はじめに
このページでは、MySQL InnoDBの介在する大規模サービスにおいて考慮すべきインサート性能の問題と、ID生成戦略として、ゆるやかに増える64bit(8byte)の整数値を使う方法と、UUIDを問題を回避して用いる方法について説明します。
100万行以上でおこるインサート性能問題
MySQL InnoDBで大規模サービスを設計/運用している方なら周知の事実かもしれませんが、MySQLのInnoDBには、int(4byte)よりも大きなサイズのカラムにインデックスが貼られたテーブルに、カーディナリティの高いランダムなデータを入れてインサートをしようとすると100万行以上で急激にインサート性能が落ちるという問題があります。
MySQL InnoDB Primary Key Choice: GUID/UUID vs Integer Insert Performance 、というサイトで紹介されている実験例では、ランダムなGUID/UUID(実際は16bytesで表現できるがここでは36charで表現)とインクリメンタルなIntegerで性能評価していますが、上記で表示されているグラフをよく見えると
- 200万行時点での整数値と文字列の比較で、レコードのインサート性能は4倍近く遅くなる
- 200万行時点と2000万行時点との比較で、レコードのインサート性能の劣化し22倍遅くなる
というようなことが起こります。なお、これはMySQL5.0時点の実験ですが、MySQL5.5でも同様の現象が発生します。
原因はいまいち自分自身も理解していないのですが、InnoDBのBツリーインデックスの作り方と最適化の実装に依存するものだと想定されます。
実験してインサート性能を比較してみる
では実際に、MySQL5.5で自分の手元のMBP2011(late)で簡単な実験をしてみます。
比較するものは、
- ランダムなint
- ランダムなbigint
- インクリメンタルなbitint
のそれぞれのIDでインサート性能を比較います。
実験の構成
よくあるユーザー同士の一方向の関連を表すテーブルを作っています。
indexは実際に使うことが多いような日付と合わせた複合インデックスを用意し、さらに全てのテーブルのデータ量がおなじになるようにdummyでパディングしてあります。
int(4bytes)用のテーブル:
create table `user_relations` (
`from_user_id` int NOT NULL,
`to_user_id` int NOT NULL,
`from_user_id_dummy` VARCHAR(124) NOT NULL,
`to_user_id_dummy` VARCHAR(124) NOT NULL,
`created_time` DATETIME NOT NULL,
PRIMARY KEY (`from_user_id`, `to_user_id`),
INDEX `relation_index_created_time` (`from_user_id`, `to_user_id`, `created_time` )
) ENGINE=InnoDB DEFAULT CHARACTER SET=latin1
