先日、2016年アドベントカレンダーのはてブ数の分析というブログ記事を投稿した。このデータの可視化には様々な技術が使われている。本記事では、どのような技術を活用して作成したのかについて説明する。
ソースコードはこちら。
概要
このVizは、QiitaとAdventarに投稿された、全アドベントカレンダー及びそこに登録された記事のはてなブックマーク数を元に、どのカレンダーや記事が人気なのか、あるいはQiitaとAdventarのどちらが人気なのかを視覚化することを目的として作成された。データソースは、Qiita及びAdventarに登録された、アドベントカレンダー2016の全カレンダーページである。カレンダーには記事のメタデータが含まれている。記事そのもののページやユーザページのクロールはしていない。
システムの概要
データの収集→ETL→BIという流れで処理を行った。
データ収集
Webクローリングにより、全カレンダーページに含まれているデータを収集する。
WebクローラにはScrapyを用いた。
ETL処理
収集したデータをBIで読みやすい形式に変換する。
ETL処理にはPentaho Data Integrationを用いた。
BI
精製されたデータを集計・可視化する。
BIツールにはTableau Publicを用いた。
主要技術紹介
Scrapy
ScrapyはPython製のWebクローラで、基本的なPythonの知識とCSSセレクタの知識(あるいはrequestsやBeautifulSoup等の知識)があれば簡単にWebクローラを作成することができる。
公式ドキュメントのオーバービューやチュートリアルを参照すれば簡単に使えるようになるが、Qiitaでもcheckpoint氏が素晴らしい入門記事を執筆されているので、興味がある人は是非試してほしい。
オーバービューに掲載されているサンプルコードを引用しよう。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'http://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').extract_first(),
'author': quote.xpath('span/small/text()').extract_first(),
}
next_page = response.css('li.next a::attr("href")').extract_first()
