オートエンコーダー(Autoencoder)とは
- 教師なし学習
- 元の入力からニューラルネットワークを通して少ないノードに落とし、そこから再びニューラルネットワークで元の入力を復元するように学習
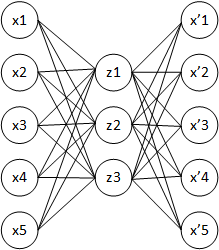
画像引用:A Tutorial on Autoencoders for Deep Learning
- 中間層で主成分分析のように次元削減・特徴抽出を行う
- 教師あり学習の事前学習として使われることもある
- AEと省略されることも
- 色々な派生がある
- Sparse Autoencoder
- Deep Fully-Connected Autoencoder
- Convolutional Autoencoder
- Denoising Autoencoder
- Stacked Autoencoder
- Variational Autoencoder
- Adversarial Autoencoder
シンプルなオートエンコーダー
以下にTFLearnを使った(Deep Fully-Connected)Autoencoderのサンプルがある
最後の描画部分を以下のように変更して画像を保存するようにした
from skimage import io
img = np.ndarray(shape=(28*10, 28*10))
for i in range(50):
row = i // 10 * 2
col = i % 10
img[28*row:28*(row+1), 28*col:28*(col+1)] = np.reshape(testX[i], (28, 28))
img[28*(row+1):28*(row+2), 28*col:28*(col+1)] = np.reshape(encode_decode[i], (28, 28))
img[img > 1] = 1
img[img < 0] = 0
img *= 255
img = img.astype(np.uint8)
io.imsave('decode.png', img)
元データが0~1のfloatだったので、その範囲にないものは0か1にしてしまったのだが、一般的にはこれでいいんだろうか?
実行結果

奇数行が元画像で、偶数行がそれに対応するデコードされた画像
題材をCIFAR10にしてみた
from __future__ import (
division,
print_function,
absolute_import
)
import numpy as np
import tflearn
from skimage import io
from tflearn.datasets import cifar10
(X, Y), (testX, testY) = cifar10.load_data()
encoder = tflearn.input_data(shape=[None, 32, 32, 3])
encoder = tflearn.fully_connected(encoder, 256)
encoder = tflearn.fully_connected(encoder, 64)
decoder = tflearn.fully_connected(encoder, 256)
decoder = tflearn.fully_connected(decoder, 32*32*3)
decoder = tflearn.reshape(decoder, (-1, 32, 32, 3))
net = tflearn.regression(decoder, optimizer='adam', learning_rate=0.001,
loss='mean_square', metric=None)
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(X, X, n_epoch=10, validation_set=(testX, testX),
run_id="auto_encoder", batch_size=256)
print("\nSaving results after being encoded and decoded:")
testX = tflearn.data_utils.shuffle(testX)[0]
encode_decode = model.predict(testX)
img = np.ndarray(shape=(32*10, 32*10, 3))
for i in range(50):
row = i // 10 * 2
col = i % 10
img[32*row:32*(row+1), 32*col:32*(col+1), :] = np.reshape(testX[i], (32, 32, 3))
img[32*(row+1):32*(row+2), 32*col:32*(col+1), :] = np.reshape(encode_decode[i], (32, 32, 3))
img = np.clip(img, 0., 1.)
img *= 255
img = img.astype(np.uint8)
io.imsave('decode.png', img)
実行結果

MNISTだとそこまではっきりとわからなかったが、CIFAR10だとボケてるのがわかる
最初の全結合層の後にドロップアウト0.5を入れてみる
実行結果

効果はイマイチのようだ
重み共有(tied weight)も試してみたかったが、TFLearnでのやり方がわからなかったので調査中
デノイジングオートエンコーダー
元画像にノイズ(ガウシアンノイズ)を足してオートエンコーダーを実行
ノイズ入りデータで訓練してノイズ入りデータでテストを実行するとそこそこ復元できるようなので、ノイズ入りデータで訓練してノイズなしデータでテストを実行してみた
nb_feature = 64
(X, Y), (testX, testY) = cifar10.load_data()
side = X.shape[1]
channel = X.shape[3]
noise_factor = 0.1
def addNoise(original, noise_factor):
noisy = original + np.random.normal(loc=0.0, scale=noise_factor, size=original.shape)
return np.clip(noisy, 0., 1.)
