Azure Machine Learningをわかった気になるために細かいことは気にせずに機械学習のことをまとめてみる - ディープラーニングの手前までの続き
ディープラーニング(深層学習)とは
wikipediaによると
多層構造のニューラルネットワークの機械学習の事。
うん、わからん。
そもそもニューラルネットワークとは?
脳機能に見られるいくつかの特性を計算機上のシミュレーションによって表現することを目指した数学モデルである。研究の源流は生体の脳のモデル化であるが、神経科学の知見の改定などにより次第に脳モデルとは乖離が著しくなり、生物学や神経科学との区別のため、人工ニューラルネットワークとも呼ばれる。
どうやら「人間の脳を再現した」とか言うとマサカリが飛んでくるらしい正確ではないので、「人間の脳にインスパイアされて」とでも言ったほうがいいらしい。
でも、まだわからないので調べてみた。
まず、脳にはこういう感じのニューロンがある。
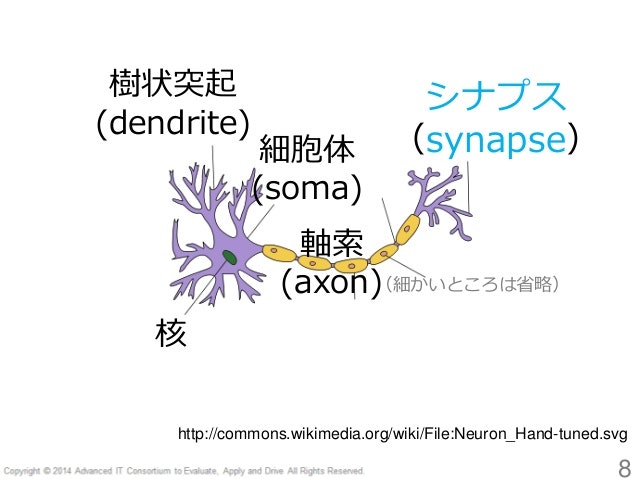
画像引用:ニューラルネットワーク ことはじめ
ニューロンは、複数のニューロンから刺激を受けて、その刺激が一定量を超えると発火し、次の複数のニューロンに刺激を伝えるらしい。
このニューロンにはそれぞれ個性があり、特定の刺激に反応しやすかったり、反応しにくかったりして、全部のニューロンが一度に発火するわけではない。
ちなみに、今言ったことは嘘だ現代の神経科学的知見からすると誤っているかもしれないが、ニューラルネットワークを理解したいだけなので、細かいことは気にしない。
このニューロンにオマージュされて生まれたのがパーセプトロン。
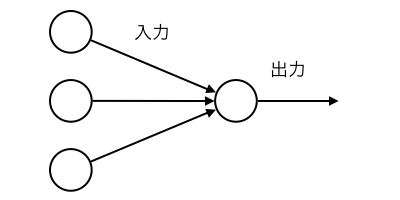
画像引用:高卒でもわかる機械学習 (2) 単純パーセプトロン
入力信号を足していって、一定値を超えなければ0、超えていれば1を出力する。
ニューロンごとの個性というやつはどこへ行ったのかというと、実はこのパーセプトロン、入力信号をゴニョゴニョ弄っている。入力信号xに重みWをかけて、出力信号yを出している。つまり一定値をb(バイアス)とすると、
y = f(x);
function f(x) {
s = 0;
for(i = 0; i < x.length; i++) {
// Wはインスタンス変数
s += W[i] * x[i];
}
s += b;
if (s > 0) {
return 1;
} else {
return 0;
}
}
これだけだ。1(使ってる言語がアレで書き方も微妙かもしれないが、Pythonのlenもアレだし最大公約数的に誰にでもわかるように書くとするとこうなるだろう)
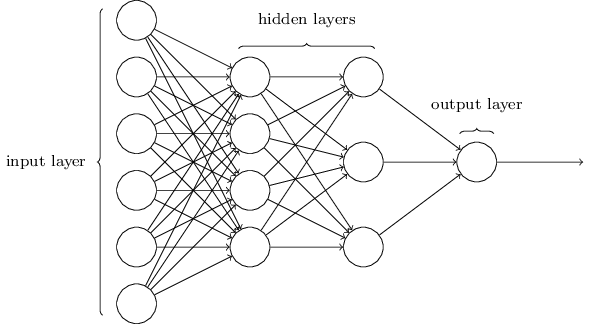
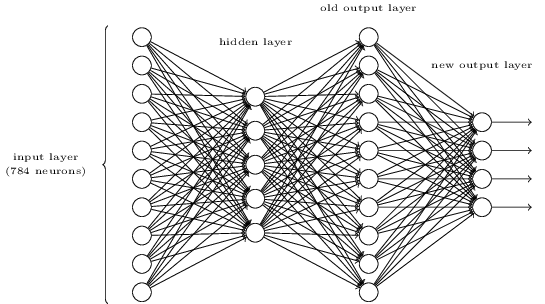
そしてニューラルネットワークというのは、このパーセプトロンが並列に並んだ層を複数重ねたもの。
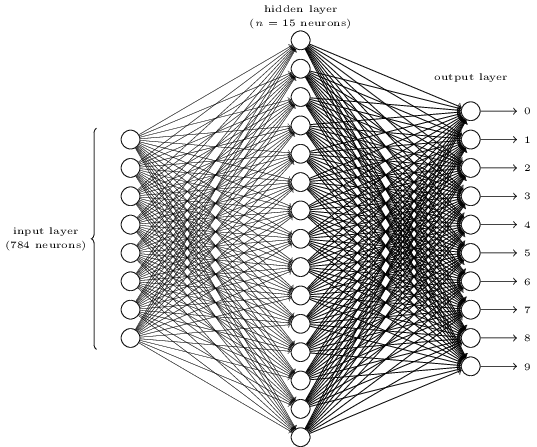
実際には、とても図式化できるものではない(下はMNISTの例で、入力層 = input layerには784個のノードがある)
ところで、脳というのは以下のような感じで単純な刺激に反応するニューロンの組み合わせで次第に複雑なものを認識していると考えられている。

画像引用:ディープラーニング
これを応用して、ニューラルネットワークの隠れ層 = hidden layerを多層構造にしたら識別率が上がるんじゃないかと考えられたのだが、色んな理由で上手くいかなかった。
