追記(2021/12/06)
なんと、、、
ジョイマンさんご本人にツイートして頂きました😂
はじめに
この記事は、以下の記事に感銘を受けて書いたものです。
また、一部実装および記事の内容も参考にさせて頂きました。
ジョイマン
ジョイマンは、2人組の日本のお笑いコンビです。
韻を踏むボケ担当の高木晋哉(たかぎしんや)と、ツッコミの池谷和志(いけたにかずゆき)からなります。
韻を踏むネタとその独特の世界観が特徴的です。
詳しくは、以下のYouTubeをご覧ください。
定式化
ジョイマンのネタは、韻を踏むのが特徴です。
代表的なネタについては、こちらの一覧を参考にしました。
調べたところ、以下のパターンがあることがわかりました。
| パターン | 説明 | 例 |
|---|---|---|
| ① | 単純に韻を踏むパターン。 一番単純。一番多いネタもコレ。 |
「コラーゲン 主電源」 「毛根 ベーコン」 「広辞苑 中耳炎」 |
| ② | 部分文字列で韻を踏むパターン。 たとえば、「おなかのたるみ テルミーショウミー」では、「おなかのたるみ」という文字の一部「たるみ」で韻を踏んでいる |
「おなかのたるみ テルミーショウミー」 「母さんのぬくもり 甘栗 山盛り」 |
| ③ | 部分文字列同士で韻を踏むパターン。 たとえば、「人で賑わう繁華街 家帰ったらうがい」では、「繁華街」と「うがい」というそれぞれの部分文字列で韻を踏んでいる |
「人で賑わう繁華街 家帰ったらうがい」 「汗はしょっぺー 椎名は桔平」 |
| ④ | 部分文字列で韻を踏み、かつ対になっているパターン。 たとえば、「運動は大事 板東は英二」では、「運動」と「板東」、「大事」と「英二」というペアで韻を踏んでいます。 |
「運動は大事 板東は英二」 「ニコール・キッドマン イコールコッペパン」 「七転び八起き 生わさび歯ぐき」 |
| ⑤ | その他。 特に規則性はなさそう。 |
「母さんがよなべをして手袋アンドクリエイター」 など |
パターン⑤は規則性が見つけられなかったため、対象外としました。
また、将来的にはパターン④の「運動は大事 板東は英二」を出力したいのですが、いきなりは難しそうです。
今回は、簡単に取り組めそうなパターン①をやってみました。
韻を踏む
そもそも「韻を踏む」とは、同じ言葉や同じ母音を持つ言葉を繰り返し使う手法(参考)です。
「同じ言葉の繰り返し」は、「同じ母音の繰り返し」の集合に含まれるので、今回は「同じ母音の繰り返し」を条件とします。
また、正確には母音ではありませんが、リズム感が感じられるので「ん(n)」も母音に含めることにします。
次に、同じ母音の繰り返しは何文字とするか、を決めます。
たとえば、「運動(unou)」「板東(anou)」は最後の3文字、「大事(aii)」「英二(eii)」は最後の3文字の母音が一致します。
全体的にネタを見る限り、最後の2文字だけ同じというものが多く、それでも十分にリズム感を感じることができるかと思います。
よって、「母音の最後の2文字が同じ」という条件にします。
さらに、単語の母音の文字数は同じものに限る、という条件を付け加えます。
これは、極端に文字数が異なるとリズム感が損なわれると考えたためです。
たとえば、「運動(unou)」「板東(anou)」はともに4文字、「大事(aii)」「英二(eii)」はともに3文字の母音になっていますね。
これらをまとめると、条件は以下になります。
- 韻を踏む、とは同じ母音の繰り返し。ただし、ここでは母音はaiueo+nとする
- 母音の最後の2文字が同じ
- 母音の文字数は同じ
実装
それでは、いよいよ実装していきます。
言語はPython、環境はGoogle Colaboratoryを使用します。
まずは使用する単語のリストを入手します。