noisyX = addNoise(X, noise_factor)
net = tflearn.input_data(shape=[None, 32, 32, 3])
net = tflearn.fully_connected(net, 256)
net = tflearn.fully_connected(net, nb_feature)
net = tflearn.fully_connected(net, 256)
net = tflearn.fully_connected(net, 32*32*3, activation='sigmoid')
net = tflearn.reshape(net, (-1, 32, 32, 3))
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square', metric=None)
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(noisyX, X, n_epoch=10, validation_set=(testX, testX),
run_id="auto_encoder", batch_size=256)
print("\nSaving results after being encoded and decoded:")
testX = tflearn.data_utils.shuffle(testX)[0]
noisyTestX = addNoise(testX, noise_factor)
decoded = model.predict(testX)
img = np.ndarray(shape=(side*9, side*10, channel))
for i in range(30):
row = i // 10 * 3
col = i % 10
img[side*row:side*(row+1), side*col:side*(col+1), :] = testX[i]
img[side*(row+1):side*(row+2), side*col:side*(col+1), :] = noisyTestX[i]
img[side*(row+2):side*(row+3), side*col:side*(col+1), :] = decoded[i]
img *= 255
img = img.astype(np.uint8)
io.imsave('decode.png', img)
実行結果

特に意味はないが、ノイズをかけて(+ → *)みた
def addNoise(original, noise_factor):
noisy = original * np.random.normal(loc=1.0, scale=noise_factor, size=original.shape)
return np.clip(noisy, 0., 1.)
実行結果

ノイズのあるものとないものの両方で学習してみた
データ量が倍になるので、同じepoch数でもstepは倍になり、データを全部メモリに読み込むのでメモリも圧迫される
noisyX = addNoise(X, noise_factor)
mixedX = np.concatenate((X, noisyX))
X = np.concatenate((X, X))
model.fit(mixedX, X, n_epoch=10, validation_set=(testX, testX),
run_id="auto_encoder", batch_size=256)
実行結果

畳み込みオートエンコーダー
全結合層から畳み込み層に変更してみる
from __future__ import (
division,
print_function,
absolute_import
)
from six.moves import range
import numpy as np
import tflearn
from skimage import io
import tensorflow as tf
from tflearn.datasets import cifar10
nb_feature = 64
(X, Y), (testX, testY) = cifar10.load_data()
side = X.shape[1]
channel = X.shape[3]
def encoder(inputs):
net = tflearn.conv_2d(inputs, 16, 3, strides=2)
net = tflearn.batch_normalization(net)
net = tflearn.elu(net)
net = tflearn.conv_2d(net, 16, 3, strides=1)
net = tflearn.batch_normalization(net)
net = tflearn.elu(net)
net = tflearn.conv_2d(net, 32, 3, strides=2)
net = tflearn.batch_normalization(net)
net = tflearn.elu(net)
net = tflearn.conv_2d(net, 32, 3, strides=1)
net = tflearn.batch_normalization(net)
net = tflearn.elu(net)
net = tflearn.flatten(net)
net = tflearn.fully_connected(net, nb_feature)
net = tflearn.batch_normalization(net)
net = tflearn.sigmoid(net)
return net
def decoder(inputs):
net = tflearn.fully_connected(inputs, (side // 2**2)**2 * 32, name='DecFC1')
net = tflearn.batch_normalization(net, name='DecBN1')
net = tflearn.elu(net)
net = tflearn.reshape(net, (-1, side // 2**2, side // 2**2, 32))
net = tflearn.conv_2d(net, 32, 3, name='DecConv1')
net = tflearn.batch_normalization(net, name='DecBN2')
net = tflearn.elu(net)
net = tflearn.conv_2d_transpose(net, 16, 3, [side // 2, side // 2],
strides=2, padding='same', name='DecConvT1')