if next_page is not None:
next_page = response.urljoin(next_page)
yield scrapy.Request(next_page, callback=self.parse)
start_urlsで開始URLを指定し、parse()内でHTTPレスポンスのデータを元に結果を辞書型で返す、あるいは、新規のHTTPリクエストを作成することで次のURLのクロールを開始する。
コードはたったのこれだけである。あとは scrapy runspider quotes_spider.py と実行するだけで、クロール結果がjson形式で出力される。
scrapy startprojectコマンドで、設定ファイル込みのプロジェクトテンプレートを作成することもできるし、scrapy shellでHTTPリクエストの結果を受け取った状態でipythonを起動してインタラクティブモードに入ることもできるので、ページのパースを試しながらコードを書くことも簡単。
レスポンスの解析はCSSセレクタで行うのが標準のため、BeautifulSoupに慣れている人には一見敷居が高いもしれないが、CSSセレクタはそこまで修得が難しいものではないと感じたのでScrapyを初めて触るのであれば、この機会に勉強してもいいと思う。もしどうしてもBeautifulSoupを使いたいのであれば、コードを読めばわかる通り結果は単にyieldしているだけなので、レスポンス結果を元にBeautifulSoupインスタンスを生成すればいいだけである。この方法については公式ドキュメントのFAQにも記載されている。
今回使用した機能・コマンド等についてはScrapy メモを参照。
Pentaho Data Integration
Pentaho Data Integration (以下PDI) は、旧Pentaho社(現日立製作所)が公開しているOSSのETLツール。公式サイトから誰でも自由にダウンロードできる。
ETLは、Extract Transform Load の略で、要するに「データを入力し、変換し、出力する」ということを行うためのツールである。変換というのは、例えば重複行の排除や列の名前変更や型変更、データのJOINなどを指す。
個々の処理はさほど難しい処理ではないので、コードを書き慣れている人であれば「そのくらいなら普通にコード書いた方が早い」と思う人も多いだろう。しかし、これらの処理のフローが複雑になってくると、全体の流れを追いかけるだけでも非常に時間がかかってしまう。PDIを使うと、こうしたフローを可視化できるので非常に管理がしやすい。