そこで、隠れ層1層のニューラルネットワークなら上手くいってるんだし、それを単位として複数重ねたらいいんじゃないかという安直な革新的なアイデアから生まれたのがディープラーニング。(実際にはそうしたらいいというのは昔からわかっていて、リソースが足りず実現できなかったために長らく日の目を見なかったらしい)
とりあえず、以上が調べてみてディープラーニングについてわかったことだけど、多分に間違っている可能性はある。
Net#について
Microsoftが作ったAzure Machine Learning用のDSL。やたらと独自言語・DSLを量産するのはやめてほしい
Azure Machine Learningで複雑なディープラーニングを実行しようとすると避けては通れない。
Net#の解説
Azure Machine Learning のための Net# ニューラル ネットワーク仕様言語について
Guide to Net# neural network specification language for Azure Machine Learning
バンドルとは
- ソースレイヤーとソースレイヤーへの結合の仕様で構成される。
- 隠れ層と出力層はそれぞれ1つ以上のバンドルを持つ。
- 同じバンドル内の全ての結合は同一のソースレイヤーとデスティネーションレイヤーを共有。
- Net#において、バンドルはデスティネーションレイヤーに属する。
Net#のソースコードの構成
以下のセクションで構成され、順序を問わない。
- 定数宣言(オプション)
- レイヤー宣言・バンドル定義(必須)
- 重みの共有宣言(オプション)
定数宣言
以下のような感じで定数を宣言できる。
Const X = 28;
Const { X = 28; Y = 4; }
Const { X = 17 * 2; Y = true; }
レイヤー宣言・バンドル定義
(レイヤー種類) (名前)[次元を表すタプル]
のように宣言する
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
次元の積は、そのレイヤーのノード数。(Hiddenレイヤーのノード数は 5 * 20 = 100)
入力層を複数定義する場合以外は、定義の順番は関係ない。(常識的なコードを書いてる限りは順番に定義すると思うので、あまり意識することはない)
autoキーワードは、レイヤーのノード数を自動的に決定するが、使われるレイヤーによって挙動が異なる。
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
- 入力層では、入力データの特徴量になる
- 隠れ層では、hidden nodes数のパラメーター値により決定
- 出力層では、出力ノード数(2クラス分類なら2、回帰なら1)になる
隠れ層・出力層では、以下の活性化関数を指定できる。
既定値は、分類ならsigmoid、回帰ならlinear
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
output Result [100] softmax from Hidden all;
隠れ層・出力層のレイヤー宣言は、直後に続けてバンドルを定義しないといけない。
バンドルは、fromキーワードの後にソースレイヤーとバンドルの種類を記述して定義する。
バンドルの種類は以下の通り。
- Full bundle (all) - ソースレイヤーの各ノードがデスティネーションレイヤーの全ノードと結合(既定値)