bigint(8 bytes)のテーブル:
create table `user_relations` (
`from_user_id` bigint NOT NULL,
`to_user_id` bigint NOT NULL,
`from_user_id_dummy` VARCHAR(120) NOT NULL,
`to_user_id_dummy` VARCHAR(120) NOT NULL,
`created_time` DATETIME NOT NULL,
PRIMARY KEY (`from_user_id`, `to_user_id`),
INDEX `relation_index_created_time` (`from_user_id`, `to_user_id`, `created_time` )
) ENGINE=InnoDB DEFAULT CHARACTER SET=latin1
以上のようなテーブル構成です。
また、rubyで簡単にデータ作成スクリプトを用意しました。
なお、DATETIME(8bytes)にいれるデータは、あまりにもカーディナリティが大きくならないように2015年から2025年の間の日時しか入らないようにしてあります。
ランダムなintのクエリ生成スクリプト:
require 'securerandom'
require "date"
(1..5000000).each { |i|
from_user_id = SecureRandom.random_number(2147483647)
to_user_id = SecureRandom.random_number(2147483647)
from_user_id_dummy = SecureRandom.hex(62)
to_user_id_dummy = SecureRandom.hex(62)
s1 = Date.parse("2015/07/28")
s2 = Date.parse("2025/07/28")
s = Random.rand(s1 .. s2)
date = s.strftime("%Y/%m/%d %H:%M:%S")
# より現実に即すようにわざとバルクインサートにしない
puts "insert into user_relations values(#{from_user_id}, #{to_user_id},'#{from_user_id_dummy}', '#{to_user_id_dummy}', '#{date}');"
}
ランダムなbigintのクエリ生成スクリプト:
require 'securerandom'
require "date"
(1..5000000).each { |i|
from_user_id = SecureRandom.random_number(9223372036854775807)
to_user_id = SecureRandom.random_number(9223372036854775807)
from_user_id_dummy = SecureRandom.hex(60)
to_user_id_dummy = SecureRandom.hex(60)
s1 = Date.parse("2015/07/28")