以下のスクリーンショットは今回作成したフローの一部である。
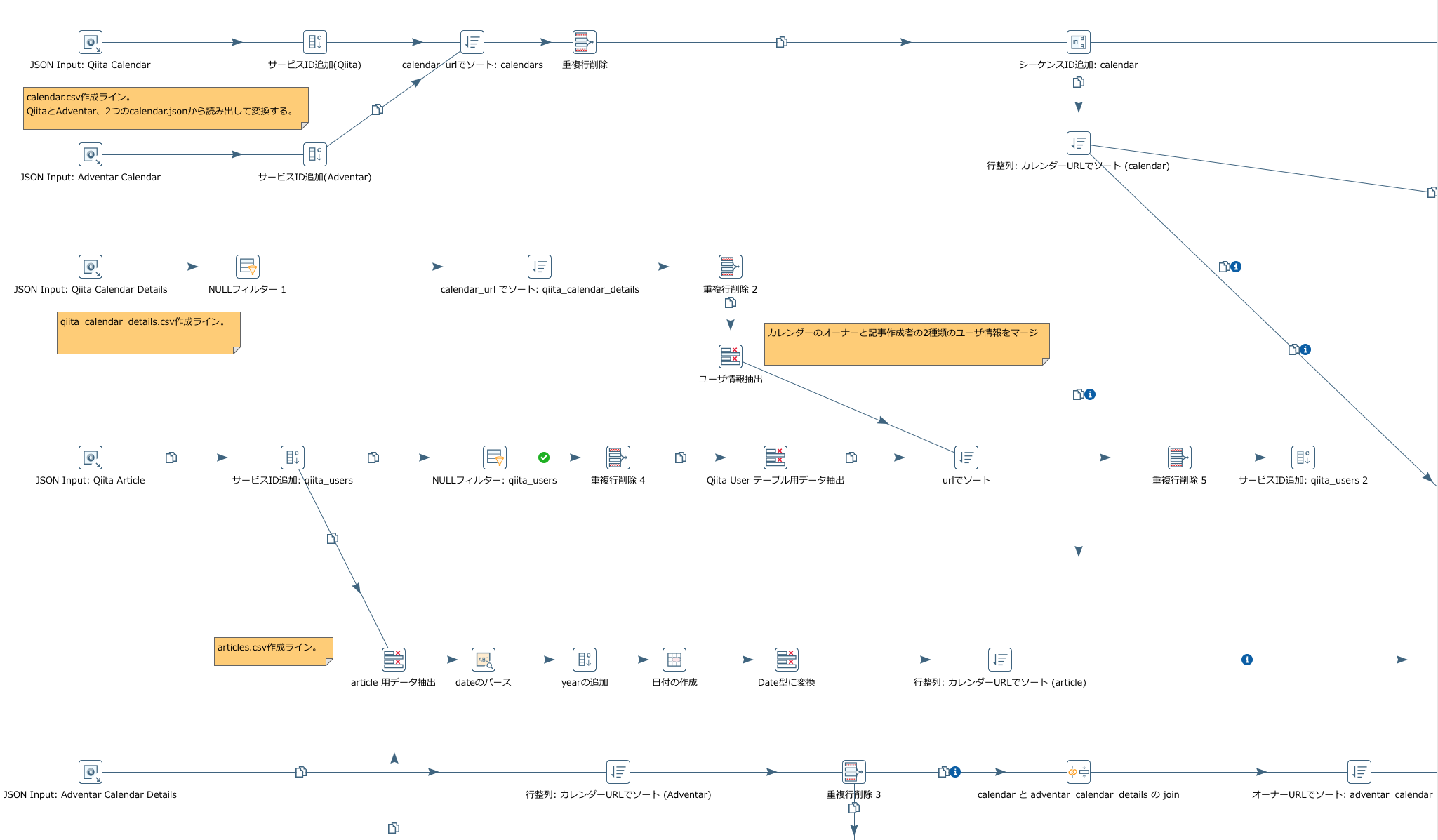
アイコン一つ一つが一処理を担う。このアイコン単位でプレビューを表示することができるので、処理がうまくいかない場合にどこでデータの変換が間違っているのかを追いかけるのも簡単だ。
データフローの定義ファイル自体はxmlのため、git上で管理できるのも利点の一つである。
今回使用した機能・コマンド等についてはPentaho Data Integration メモを参照。
Tableau Public
Tableau PublicはTableau社が公開している無償のBIツールで、ほとんどの機能は有償版のTableau Desktop Personal/Professional Editionと全く同じである。
有償版との差分は以下の通り。
- 利用できるデータソースが限られている(事実上Excel, CSV, Googleスプレッドシートのみ)
- 保存したデータは全てインターネット上に公開される
2つ目が重要なポイントである。これはつまり、個人のブログなどで活用する分には何も問題ないということを意味する。また、公開できないデータであっても、少し試しに全体を俯瞰するだけで保存しなければ活用できるので、個人利用であれば全く問題ないだろう。
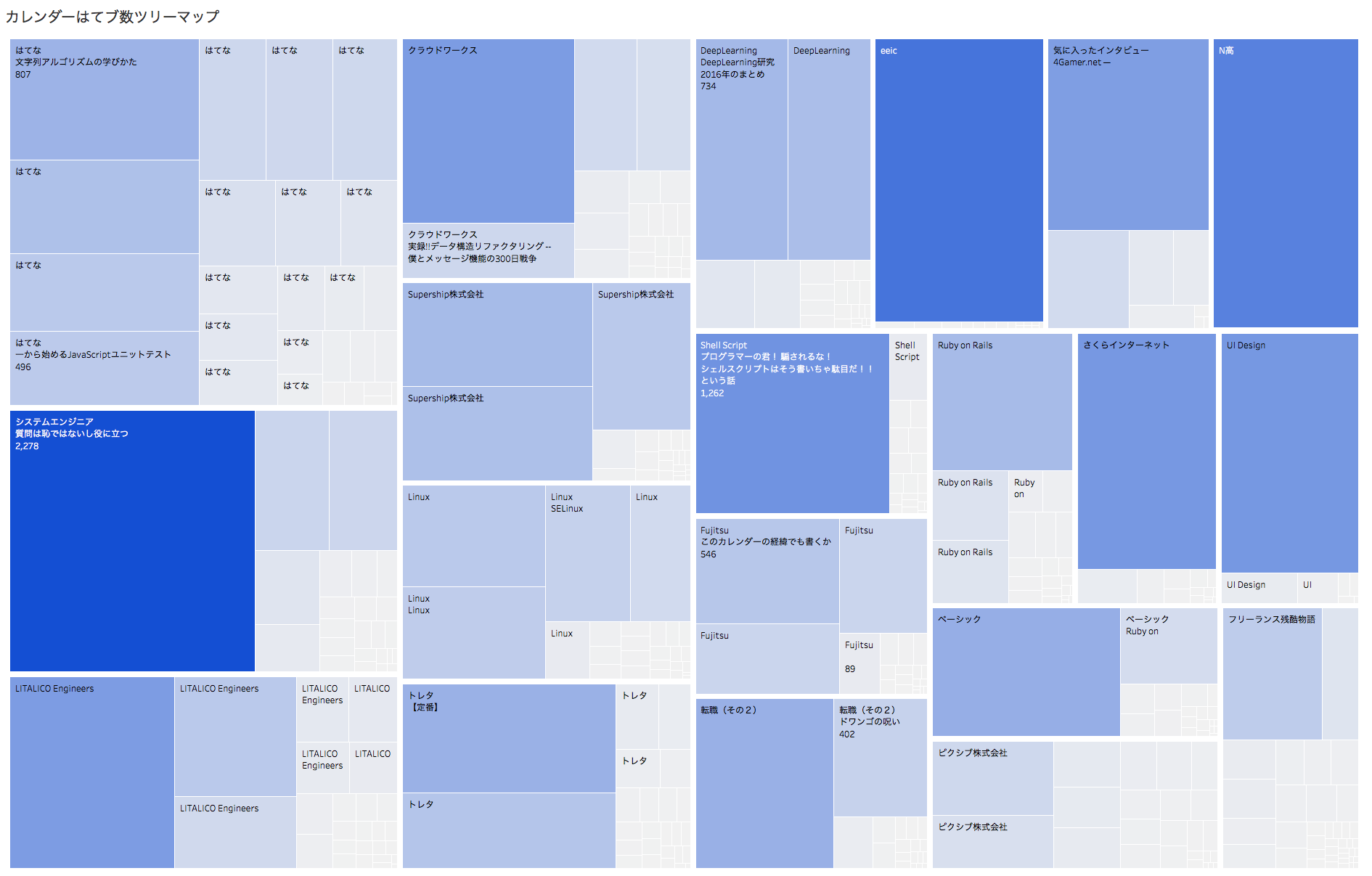
例えば、以下のようなツリーマップを簡単に作成することができる。こうした図をExcelやGoogleスプレッドシートで作成することはほぼ不可能であるし、RやPythonで出力するにはそれなりの修得期間が必要だろう。Tableauなら一切そのような学習コストはかからず、ただ必要なデータと表示形式を選択するだけである。
データ収集から変換、可視化、公開までの流れ
以下は私が今回実施した流れをまとめているだけで、このやり方が本当にベストプラクティスかどうかは保証できない。
あくまで参考程度に読んでいただければ幸いである。
どういう問いに答えたいかを考える
今回の場合、前例の分析を読んでから自分も真似してみようと決めたため、問いかけの作成は非常に簡単だった。
前例の記事では、
- カレンダー毎のはてブ数の上位ランキングはどのようになっているか?