- Filtered bundle (where) - ソースレイヤーやデスティネーションレイヤーのノードを指定して結合
- Convolutional bundle (convolve) - ソースレイヤーの各ノードの小さな近接領域を指定し、デスティネーションレイヤーの各ノードはソースレイヤーの1つの近接領域に結合
- Pooling bundle (max pool / mean pool) - 予め決められた方法でソースレイヤーのノード値からデスティネーションレイヤーのノード値を決定
- Response normalization bundle (response norm)
Full bundle(全結合)
ソースレイヤーの各ノードが、デスティネーションレイヤーの各ノードにつながる
Filtered bundle(選択結合)
条件に応じて選択的にノードがつながる
下の例の場合、
src[0]はPixelsの1つ目の次元(0 <= src[0] < 10)
src[1]はPixelsの2つ目の次元(0 <= src[1] < 20)
ByRowのdst[0]はByRowの1つ目の次元(0 <= dst[0] < 10)
ByRowのdst[1]はByRowの2つ目の次元(0 <= dst[1] < 12)
ByColのdst[0]はByColの1つ目の次元(0 <= dst[0] < 5)
ByColのdst[1]はByColの2つ目の次元(0 <= dst[1] < 20)
を表す
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (src, dst) => src[0] == dst[0];
hidden ByCol[5, 20] from Pixels where (src, dst) => abs(src[1] - dst[1]) <= 1;
つまり、この場合つながっているのは一般的なプログラミング言語風に記述すると
// ByRow
Pixels.map(function(srcArrayY, srcIndexX) {
srcArrayY.map(function(srcNode, srcIndexY) {
ByRow.map(function(dstArrayY, dstIndexX) {
dstArrayY.map(function(dstNode, dstIndexY) {
if (srcIndexX = dstIndexX) connect;
});
});
});
});
// ByCol
Pixels.map(function(srcArrayY, srcIndexX) {
srcArrayY.map(function(srcNode, srcIndexY) {
ByCol.map(function(dstArrayY, dstIndexX) {
dstArrayY.map(function(dstNode, dstIndexY) {
if (srcIndexY - dstIndexY <= 1) connect;
});
});
});
});
となる。
connectと書いてある部分がやっているのは、srcNodeに重みWをかけて足し合わせるという作業。
デフォルトでは重みはランダムに生成されるが、指定することもできる。ただし、重みの定義の仕方は書いてあってもどこでどのように適用するのか書いてなかったので省略。
Convolutional bundle(畳み込み)