net = tflearn.batch_normalization(net, name='DecBN3')
net = tflearn.elu(net)
net = tflearn.conv_2d(net, 16, 3, name='DecConv2')
net = tflearn.batch_normalization(net, name='DecBN4')
net = tflearn.elu(net)
net = tflearn.conv_2d_transpose(net, channel, 3, [side, side],
strides=2, padding='same', activation='sigmoid',
name='DecConvT2')
return net
net = tflearn.input_data(shape=[None, side, side, channel])
net = encoder(net)
net = decoder(net)
net = tflearn.regression(net, optimizer='adam', loss='mean_square', metric=None)
model = tflearn.DNN(net, tensorboard_verbose=0, tensorboard_dir='tensorboard/',
checkpoint_path='ckpt/', best_checkpoint_path='best/')
model.fit(X, X, n_epoch=10, validation_set=(testX, testX),
run_id="auto_encoder", batch_size=128)
print("\nSaving results after being encoded and decoded:")
testX = tflearn.data_utils.shuffle(testX)[0]
decoded = model.predict(testX)
img = np.ndarray(shape=(side*10, side*10, channel))
for i in range(50):
row = i // 10 * 2
col = i % 10
img[side*row:side*(row+1), side*col:side*(col+1), :] = testX[i]
img[side*(row+1):side*(row+2), side*col:side*(col+1), :] = decoded[i]
img *= 255
img = img.astype(np.uint8)
io.imsave('decode.png', img)
実行結果

以下のコードを実行して、乱数からデコードしてみる
net = tflearn.input_data(shape=[None, nb_feature])
net = decoder(net)
model = tflearn.DNN(net)
model.load('./ckpt/-3910')
f = (np.random.rand(100, nb_feature) - 0.5) / 5 + 0.5
random = model.predict(f)
img = np.ndarray(shape=(side*10, side*10, channel))
for i in range(100):
row = i // 10
col = i % 10
img[side*row:side*(row+1), side*col:side*(col+1), :] = random[i]
img *= 255
img = img.astype(np.uint8)
io.imsave('random.png', img)
実行結果

何かしらの特徴を捉えているようで、結局よくわからないものが錬成された
全結合層のノード数1024

元の画像が32323=3072なので、ほとんど情報が落ちない
変分オートエンコーダー(Variational Autoencoder)
半教師あり学習・生成モデルに使えるオートエンコーダー
基本的なネットワーク構成は通常のオートエンコーダー
ネットワーク定義
from __future__ import (
division,
print_function,
absolute_import
)
from six.moves import range
import tensorflow as tf
import tflearn
def encode(incoming, intermediate_dim=None, latent_dim=None):
with tf.variable_op_scope([incoming], 'Encoder') as scope:
name = scope.name
net = tflearn.fully_connected(incoming, intermediate_dim)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, activation='relu')
net = tflearn.fully_connected(net, intermediate_dim)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, activation='relu')
net = tflearn.fully_connected(net, intermediate_dim)
net = tflearn.batch_normalization(net)
h = tflearn.activation(net, activation='relu', name='H')
mean = tflearn.fully_connected(h, latent_dim, name='Mean')
log_var = tflearn.fully_connected(h, latent_dim, name='LogVariance')
std = tf.exp(0.5 * log_var, name='StandardDeviation')
epsilon = tf.random_normal(tf.shape(log_var), name='Epsilon')
z = tf.add(mean, tf.mul(std, epsilon), name='SampleLatentVariable')
tf.add_to_collection(tf.GraphKeys.LAYER_TENSOR + '/' + name, z)
return z, mean, log_var
def decode(incoming, intermediate_dim=None, original_shape=None):
with tf.variable_op_scope([incoming], 'Decoder') as scope:
name = scope.name
net = tflearn.fully_connected(incoming, intermediate_dim)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, activation='relu')
net = tflearn.fully_connected(net, intermediate_dim)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, activation='relu')
net = tflearn.fully_connected(net, intermediate_dim)
net = tflearn.batch_normalization(net)
h = tflearn.activation(net, activation='relu', name='H')
mean = tflearn.fully_connected(h, original_shape[0], activation='sigmoid',
name='Mean')
tf.add_to_collection(tf.GraphKeys.LAYER_TENSOR + '/' + name, mean)
return mean
エンコーダー
from __future__ import (
division,
print_function,
absolute_import
)
from six.moves import range
import tensorflow as tf
import tflearn
import vae
from tflearn.datasets import mnist
import numpy as np
from skimage import io
batch_size = 128
latent_dim = 2
intermediate_dim = 512
X, Y, testX, testY = mnist.load_data()
original_shape = X.shape[1:]
original_shape = [original_shape[i] for i in range(len(original_shape))]
input_shape = [None] + original_shape
x = tflearn.input_data(shape=input_shape)
z, z_mean, z_log_var = vae.encode(x, intermediate_dim=intermediate_dim,
latent_dim=latent_dim)
x_decoded_mean = vae.decode(z, intermediate_dim=intermediate_dim,
original_shape=original_shape)
def vae_loss(y_pred, y_true):
with tf.variable_op_scope([y_pred, y_true], 'Loss') as scope:
name = scope.name
binary_cross_entropy_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(y_pred, y_true), reduction_indices=1)
kullback_leibler_divergence_loss = - 0.5 * tf.reduce_sum(1 + z_log_var - tf.pow(z_mean, 2) - tf.exp(z_log_var), reduction_indices=1)
loss = tf.reduce_mean(binary_cross_entropy_loss + kullback_leibler_divergence_loss)
tf.add_to_collection(tf.GraphKeys.LAYER_TENSOR + '/' + name, loss)
return loss
vae = tflearn.regression(x_decoded_mean, optimizer='adam', loss=vae_loss,
metric=None)
vae = tflearn.DNN(vae, tensorboard_verbose=0,
checkpoint_path='model_variational_autoencoder',
max_checkpoints=10)
vae.fit(X, X, n_epoch=100, batch_size=batch_size,
run_id='varational_auto_encoder')
ジェネレーター
from __future__ import (
division,
print_function,
absolute_import
)
from six.moves import range
import tensorflow as tf
import tflearn
from tflearn.datasets import mnist
import vae
import numpy as np
from skimage import io
original_dim = 784
latent_dim = 2
intermediate_dim = 512
model_file = 'model_variational_autoencoder-43000'
X, Y, testX, testY = mnist.load_data()
original_shape = X.shape[1:]
original_shape = [original_shape[i] for i in range(len(original_shape))]
with tf.Graph().as_default():
input_shape = [None] + original_shape
x = tflearn.input_data(shape=input_shape)
z, mean, logvar = vae.encode(x, intermediate_dim=intermediate_dim,
latent_dim=latent_dim)
encoder = tflearn.DNN(z)
optargs = {'scope_for_restore':'Encoder'}
encoder.load(model_file, optargs)
mean_encoder = tflearn.DNN(mean)
mean_encoder.load(model_file, optargs)
logvar_encoder = tflearn.DNN(logvar)
logvar_encoder.load(model_file, optargs)