s2 = Date.parse("2025/07/28")
s = Random.rand(s1 .. s2)
date = s.strftime("%Y/%m/%d %H:%M:%S")
# より現実に即すようにわざとバルクインサートにしない
puts "insert into user_relations values(#{from_user_id}, #{to_user_id},'#{from_user_id_dummy}', '#{to_user_id_dummy}', '#{date}');"
}
インクリメンタルなbigintのクエリ生成スクリプト:
require 'securerandom'
require "date"
(1..5000000).each { |i|
from_user_id = i * 4294967296
to_user_id = i * 4294967296 + 2147483648
from_user_id_dummy = SecureRandom.hex(60)
to_user_id_dummy = SecureRandom.hex(60)
s1 = Date.parse("2015/07/28")
s2 = Date.parse("2025/07/28")
s = Random.rand(s1 .. s2)
date = s.strftime("%Y/%m/%d %H:%M:%S")
# より現実に即すようにわざとバルクインサートにしない
puts "insert into user_relations values(#{from_user_id}, #{to_user_id},'#{from_user_id_dummy}', '#{to_user_id_dummy}', '#{date}');"
}
実験結果
結果としては、ランダムintとインクリメンタルbigintはほぼずっと4000~5000QPS(query per second)を維持しているのに対して、ランダムなbigintは1000QPS前後となり、データ量が増えるに連れて悪化します。
つまり、先ほど紹介されていたMySQL InnoDB Primary Key Choice: GUID/UUID vs Integer Insert Performanceの実験結果の4倍悪くなるというところとも合致します。
それぞれのQPSの散布図については以下のとおりです。
ランダムなintのQPS:
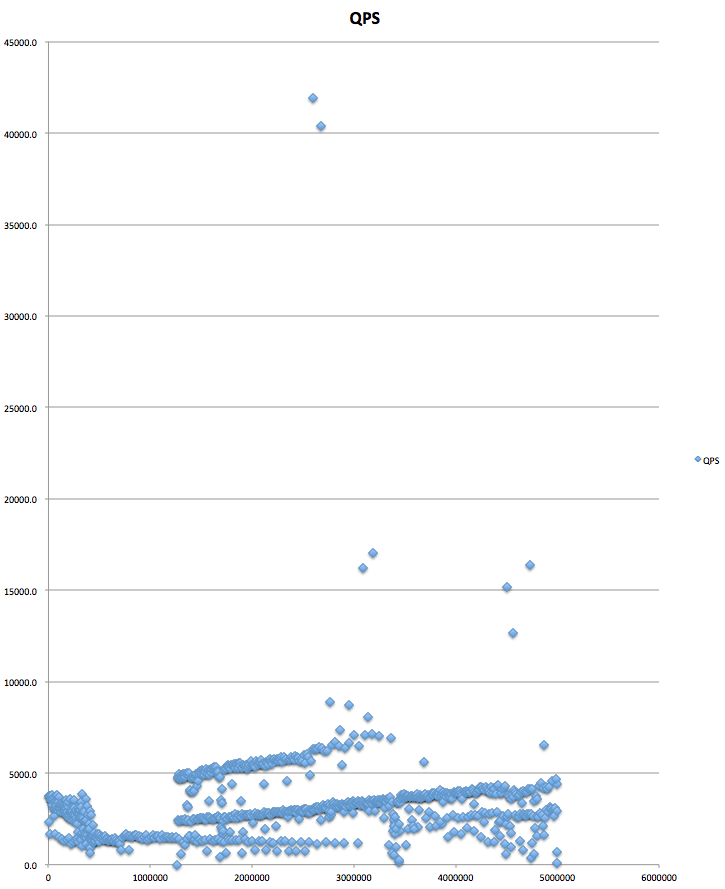
ランダムなbigintのQPS:
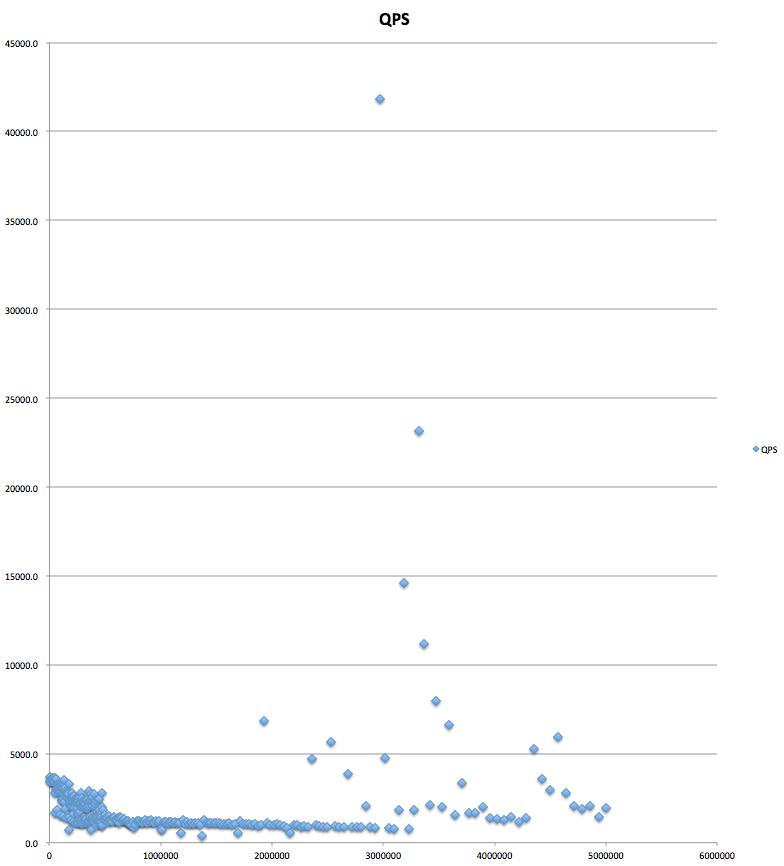
インクリメンタルなbigintのQPS:
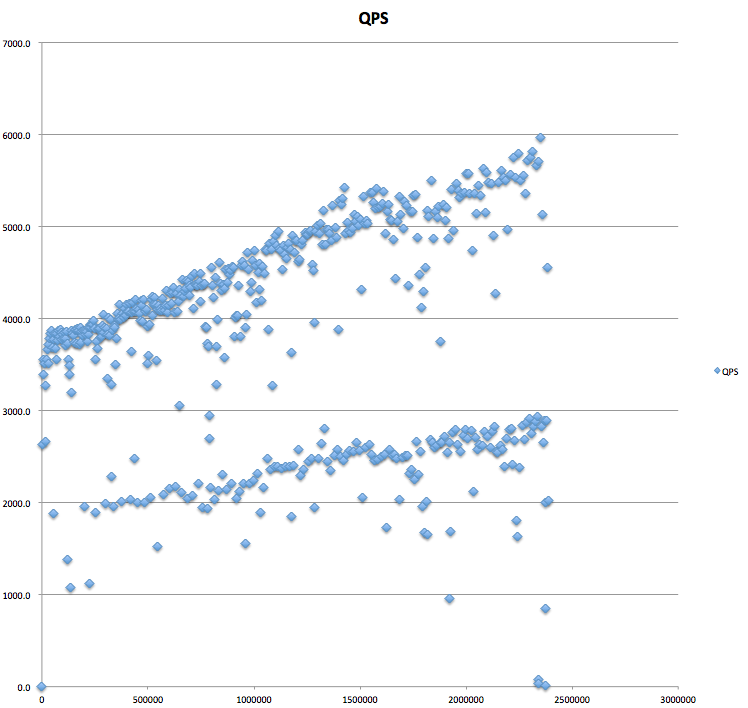
なお、ランダムなデータに関して言えば、int(4bytes)よりも大きなデータに関してはほぼ同様のinsert性能が悪化していく傾向が見られます。
詳しくは、sifue/mysql_id_strategyにあげてある全てのデータをご確認下さい。
解決策として64bitのゆるやかに増える整数値IDを用いる
このような問題にどう立ち向かえばよいでしょうか?