今回は、Wikipediaのタイトルのリストを使うことにしました。
まずはダウンロード・展開しましょう。
!wget http://download.wikimedia.org/jawiki/latest/jawiki-latest-all-titles-in-ns0.gz
!gunzip jawiki-latest-all-titles-in-ns0.gz
展開したファイルを読み込みます。
# ファイル読み込み
with open('jawiki-latest-all-titles-in-ns0') as f:
titles = f.readlines()
titlesには、Wikipediaのタイトルがリストとして格納されています。
使いやすさのため、dataframeにしておきましょう。
import pandas as pd
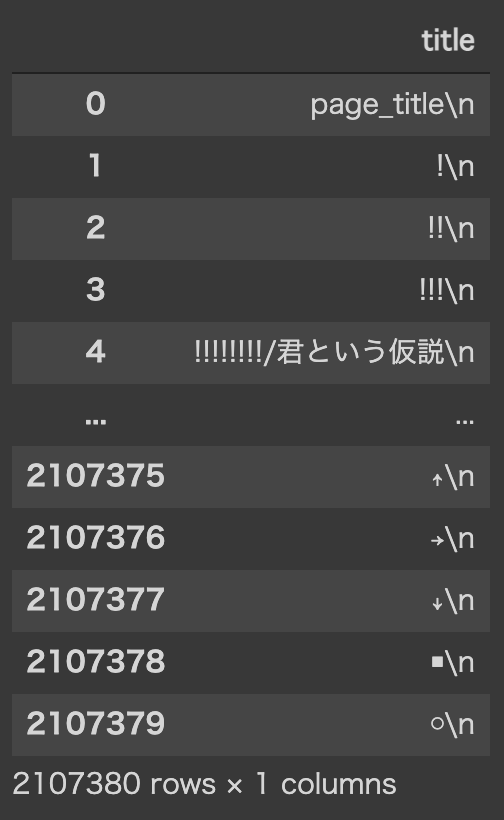
df_org = pd.DataFrame({'title': titles})
df_org
以下のように出力されました。
dataframeを整形します。
dataframeには不要な文字列が含まれているので削除します。
また、今回は話を簡単にするため、英数字を含まないワードのみを対象にすることとします。
df = df_org[1:] # 1行目以降を抽出
df = df.replace('\s', '', regex=True) # 改行コードを削除
df = df[~df['title'].str.contains('[a-zA-Z0-9]')] # 半角英数字を含まないもののみ抽出
次に、文字をカタカナやローマ字に変換するpykakasiをインストールします。
!pip install pykakasi
それでは母音を抽出してみましょう。
「ゴー☆ジャス(宇宙海賊)をつくる」のコードを参考にしました。
import pykakasi
kks = pykakasi.kakasi()
def romanize(text):
"""ローマ字に変換"""
result = ''
for i in kks.convert(text):
result += i['hepburn']
return result
def extract_vowel(text):
"""母音(aiueo)とン(n)を抽出"""
return ''.join([i for i in text if i in ['a', 'i', 'u', 'e', 'o', 'n']])
試しにこれらの関数を使ってみます。
text = 'ジョイマン'
romanized_text = romanize(text)
extract_vowel_text = extract_vowel(romanized_text)
print(romanized_text)
print(extract_vowel_text)
# joiman
# oian
ちゃんと、ローマ字にした後、母音を抽出できていることがわかります。
それでは、これらの関数をdataframeに適用しましょう。
以下ではapplyを使って、title列の全ての値に対して、romanize関数、extract_vowel関数と順に適用しています。
df['vowel'] = df['title'].apply(romanize).apply(extract_vowel) # 母音の抽出
df = df[df['vowel'] != ''] # 母音のないものは削除
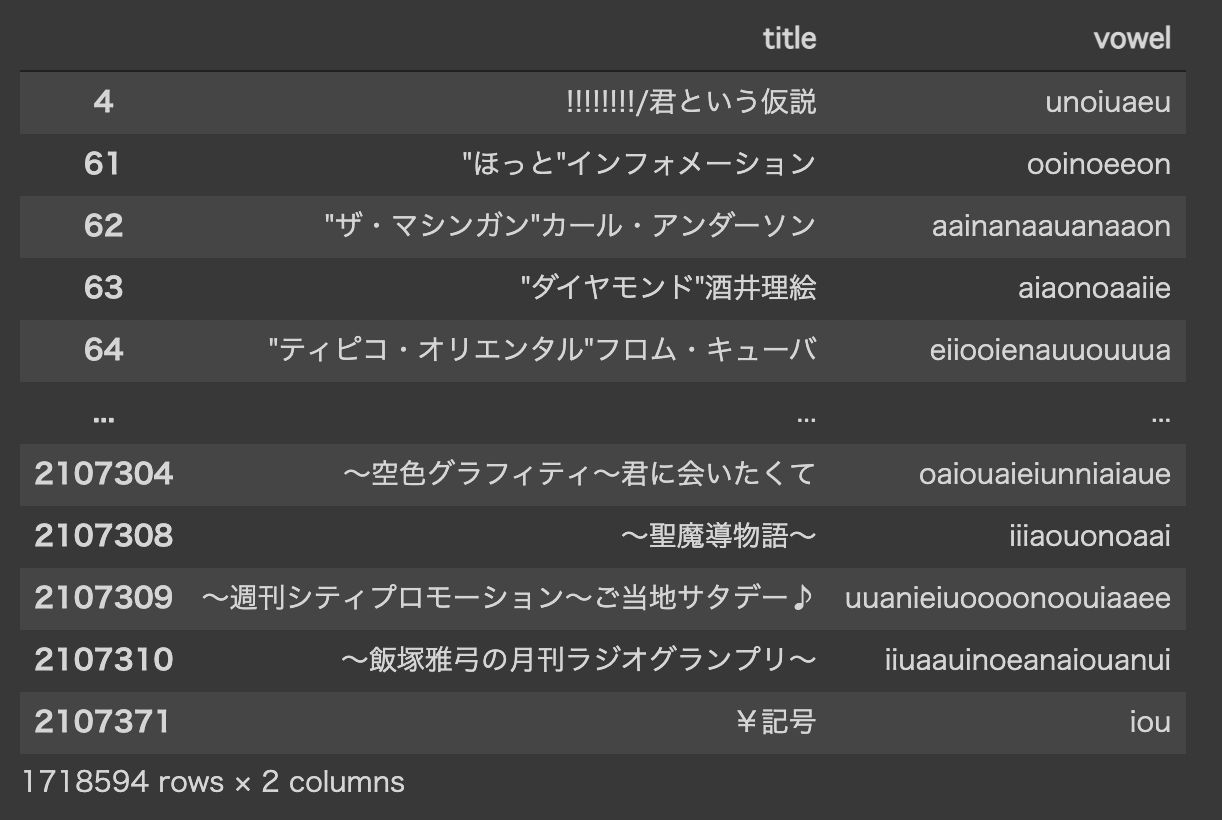 母音を抽出した`vowel`列ができています。
母音を抽出した`vowel`列ができています。
それではいよいよ大詰めです!
