mkdir yelp
mv yelp_dataset_challenge_academic_dataset.tar ./yelp/
cd yelp
tar xzvf yelp_dataset_challenge_academic_dataset.tar
cd ..
mv yelp/ /usr/share/
#3 実行
sqlline -u jdbc:drill:zk=local
##3.1 Yelpビジネスデータの内容を見てみる
#sqllineのシェル上で実行
select * from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` limit 1;

##3.2 データセットに含まれるレビュー数の合計値
select sum(review_count) as totalreviews from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json`;

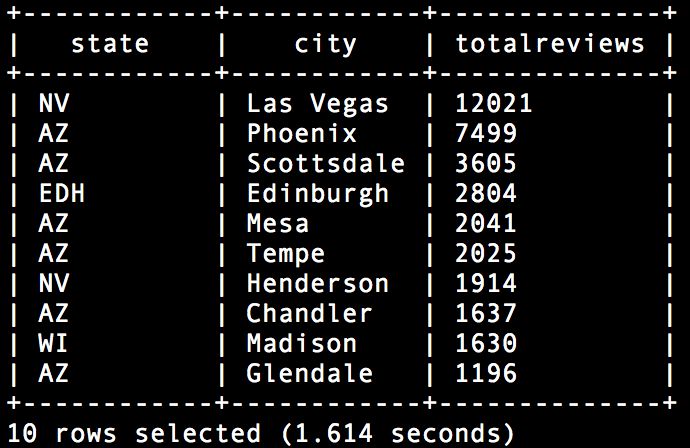
##3.3 合計レビュー数がトップの州と都市
select state, city, count(*) totalreviews from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` group by state, city order by count(*) desc limit 10;
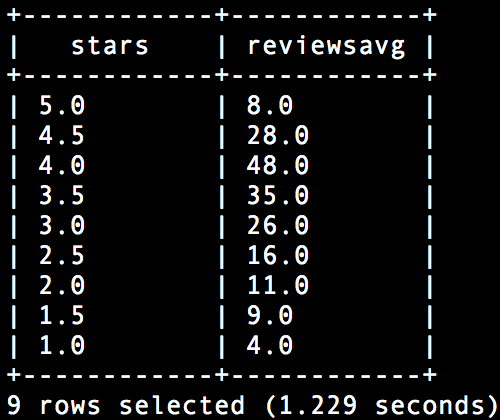
##3.4 ビジネス格付け別の平均レビュー数
select stars,trunc(avg(review_count)) reviewsavg from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` group by stars order by stars desc;
##3.5 レビュー数が多い (1000回以上) トップビジネス
select name, state,city, `review_count` from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` where review_count > 100 order by `review_count` desc limit 10;

##3.6 一部ビジネスの土曜日の開店・閉店時間を確認
==※Drillにより、マルチ構造のネスト全体を調査できることにご注目ください。==
select b.name, b.hours.Saturday.`open`, b.hours.Saturday.`close` from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` b limit 10;

##3.7 テキストモードをオンにして、あらゆるテキストを検索する。
###3.7.1 テキストモードをオンにする。
alter system set `store.json.all_text_mode` = true;
###3.7.2 データセット内の各ビジネスの特典を調べます。
Yelpビジネスデータセットの属性欄には、各行ごとに異なる要素が入っており、ビジネスに別々の特典を設けられるようになっています。Drillでは、スキーマを変えて素早く簡単にデータセットを分析できます。
まず、あらゆるテキストモードで機能するようにDrillを設定します (あらゆるデータを調査できるようにするため)。
select attributes from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` limit 10;

###3.7.3
alter system set `store.json.all_text_mode` = false;
##3.8 データセット内のレストランビジネスについて調査します。
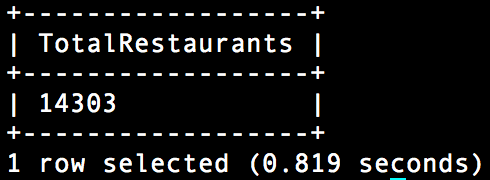
###3.8.1 データセット内にいくつのレストランが存在するか?
select count(*) as TotalRestaurants from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` where true=repeated_contains(categories,'Restaurants');
###3.8.2 レビュー数トップのレストラン
select name,state,city,`review_count` from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` where true=repeated_contains(categories,'Restaurants') order by `review_count` desc limit 10;

###3.8.3 カテゴリ数トップのレストラン
select name,repeated_count(categories) as categorycount, categories from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` where true=repeated_contains(categories,'Restaurants') order by repeated_count(categories) desc limit 10;