with tf.Graph().as_default():
# build a digit generator that can sample from the learned distribution
decoder_input = tflearn.input_data(shape=[None, latent_dim])
gen_decoded_mean = vae.decode(decoder_input, intermediate_dim=intermediate_dim,
original_shape=original_shape)
generator = tflearn.DNN(gen_decoded_mean)
generator.load(model_file, {'scope_for_restore':'Decoder'})
digit_size = 28
n = 15
linspace = 1000
figure = np.zeros((digit_size * n, digit_size * n))
grid_x = np.linspace(-linspace, linspace, n)
grid_y = np.linspace(-linspace, linspace, n)
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi] + [0 for k in range(2, latent_dim)]])
x_decoded = generator.predict(z_sample)
digit = np.reshape(x_decoded[0], [digit_size, digit_size])
figure[i * digit_size : (i + 1) * digit_size,
j * digit_size : (j + 1) * digit_size] = digit
figure *= 255
figure = figure.astype(np.uint8)
io.imsave('vae_z.png', figure)
figure = np.ndarray(shape=(digit_size * (n), digit_size * (n)),
dtype=np.float16)
testX = tflearn.data_utils.shuffle(X)[0][0:1]
testMean = mean_encoder.predict(testX)[0]
testLogVar = logvar_encoder.predict(testX)[0]
std = [np.exp(0.5 * testLogVar[i]) * 4 for i in range(2)]
grid_x = np.linspace(-std[0], std[0], n) + testMean[0]
grid_y = np.linspace(-std[1], std[1], n) + testMean[1]
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z_sample = np.array([[xi, yi] + [testMean[k] for k in range(2, latent_dim)]])
x_decoded = generator.predict(z_sample)
digit = np.reshape(x_decoded[0], [digit_size, digit_size])
figure[i * digit_size : (i + 1) * digit_size,
j * digit_size : (j + 1) * digit_size] = digit
figure *= 255
figure = figure.astype(np.uint8)
io.imsave('vae_std.png', figure)
変更する際にエンコーダーとジェネレーター両方の変数を一致するように変更するのも面倒なので、vae.pyにまとめてしまってもいいかもしれない
コードは間違っているところがあるかもしれない。(特に損失関数のところ)
参考にしたのは以下
Building Autoencoders in Keras
Variational Autoencoder in TensorFlow
上のコードを実行して得られたのが以下
vae_z.png(zの値を直接変化させた)
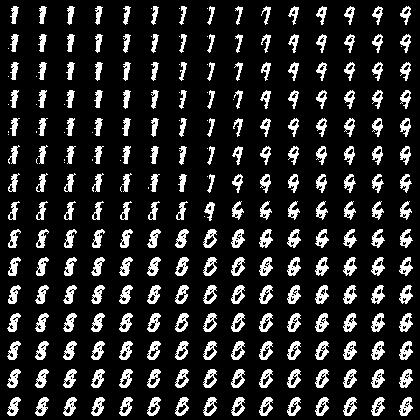
vae_std.png(サンプルをエンコードして得たmean・stdを基準にzを変化させた)
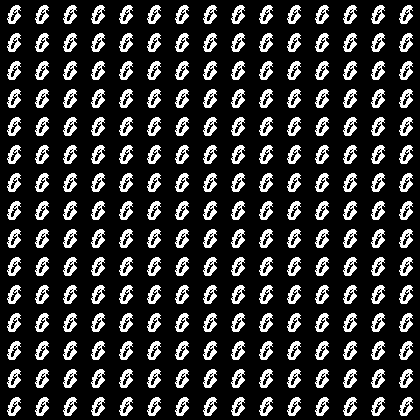
ネットワーク構成は普通のオートエンコーダーだけど、エンコード部分の学習対象と損失関数に特徴がある。
エンコード部分が学習しているのは平均($mean$)と分散の対数($logvar$)。
そこから潜在変数$z$を以下のようにして求める。
$z = mean + std * epsilon$
| 変数名 | |
|---|---|
| $z$ | 潜在変数 |
| $mean$ | 平均 |
| $std$ | 標準偏差($\sqrt{e^{logvar}}$) |
| $epsilon$ | 標準正規分布からランダムに選んだ値 |
損失関数は交差エントロピー($BinaryCrossEntropyLoss$) + カルバック・ライブラー情報量($KullbackLeiblerDivergenceLoss$)で表される。
上で紹介したKeras実装のページにはカルバック・ライブラー情報量は正則化項で、なくても動くには動くと書いてある。
カルバックライブラー情報量というのは、2つの確率分布の差を表す指標(wikipedia)。
完全には理解していないが、詳しい内容は以下あたりを参考に。
猫でも分かるVariational AutoEncoder
Variational Autoencoderでアルバムジャケットの生成
Variational Autoencoder(VAE)で生成モデル
Semi-Supervised Learning with Deep Generative Models [arXiv:1406.5298] - ご注文は機械学習ですか?
Auto-Encoding Variational Bayes [arXiv:1312.6114] - ご注文は機械学習ですか?
潜在変数モデルと学習法に関して
変分オートエンコーダーは生成モデルとして使えると聞いていて、サンプルを探すと上のものが出てくるが、これはM1モデルというらしい。生成モデルや半教師あり学習に利用するには、M2モデルというのも必要。
~~次はM2モデルを実装したい。~~実装完了
変分オートエンコーダー(M2)
エンコーダー・デコーダー共に入力に正解ラベル情報を加えたもの
Conditional Variational Autoencoderと同じ?