- 記事毎のはてブ数の上位ランキングはどのようになっているか?
の2つのクエリを実行していた。全く同じでは芸がないので、以下のようなクエリを追加した。
- QiitaとAdventar、サービス毎の記事数やはてブ数はどのように違っているのか?
- 毎日の記事投稿数はどのように変化しているか?
- ユーザ毎のはてブ数の上位ランキングはどのようになっているか?
スキーマの全体像を作る
問いかけの内容から、中心となるデータは明らかにはてなブックマークの数である。はてなブックマークはURL毎にカウントされるため、URLとはてなブックマークの関連を示すデータがファクトデータとなる。
カレンダー及び記事はそれぞれユニークなURLを持つため、URLを中心に各データを紐付けることができそうだとわかる。
全体を俯瞰していくと、以下のことがわかってくる。
- 今回の調査対象はQiitaとAdventarの2つのサービスである
- 各サービスにはそれぞれ複数のカレンダーが登録されている
- 各カレンダーにはそれぞれ複数の記事が登録されている
- 各カレンダー及び記事には1人の作成者がいる
- 各カレンダー及び記事には1つのURLが存在する
- 各URLは個別にはてなブックマーク数がカウントされている
このことから、以下のテーブルを作ればいいだろうということがわかる。
- hatenabookmarks: URLとはてなブックマーク数の関係を表す(ファクトテーブル)
- services: サービス。QiitaとAdventarの2つだけ
- calendars: カレンダー
- articles: 記事
- users: ユーザ
データを収集する
Scrapyを使って、データの収集を行う。Webクローリングの常識だが、対象サイトに負荷をかけないよう細心の注意を払わなければいけない。
出力はjson形式だが、この段階では正規化されていないため、後の正規化処理のキーとなるURLが全てのjsonファイルに含まれるようにする。
ETL処理を記述する
収集したjsonファイルを読み込み、さきほど簡単に設計したスキーマの形式に変換していく。このフェーズで足りないデータや間違って収集しているデータに気づく場合があるので、おそらくデータ収集フェーズと行き来することになるだろう。
データを分析する
精製されたデータをBIで分析する。いきなり凝ったビューを作成するのではなく、まずは簡単な集計等を行って全体の俯瞰を行う。この段階で明らかにデータが間違っていることに気づくことが多い。このとき、ETL処理が間違っているのか、そもそもデータの収集が間違っているのかを確認するという作業が必要になる。この手戻りに一番時間がかかる。しかし、分析フェーズでないと気づけないような問題も多いため、我慢して修正作業にとりかかること。
また、一通り分析すると、あらたな問いかけが浮かんでくる。こうした新たな問いかけを、今回のスコープにするか、次回に回すか、あるいは捨て去るのかを判断する必要がある。今回の例では、Qiitaはアドベントカレンダーのカテゴリ分けをしていることを事前に知らなかったため、この観点での分析が抜けていた。今回は公開しないという選択肢を取ったが、手元で試したところ、カテゴリ別の分析もかなり面白い結果が出たのでそのうち公開するかもしれない。
分析結果を公開する
いいビューが作れたとしても、そのビューが何を意味するのかが伝わらなければ意味がない。一目見るだけで誰でも理解できるようなビューなのか、別途説明が必要なのかを判断する必要がある。今回の例は問いかけの内容が非常に単純だったため特に解説は不要だと判断したが、場合によってはビューの見方についての説明や、考察などが必要になるかもしれない。しかし、考察などは余計な先入観を読者に与えるため、十分に注意して記述する必要がある。