対策方法としては、Facebook, Twitter, Instagram等がどうやってIDを生成しているのか まとめでもまとめられていますが、64bitの各bitにRDBのシャードID、タイムスタンプ、インクリメンタルなIDなどを割り当ててゆるやかに増える整数値として利用する、ということで対策することができます。
この64bit(long値、bigint値)のIDのメリットは、
- ゆるやかに増えるIDを設計にすることでinsert性能問題を回避できる
- 64bitの数値という情報は取扱安い
- 世界規模のサービスでも問題無十分な衝突耐性が確保できる
この3点です。
情報の取り扱い安さは、特にリソースが限られているモバイルのマシンにあっても少ないリソースで取り扱える他、サーバーサイドにおける高速な集合演算などもとり行うことができます。
また、ある程度の衝突耐性も設計によって確保できるので、必ずしもサーバーサイドで作る必要もないし、逆にサーバーで作る際にもかなり高速なID生成をすることができます。
これらの理由から、Facebook、Twitter、Instagram、Flickr、Pintarest、SmartNewsが64bitのIDを採用していると考えることができます。
しかし64bit(long値、bigint値)のIDにはデメリットもあります。
- bit演算がバグを起こしやすい
- 各言語で専用64bitIDのエンコーダー/デコーダライブラリを作る必要がある
以上のようなものです。実際に自分自身もこの64bitのIDにおいて、
ビット演算子の&と^と<<の優先順位をうっかり間違って異なる結果になっていたというような現場に出くわしたことがあります。
このようなデメリットを考えた時にやはり、
- UUIDのようなより扱いやすいID形式を用いたたい
- UUIDの16bytesのIDと発生するデータを全て入れられるサイズのRDBを用意することはできないのでUUIDに対してシャードIDなどの情報を付加したい
という要望が発生します。
UUIDv1とシャードIDを組み合わせてバイナリとして取り扱うという回避策
このようなどうしてもUUIDを用いたいという場合のための回避策があります。
先ず最初にUUIDについて説明しなくてはならいのですが、UUIDにはいくつかバージョンがあります。詳しくは、RFC4122を見たほうが良いのですが、よく利用されるものに以下の2つがあります。
- v1
- MACアドレスとUUIDの生成日時によるもの。通常、MACアドレスが一意であることにより、この種のUUIDは一意であることが保証される。
- v4
- 疑似乱数によるもの。バージョン番号の識別などに使用されるビットを除くすべてのビットを疑似乱数で生成する。
MySQL InnoDBにシャードID等と一緒に入れたい場合には、UUIDv1を使う必要があります。
これを使うことによって、ゆるやかに増加するという条件をパスできます。
そして、その末尾にシャードID(short値 2bytes)を加えたバイナリ(18bytes)をキーにすることによってこのインサート性能が悪化する問題を回避することができるのですが、実際に大丈夫かどうか実験を行ってみます。