画像・音声・映像など空間・時間的に均質なデータに使われる。(画像や音声解析が多い気がする。映像や自然言語処理など、前のデータを後のデータの学習でも考慮に入れたほうがいい場合には再帰型ニューラルネットワーク = Recurrent Neural Networkを使うっぽい)
畳み込みというのは以下のように、元データのサイズよりも小さいカーネルをスライドさせて、特徴を抽出する。それぞれのカーネルごとに重みを持っている。(下の例だと、Xのような形への類似度が特徴として抽出されている)
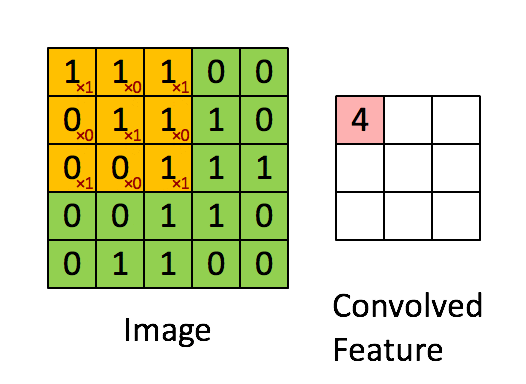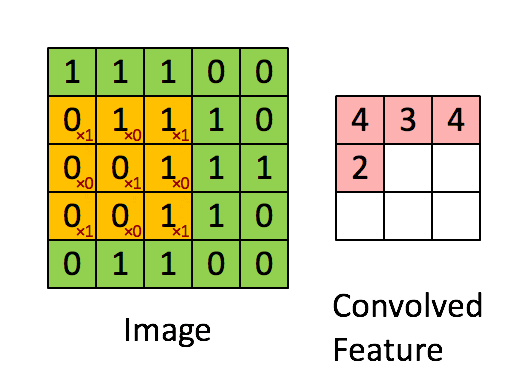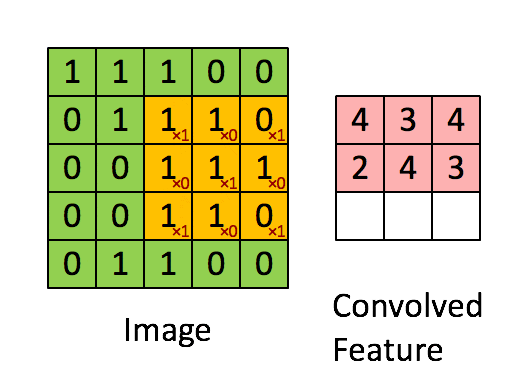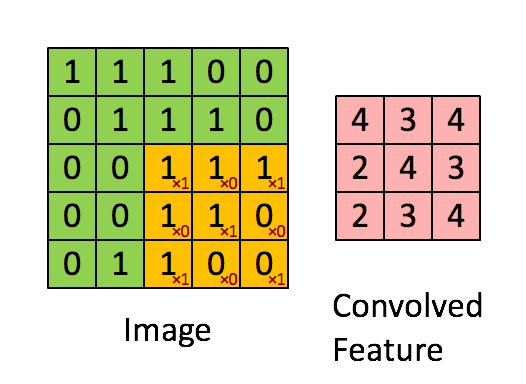
画像引用:深層畳み込みニューラルネットワークを用いた画像スケーリング
Covolutional bundleは、以下のように定義する。
const { T = true; F = false; }
input Picture [28, 28];
hidden C1 [5, 12, 12]
from Picture convolve {
InputShape = [28, 28];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden C2 [50, 4, 4]
from C1 convolve {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [ F, T, T];
MapCount = 10;
}
hidden H3 [100]
from C2 all;
output Result [10] softmax
from H3 all;
Convolutional bundleで定義できるのは以下の項目。
| 属性 | 必須 | 説明 |
|---|---|---|
| InputShape | ○ | バンドルで利用するソースレイヤーの次元。次元の積の値はソースレイヤーのノード数と一致しなければならないが、ソースレイヤーの次元と一致する必要はない。(ソースレイヤー2828->InputShape1414*4でもいい) |
| KernelShape | ○ | カーネルの次元。カーネルの次元数(タプルのlength)は、バンドルの次元数(InputShapeのタプルのlength)と一致しなければならない。 |
| Stride | それぞれの次元方向へのステップ値。ストライドの次元数(タプルのlength)は、バンドルの次元数と一致しなければならない。タプルの中のそれぞれの値は、対応するKernelShapeのタプルの値を超えてはいけない。既定値は1。 | |
| Sharing | 畳み込みのそれぞれの次元で重みを共有するかどうかの真偽値。1つだけ真偽値が指定された場合は、全次元に同じものが適用され、タプルで指定された場合は、それぞれ対応する時点に適用される。既定値はTrue。 | |
| MapCount | バンドルの特徴マップの数を定義。単一の整数またはバンドルの次元数と等しい長さの整数のタプル。単一の整数値が指定された場合は、その整数の後に1が続くタプルに拡張される。 | |
| Weights | 重みの初期値。カーネル数にカーネルごとの重みの数をかけた値と等しい長さの浮動小数点のタプル。既定値はランダム生成。 | |
