はい。というわけでLivesenseアドカル23日目は@shusuke_otaniがお送りします。
#対象
SQLにおいて可読性をジャスティスとする人 LIKE me。
下にもあるようにちょっと前までトーシロだったので、
「おいおい、坊や、お前は何もわかっちゃいねぇよ(タバコスパー」な方はコメントを頂けると(∩´∀`)∩ワーイ
#自己紹介
初投稿なので自己紹介しときます。
リブセンスの赤魔道士大谷。広告マーケティングとエンジニアリングやってます。
直感性を大切にしてます。(ていうか直感性しか武器がない)
今年の10月にようやく社会人になった未熟者ゆえ、日々メンターより、メールの書き方から、コントローラーの肥大化まで多ジャンルに渡って、鉞(マサカ)られるという刺激的で☆☆素敵☆☆な日々を送ってます。
ちなみにメンターは@eri氏でとーーってもこわひ優しい人、氏の趣味はもちろん鉞で
、社内では"とにかく鉞る福田"と呼ばれてます。
#可読性向上術
記していきます。僕はできるだけ少ない行で書きたいので、社内のSQLの書き方のルールと結構ずれてます。
一つの処理につき一行がモットーです。
##LIKEの代わりに正規表現を使う。
LIKEでOR使うってなんかとっても芋いらしいです。
CASE WHEN ua LIKE '%docomo%'
OR ua LIKE '%softbank%'
OR ua LIKE '%kddi' ...
とか長いし同じこと何回も書いてるし、一行ですっきりまとめ隊ですね!!
IFとRegExpですっきりみやすくできますね!そう、mySQLならね!
IF(ua RegExp 'iPhone|iPad|Android|KDDI|J-PHONE|Vodafone|DoCoMo|Softbank', 'SP','PC') AS device
ちなredshiftでも '~'とcase when使えば簡単に書けますー。
WHERE url ~ '^https?://(job\\.)?j-sen\\.jp'
##GROUP BYした結果をさらにフィルタリングする必要があるときはHAVINGを使う
"全アクセスユーザーのうち、5個以上のsession_id(セッションごとに付与される)を持つもの"
を抽出したい場合、HAVINGを書かないで書くとネスト必須ですが
SELECT user_id
FROM(
SELECT user_id, COUNT(DISTINCT session_id) AS cnt
FROM access_logs
GROUP BY user_id)
WHERE cnt >= 5
HAVINGを使うと、たった4行で終わります!!
SELECT user_id
FROM access_logs
GROUP BY user_id
HAVING COUNT(DISTINCT session_id) >= 5
##ネストする時は、WITHか、一時テーブルを使用する。
ネストされたSQLって著しく直感性を損なっていて、それが僕のソウルジェムを漆黒に濁らせるので、基本3層以上のネストは解体してWITH句にまとめマンモス。あとあるSELECT句の結果を何回も再利用したい時とか使わない手はないです。
クエリの本筋とサブ筋(造語)は分けたいしー。
なので、WITHか一時テーブルでどんどんネストを消していきましょう!
一時テーブル作ったらちゃんとTRUNCATEしていきましょうー。
SELECT *
FROM access_logs
WHERE user_id IN (
SELECT DISTINCT user_id
FROM access_logs
WHERE hit_time >= '2015-10-01'
AND age >= 20
AND gender = 'male')
WITH key_users AS(
SELECT DISTINCT user_id
FROM access_logs
WHERE hit_time >= '2015-10-01'
AND age >= 20
AND gender = 'male')
SELECT *
FROM access_logs
WHERE user_id IN (SELECT user_id FROM key_users)
大分すっきりしました(∩´∀`)∩ワーイ
##分析関数(window関数)を使って、連番を付与。
めっちゃ便利です。集団ごとにパーティション区切って得点順にランク付けとか連番付与とか、より具体的な利用法だと、ユーザーの前回アクセス時の流入時間をとったり、最後に滞在した国を取得したりと、SQLの可能性を飛躍的に高める魔法ですね、魔法!
分席関数はGROUP BYと違って、その結果をレコードに返すという作業になるので、アイディア次第でその発想は∞大!
ま、例をみたほうが早いということで!
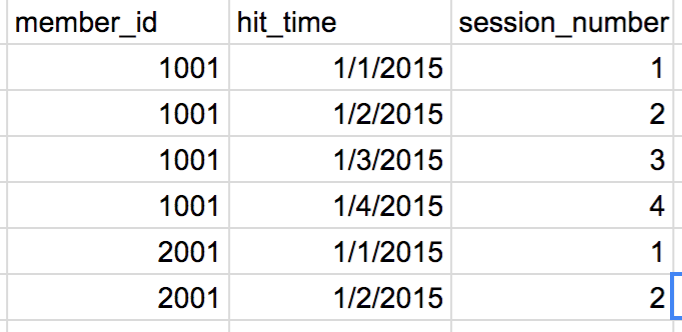
例えばユーザーごとにヒットタイム順にレコードに連番を振りたい場合、以下のようにスラスラ−と簡単にかけます。
SELECT member_id
,hit_time
,ROW_NUMBER() OVER(PARTITION BY member_id ORDER BY hit_time) :: int AS session_number
アウトプットイメージ
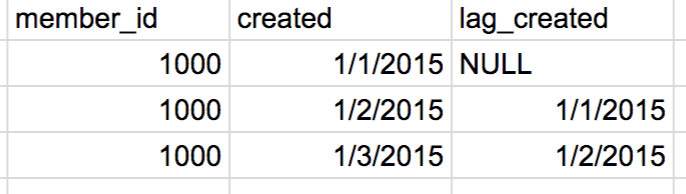
次のサンプルは、一つ前のcreatedを取得するものです。
SELECT member_id
,created
,LAG(created) OVER(PARTITION BY member_id ORDER BY created) AS lag_created
アウトプットイメージ
あ、余談ですが、僕はSELECT文のカラムの直前にいれます。そうすると、そのカラムがイラネ! ( ゚д゚)ノ ってなった時、もしくはこのカラムが( ゚д゚)ホスィ
ってなった時に、一行を消したり追加したりするだけで済むからです。vimだとddとかで瞬殺どす。
直後にカンマいれると削除・追加工数が増えますねー。
っていうかカンマって意味としてはANDなわけじゃないですか。
WHERE句では
WHERE hoge = 1
AND huga = 2
って書くのに
SELECT句では
SELECT hoge,
huga
って書くのは一貫性ないんじゃないかなと!だったらもうSELECT句もカンマで始めましょう!(ゴリ押し)
一処理一行ってやっぱ気持ちいいんですよー。
##型変換はCASTの代わりに'::'を使う(redshift)
CAST(user_id AS int)
もうそのまんまです。
user_id :: int
まじ楽ー。redshiftマジ楽ー。(だんだん雑になっていく。。。)
##日付を丸める
2015年12月中にアクセスした人
WHERE TRUNC(hit_time) BETWEEN '2015-12-01' AND '2015-12-31'
月別のGROUP BY
DATE_TRUNC('month', hit_time) AS month
DATE_FORMAT(created, '%Y%m') AS month