なお、この時バイナリを作る際には結合の順番が重要です。UUIDv1+シャードIDではインサート性能の問題は起こりませんが、シャードID+UUIDv1では上記の問題が生じてしまいます。では実際に実験を見てみましょう。
実験の構成
実際に実験するときのテーブルの構成は以下のようになります。
バイナリ(18bytes)をキーに持つテーブル:
create table `user_relations` (
`from_user_id` binary(18) NOT NULL,
`to_user_id` binary(18) NOT NULL,
`from_user_id_dummy` VARCHAR(110) NOT NULL,
`to_user_id_dummy` VARCHAR(110) NOT NULL,
`created_time` DATETIME NOT NULL,
PRIMARY KEY (`from_user_id`, `to_user_id`),
INDEX `relation_index_created_time` (`from_user_id`, `to_user_id`, `created_time` )
) ENGINE=InnoDB DEFAULT CHARACTER SET=latin1
以上のようなテーブル構成です。
クエリ作成スクリプトは以下のとおり。一応、順番が重要であることを示すために2つのスクリプトを用意します。
UUIDv1+シャードID向け:
require 'securerandom'
require 'date'
require 'uuid'
uuid = UUID.new # gem install uuid
(1..5000000).each { |i|
from_user_id = '0x' + uuid.generate.gsub(/-/, "") + SecureRandom.hex(2)
to_user_id = '0x' + uuid.generate.gsub(/-/, "") + SecureRandom.hex(2)
from_user_id_dummy = SecureRandom.hex(55)
to_user_id_dummy = SecureRandom.hex(55)
s1 = Date.parse("2015/07/28")
s2 = Date.parse("2025/07/28")
s = Random.rand(s1 .. s2)
date = s.strftime("%Y/%m/%d %H:%M:%S")
# より現実に即すようにわざとバルクインサートにしない
puts "insert into user_relations values(#{from_user_id}, #{to_user_id},'#{from_user_id_dummy}', '#{to_user_id_dummy}', '#{date}');"
}
シャードID+UUIDv1向け:
require 'securerandom'
require 'date'
require 'uuid'
uuid = UUID.new # gem install uuid