| Padding | ソースの各次元とカーネル・ストライドがうまく一致しない場合の調整方法。単一の真偽値またはバンドルの次元数と等しい長さの真偽値のタプル。単一の真偽値が指定された場合は、全てが同じ真偽値のタプルに拡張される。Trueの場合は、(InputShape[d] - 1) / Stride[d] + 1個のカーネルが収まるように、ソースレイヤーのd次元の最初や最後に0を追加して調整。Falseの場合は、ソースレイヤーのd次元の最初や最後の各側で余るノードができるだけ等しくなるようにカーネルを調整。この項目を定義するとUpperPadやLowerPadは定義できない。 | |
| UpperPad または LowerPad | Paddingを定義していない場合に定義可能。Paddingよりも詳細に調整方法を指定。バンドルの次元数と等しい長さの整数値のタプル。 |
MapCountというのはよくわからないけど、MNISTの以下のような特徴を抽出するフィルタの数かと思う。

画像引用:ディープラーニング-畳み込みニューラルネットワークとPythonによる特徴抽出
入力画像に対して重みフィルタを畳み込み処理する.この畳み込み処理の出力はマップ状に出力される.この出力されたマップを特徴マップと呼ぶ
Convolutional Neural Networkの特徴抽出過程における不変性獲得の調査
よくわからん。
Pooling bundle(プーリング)
プーリング バンドルは、畳み込みの結合性と同様の幾何学構造を適用しながら、ソース ノード値に事前定義された関数を使用して、宛先ノード値が派生するようにします。このため、プーリング バンドルにはトレーニング可能な状態 (重みまたはバイアス) はありません。プーリング バンドルは、Sharing、MapCount、Weights を除くすべての畳み込み属性をサポートします。
と、何言ってるのかよくわからないが、やってることはConvolutional bundleで抽出された特徴をまとめて、多少の位置づれに強くしたり、計算量を減らしているらしい。
一般的な畳み込みニューラルネットワークではStrideとKernelShapeが等しい。
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
Response normalization bundle(応答正規化)
あるニューロンが高度な活性レベルで発火しているときに、ローカルな応答正規化層によって周囲のニューロンの活性レベルを抑えます。
やっぱりよくわからないが、以下のGlobal Contrast Normalizationが全ての画像のコントラストを正規化しているのと対比すると、同じ位置に対する複数の特徴マップのうちある特徴マップだけが強く反応している時に、それに他の特徴マップが引きずられないようにしているらしい。

画像引用:MIRU2014 tutorial deeplearning
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
重みの共有宣言
共有の重みを持つ複数のバンドルを宣言できる。
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // 重みとバイアスを共有
-
バイアス項の経緯とかは実際には違うかもしれないが、イメージとして捉えるには問題ないと思う。あと重みの値はマイナスもあり得て、それがニューラルネットワークが多層になったときにXORなどの複雑な条件の識別を可能にするみたい。 ↩