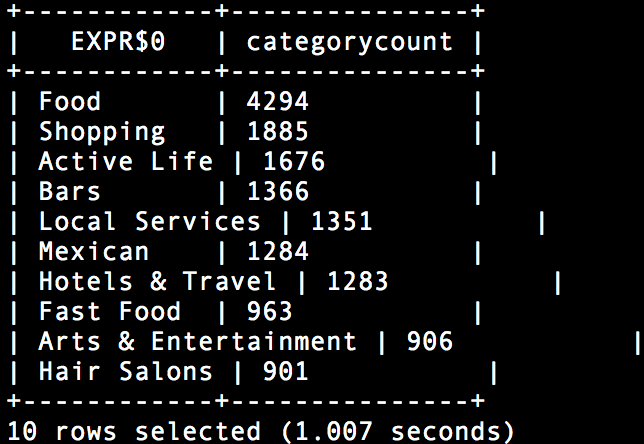
###3.8.4 レビュー数トップのカテゴリ
select categories[0], count(categories[0]) as categorycount from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` group by categories[0] order by count(categories[0]) desc limit 10;
##3.9 Yelpレビューのデータセットを調査し、ビジネスと組み合わせます。
###3.9.1 Yelpレビューのデータセットの内容を調査します。
select * from dfs.`/usr/share/yelp/yelp_academic_dataset_review.json` limit 1;

###3.9.2 評価の良いレビューが投稿されているビジネス
ここでは、総レビュー数 (review_count) が含まれるYelpビジネスデータセットを、各レビューの追加詳細が含まれるYelpレビューデータに組み合わせています。
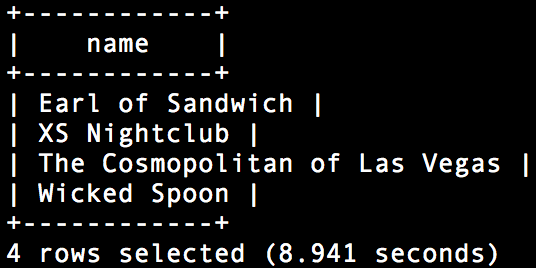
Select b.name from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` b where b.business_id in (SELECT r.business_id FROM dfs.`/usr/share/yelp/yelp_academic_dataset_review.json` r GROUP BY r.business_id having sum(r.votes.cool) > 2000 order by sum(r.votes.cool) desc);
###3.9.3 ビジネスとレビューのデータセットを組み合わせたビューを作成
Drillのビューは軽量なので、ローカルのファイルシステムで作れます。スタンドアローンモードのDrillには、dfs.tmpワークスペースが付いてきます。これをビューの作成に使用できます。 (あるいは、ご自分のローカルまたは分散型ファイルシステムで独自のワークスペースを定義しても構いません)。データを論理的ビューではなく物理的なままにしておきたい場合は、CREATE TABLE AS SELECT構文を使うことができます。
create or replace view dfs.tmp.businessreviews as Select b.name,b.stars,b.state,b.city,r.votes.funny,r.votes.useful,r.votes.cool, r.`date` from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` b , dfs.`/usr/share/yelp/yelp_academic_dataset_review.json` r where r.business_id=b.business_id;

###3.9.4 ビューから合計記録数を取得
select count(*) as Total from dfs.tmp.businessreviews;

これらのクエリに加え、DrillのSQL機能を使えば、格段に詳細な分析が可能になります。マニュアルでクエリを記述したくない場合は、Tableau/MicrostrategyなどのBI/分析ツールを使って、生ファイル/Hive/HBaseデータのクエリを行い、Drill ODBC/JDBCドライバーを使って直接Drillで作成したビューをクエリすることが可能です。
Apache Drillでは、データ分析に、これまでのSQL技術では見たことのないような自由と柔軟性を提供することを目的としています。当コミュニティでは、今後のリリースに向けて、ネスト化したデータや変化するスキーマを使ったデータサポート周り対して更にユニークな機能を開発中です。
例えば、更に詳細なSQL機能を適用できるように、半構造化データを動的に関連付けするために使用できる新たな「結合」機能を開発中です (0.7の新機能)。クエリに対する結合機能の使用法をご紹介します。
###3.9.5 それぞれのビジネスについて、結合されたカテゴリー一覧を取得
select name, flatten(categories) as category from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` limit 20;

###3.9.6 ビジネスレビューで使用されるトップのカテゴリ
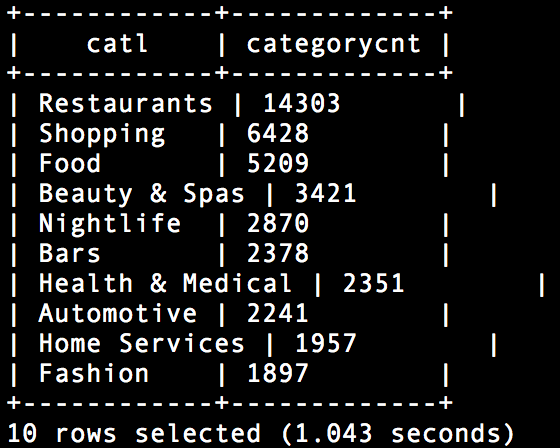
select celltbl.catl, count(celltbl.catl) categorycnt from (select flatten(categories) catl from dfs.`/usr/share/yelp/yelp_academic_dataset_business.json` ) celltbl group by celltbl.catl order by count(celltbl.catl) desc limit 10;
#References
こちらのページを参考にしながら行いました。