(1..5000000).each { |i|
from_user_id = '0x'+ SecureRandom.hex(2) + uuid.generate.gsub(/-/, "")
to_user_id = '0x'+ SecureRandom.hex(2) + uuid.generate.gsub(/-/, "")
from_user_id_dummy = SecureRandom.hex(55)
to_user_id_dummy = SecureRandom.hex(55)
s1 = Date.parse("2015/07/28")
s2 = Date.parse("2025/07/28")
s = Random.rand(s1 .. s2)
date = s.strftime("%Y/%m/%d %H:%M:%S")
# より現実に即すようにわざとバルクインサートにしない
puts "insert into user_relations values(#{from_user_id}, #{to_user_id},'#{from_user_id_dummy}', '#{to_user_id_dummy}', '#{date}');"
}
実験結果
実験結果は、以下のとおり、UUIDv1+シャードIDでIDを作ってモノに関しては、4000-5000QPSを維持し、パフォーマンス上問題が無いことがわかります。ただし、逆の順番のものは良いパフォーマンスを出すことができませんでした。
UUIDv1+シャードIDのQPS:
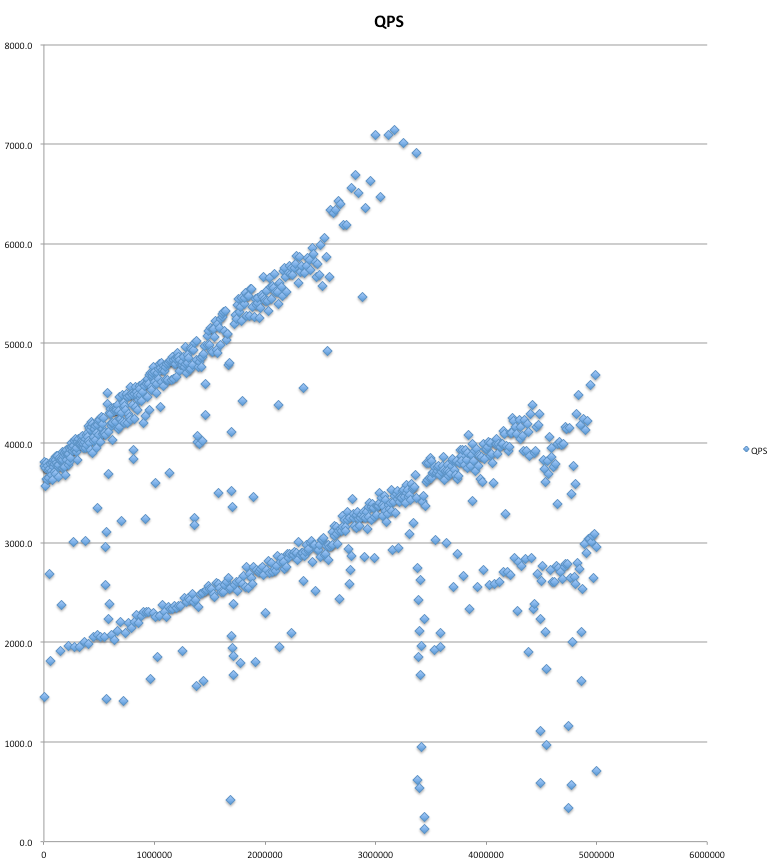
シャードID+UUIDv1のQPS:
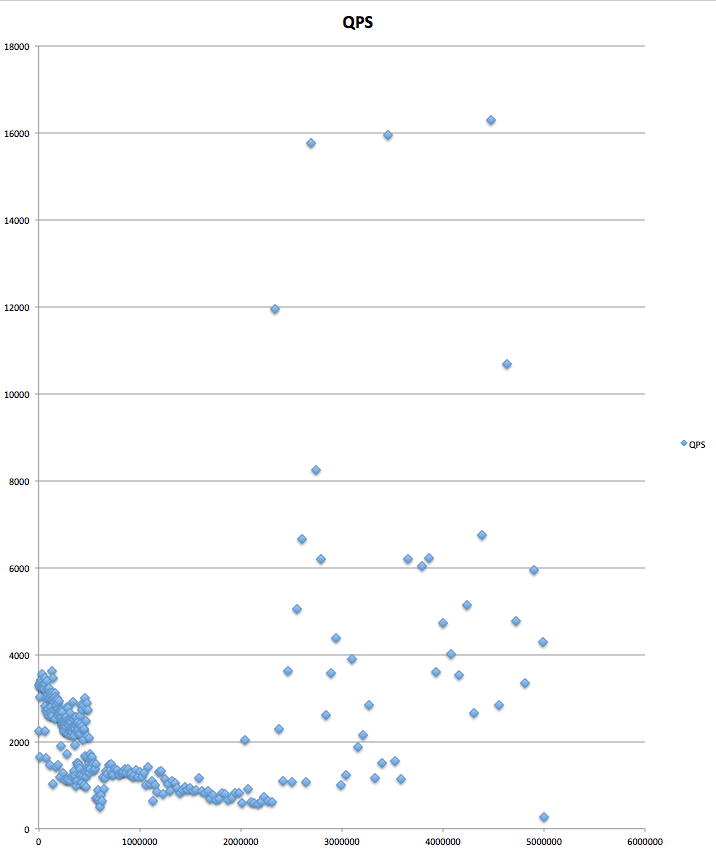
UUIDを使った方法でもこのように回避することでMySQL InnoDBを用いることができることがわかりました。
まとめ
MySQL InnoDBを大規模サービスで取り扱う際には、100万行以上におけるインサート性能の問題と付き合わなくてはいけません。その対処法としては、
- ゆるやかに増える64bitのID生成戦略で対応する
- ゆるやかに増えるUUIDv1とシャードID等を組み合わせてバイナリで対応する
以上の方法があります。
ただし、64bitの整数値のメリット・デメリットは先に述べたとおりですが、UUIDを扱う際にも注意が必要で、扱いやすさは上がるのですが
- 64bitのIDに比べてデータサイズが大きい
- UUIDv1を扱う際には、MACアドレスが外部に流出してしまうため、その辺りのセキュリティリスクを考え無くてはならない
というところがネックになることを注意しなくてはいけません。この問題を回避するために任意のバイナリから作成できるUUIDv3を導入するという手もあります。
今は世界規模のサービスが沢山あるため、そのサービスに連携する側もこのような最近大規模なデータをRDBで扱わなくてはならないことも多々あります。みなさんもこのへんはよく実験したりして設計していくようにしましょう。
実験データ
なお、この実験の実験データは、GitHubのsifue/mysql_id_strategy にて公開してあります。