Conditional Variational Autoencoder (CVAE)
cvae
以下を参考に実装した
chainer-Variational-AutoEncoder
from __future__ import (
division,
print_function,
absolute_import
)
from six.moves import range
import tensorflow as tf
import tflearn
from tflearn.datasets import mnist
import os
import numpy as np
from skimage import io
input_data = tflearn.input_data
fc = tflearn.fully_connected
bn = tflearn.batch_normalization
activation = tflearn.activation
merge = tflearn.merge
regression = tflearn.regression
DNN = tflearn.DNN
VAR_FILE = 'vae_variables'
RECOGNITION_OPTARGS = {'scope_for_restore':'Recognition'}
GENERATIVE_OPTARGS = {'scope_for_restore':'Generative'}
class VAE2():
def __init__(self, hidden_recognition_layers, hidden_generation_layers,
n_z):
self.hidden_recognition_layers = hidden_recognition_layers
self.hidden_generation_layers = hidden_generation_layers
self.n_z = n_z
self.training_graph = tf.Graph()
self.recognition_graph = tf.Graph()
self.generative_graph = tf.Graph()
self.training_model = None
self.recognition_model = None
self.generative_model = None
def _get_recognition_model(self, input_x, input_y, activation_recognition):
with tf.variable_op_scope([input_x, input_y], 'Recognition') as scope:
name = scope.name
rec_x = fc(input_x, self.hidden_recognition_layers[0], name='X')
rec_y = fc(input_y, self.hidden_recognition_layers[0], name='Y')
# compute q(z|x, y)
rec_hidden = merge([rec_x, rec_y], 'elemwise_sum')
rec_hidden = activation(rec_hidden, activation_recognition)
for n in self.hidden_recognition_layers[1:]:
rec_hidden = fc(rec_hidden, n)
rec_hidden = bn(rec_hidden)
rec_hidden = activation(rec_hidden, activation_recognition)
rec_mean = fc(rec_hidden, self.n_z, name='Mean')
rec_log_sigma = fc(rec_hidden, self.n_z, name='LogVar')
rec_std = tf.exp(rec_log_sigma, name='StandardDeviation')
rec_eps = tf.random_normal(tf.shape(rec_log_sigma), name='Epsilon')
rec_z = tf.add(rec_mean, tf.mul(rec_std, rec_eps),
name='SampleLatentVariable')
tf.add_to_collection(tf.GraphKeys.LAYER_TENSOR + '/' + name, rec_z)
return rec_z, rec_mean, rec_log_sigma
def _get_generative_model(self, input_y, input_z, x_dim,
activation_generative, activation_output):
with tf.variable_op_scope([input_y, input_z], 'Generative') as scope:
name = scope.name
gen_y = fc(input_y, self.hidden_generation_layers[0], name='Y')
gen_z = fc(input_z, self.hidden_generation_layers[0], name='Z')
gen_z = bn(gen_z)
# compute q(x|y, z)
gen_hidden = merge([gen_y, gen_z], 'elemwise_sum')
gen_hidden = activation(gen_hidden, activation_generative)
for n in self.hidden_generation_layers[1:]:
gen_hidden = fc(gen_hidden, n)
gen_hidden = bn(gen_hidden)
gen_hidden = activation(gen_hidden, activation_generative)
gen_hidden = fc(gen_hidden, x_dim)
gen_output = activation(gen_hidden, activation_output)
tf.add_to_collection(tf.GraphKeys.LAYER_TENSOR + '/' + name, gen_output)
return gen_output
def _get_model(self, x_dim, y_dim, activation_recognition,
activation_generative, activation_output):
input_x = input_data(shape=(None, x_dim), name='inputX')
input_y = input_data(shape=(None, y_dim), name='inputY')
z, mean, log_sigma = self._get_recognition_model(input_x, input_y,
activation_recognition)
output = self._get_generative_model(input_y, z, x_dim,
activation_generative,
activation_output)
def loss_func(prediction, truth):
reconstruction_loss = tf.reduce_sum(
tf.nn.sigmoid_cross_entropy_with_logits(prediction, truth),
reduction_indices=1)
kullback_leibler_divergence = - 0.5 * tf.reduce_sum(
1 + log_sigma - tf.pow(mean, 2) - tf.exp(log_sigma),
reduction_indices=1)
loss = tf.reduce_mean(reconstruction_loss +
kullback_leibler_divergence)
return loss
model = regression(output, optimizer='adam', loss=loss_func)
model = DNN(model, tensorboard_verbose=0,
checkpoint_path='variational_autoencoder',
max_checkpoints=10)
return model
def set_recognition_model(self, x_dim, y_dim,