韻を踏む言葉を表示する関数をつくりましょう!
import random
def show_rhyming_words(input_text, df):
"""韻を踏む言葉を抽出する"""
input_romanize = romanize(input_text)
input_extract_vowel = extract_vowel(input_romanize)
tmp_list = df[
(df['vowel'].str.endswith(input_extract_vowel[-2:], na=False)) # 母音の最後の2文字が等しい
& (df['vowel'].str.len() == len(input_extract_vowel)) # 母音の文字数が等しい
]['title'].to_list()
for i in random.sample(tmp_list, 10):
print('{} {}'.format(input_text, i)) # ランダムに10コ表示
まず、input文字列をローマ字表記(input_romanize)し、さらに母音を抽出(input_extract_vowel)します。
そして、dataframeのvowel列と比較して、母音の最後の2文字が等しいかつ母音の文字数が等しいものを抽出します。
こうして得られたワードのリストから、ランダムに10コ表示するという関数になっています。
結果を〜セイッ!
それでは結果を見ていきましょう!
※10コの出力はランダムなので、実行するたびに結果は変わります。
コラーゲン☆主電源
「コラーゲン 主電源」の結果は以下になりました。
※入力は「コラーゲン」です(以下同様)。
input_text = 'コラーゲン'
show_rhyming_words(input_text, df)
# コラーゲン 饋電線
# コラーゲン クカス県
# コラーゲン ジム・バッケン
# コラーゲン ニトレン
# コラーゲン ボールペン
# コラーゲン 趙之謙
# コラーゲン 甲仙
# コラーゲン ジャッキー・チェン
# コラーゲン 処方せん
# コラーゲン 関和典
聞き慣れない単語も多く出ていますね。
この中でネタとして使えそうなのは「コラーゲン ボールペン」「コラーゲン 処方箋」ぐらいでしょうか。
「ジャッキー・チェン」も馴染みのある単語ですが、文字数が多くリズム感が少し損なわれそうです。
※「コラーゲン」の母音の数は5(koraagen→oaaen)、「ジャッキー・チェン」の母音の数も5(jakkii・chen→aiien)で一致。
ちなみに「饋電線(きでんせん)」「趙之謙(ちょうしけん)」「関和典(せきかずのり)」と読むようですが、最後の関和典はpykakasiで「典」を「てん」と読んでしまったようですね。
毛根☆ベーコン
「毛根 ベーコン」の結果は以下です。
input_text = '毛根'
show_rhyming_words(input_text, df)
# 毛根 亡魂
# 毛根 ローソン
# 毛根 カムオン
# 毛根 ピアソン
# 毛根 わおーん!
# 毛根 ヘブロン
# 毛根 天文
# 毛根 メイ・ロン
# 毛根 クルトン
# 毛根 みさぽん
ネタとして使えそうなのは「毛根 ローソン」「毛根 クルトン」かと思われます。
「メイ・ロン」は恐竜、「みさぽん」はおそらくアイドルの愛称だと思われます。
広辞苑☆中耳炎
最後に「広辞苑 中耳炎」です。
input_text = '広辞苑'
show_rhyming_words(input_text, df)
# 広辞苑 電波源
# 広辞苑 佐野県
# 広辞苑 ハヌッセン
# 広辞苑 清江苑
# 広辞苑 デリー県
# 広辞苑 慕輿虔
# 広辞苑 姚思廉
# 広辞苑 デロン県
# 広辞苑 三次元
# 広辞苑 ビビン麺
ネタになりそうなのは「広辞苑 三次元」「広辞苑 ビビン麺」といったところでしょうか。
「慕輿虔(ぼよけん)」「姚思廉(ようしれん)」は歴史上の人物のようです。
まとめ
ジョイマンのように韻を踏む単語を出力することができました!
しかし一方で、馴染みのない言葉も多く出てきていました。
今回はWikipediaのタイトルを使いましたが、馴染みがない単語は除外する、あるいは他の単語リストを使ってみるという方法が考えられます。
コメント等ございましたら
テルミー ショウミー