activation_recognition='softplus'):
with self.recognition_graph.as_default():
input_x = input_data(shape=(None, x_dim), name='inputX')
input_y = input_data(shape=(None, y_dim), name='inputY')
model, _, _ = self._get_recognition_model(input_x, input_y,
activation_recognition)
self.recognition_model = DNN(model)
def set_generative_model(self, y_dim, output_dim,
activation_generative='relu',
activation_output='sigmoid'):
with self.generative_graph.as_default():
input_y = input_data(shape=(None, y_dim), name='inputY')
input_z = input_data(shape=(None, self.n_z), name='inputZ')
model = self._get_generative_model(input_y, input_z, output_dim,
activation_generative,
activation_output)
self.generative_model = DNN(model)
def load_recognition_model(self):
with self.recognition_graph.as_default():
self.recognition_model.load(VAR_FILE, RECOGNITION_OPTARGS)
def load_generative_model(self):
with self.generative_graph.as_default():
self.generative_model.load(VAR_FILE, GENERATIVE_OPTARGS)
def train(self, x, y, activation_recognition='softplus',
activation_generative='relu', activation_output='sigmoid'):
x_dim, y_dim = x.shape[1], y.shape[1]
# train
with self.training_graph.as_default():
if self.training_model == None:
self.training_model = \
self._get_model(x_dim, y_dim, activation_recognition,
activation_generative, activation_output)
if os.path.exists(VAR_FILE):
self.training_model.load(VAR_FILE, RECOGNITION_OPTARGS)
self.training_model.load(VAR_FILE, GENERATIVE_OPTARGS)
self.training_model.fit({'inputX':x, 'inputY':y}, x, n_epoch=10,
batch_size=128, snapshot_epoch=False,
snapshot_step=5000,
run_id='variational_autoencoder')
self.training_model.save(VAR_FILE)
# set recognition model
if self.recognition_model == None:
self.set_recognition_model(x_dim, y_dim,
activation_recognition=activation_recognition)
self.load_recognition_model()
# set generative model
if self.generative_model == None:
self.set_generative_model(y_dim, x_dim,
activation_generative=activation_generative,
activation_output=activation_output)
self.load_generative_model()
def get_z(self, x, y, activation_recognition='softplus',
activation_output='sigmoid'):
with self.recognition_graph.as_default():
return self.recognition_model.predict({'inputX':x, 'inputY':y})
def generate(self, x_dim, y, z, activation_generative='relu',
activation_output='sigmoid'):
with self.generative_graph.as_default():
return self.generative_model.predict({'inputY':y, 'inputZ':z})
X, Y, testX, testY = mnist.load_data(one_hot=True)
digit_size = np.sqrt(X.shape[1]).astype(np.uint8)
vae2 = VAE2([500, 500], [500, 500], 16)
vae2.train(X, Y)
sample = np.random.choice(testX.shape[0], 11)
sampleX = np.array([testX[i] for i in sample])
sampleY = np.array([testY[i] for i in sample])
sampleZ = np.array(vae2.get_z(sampleX, sampleY))
input_y = np.ndarray(shape=(110, sampleY.shape[1]))
input_z = np.ndarray(shape=(110, sampleZ.shape[1]))
input_y = np.tile(tflearn.data_utils.to_categorical(np.arange(10.), 10), (11, 1))
for i in range(11):
input_z[i * 10 : (i+1) * 10] = np.tile(sampleZ[i : i+1], (10, 1))
figure = np.ndarray(shape=(digit_size * 11, digit_size * 11), dtype=np.float16)
decoded = vae2.generate(sampleX.shape[1], input_y, input_z)
for y in range(11):
digit = np.reshape(sampleX[y], (digit_size, digit_size))
figure[y * digit_size : (y + 1) * digit_size, 0 : digit_size] = digit
for x in range(10):
digit = np.reshape(decoded[y * 10 + x], (digit_size, digit_size))
figure[ y * digit_size : (y + 1) * digit_size,
(x + 1) * digit_size : (x + 2) * digit_size] = digit
figure *= 255
figure = figure.astype(np.uint8)
io.imsave('vae2.png', figure)
実行結果
一番左がテストデータから選んだ画像で、その右にあるのがテストデータから取り出した潜在変数zを用いて生成した0~9までの画像
10epoch

20epoch

30epoch
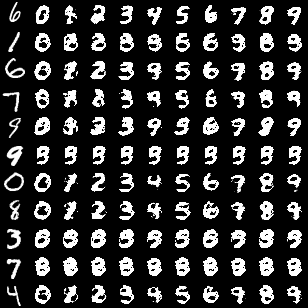
100epoch

参考
TensorFlowで機械学習と戯れる: AutoEncoderを作ってみる
TensorFlowでAutoencoderを実装してみた
Building Autoencoders in Keras
Theanoによる自己符号化器の実装