Jubatus Advent Calendar 2016 の16日目です.
Jubatusには様々な機械学習アルゴリズムが搭載されていますが、何を使えばよいのかピンと来ない人も多いと思います。
ここでは、Jubatusの分類器がどのように学習を進めているのかを可視化してみます.
分類とは
分類とは、与えられたデータがどのようなラベルに属しているかを判定するタスクのことを指します。
例えば、届いたメールがスパムであるかを判定する二値分類問題や、手書き文字が0-9のどれなのかを判定する多値分類問題があります。
Jubatusによる分類
Jubatusは分類器として、線形分類器と近傍探索器の2つを利用して分類を行うことができます。これらの分類器がどのように学習を進めていくのかを、人工データを用いて可視化していきます。
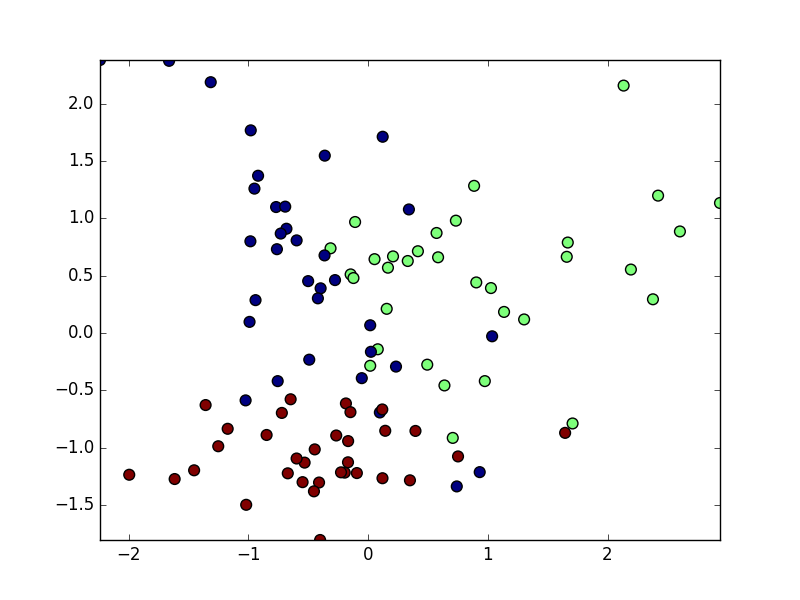
線形分類器
線形分類器は文字通り、直線(超平面)によって分類を行います。重み$\mathbf{w}$の調整方法によって様々な分類器が存在しています.
f_c(\mathbf{x}) = \mathbf{w}^{\mathrm{T}} \mathbf{x}
Jubatusの線形分類器ではラベル数だけ分類器$f_c(\cdot)$を用意して、入力されたデータ$\mathbf{x}$に対して最も分類スコア$f_c(\mathbf{x})$が大きいクラスを分類結果とします。
y = \mathrm{arg}\max_c f_c(\mathbf{x})
この手法をOne-Versus-Rest法(OVR法)といいます。Jubatusでは二値分類問題でも、正ラベルと負ラベルそれぞれで分類器を用意して分類を行います。
Perceptron
Perceptronは最も簡単なオンライン線形分類器です.
入力データ$(\mathbf{x}_i, y_i)$が現在の分類器で正しく分類できるかを確かめて,誤分類しているなら、以下の式により重みを更新します。
\mathbf{w}_{i+1} = \mathbf{w}_i + y_i\mathbf{x}_i

PA: Passive Aggressive
PAはGMailの優先トレイ学習で使われているアルゴリズムです.
PAは、データを正しく分類できたら重みを更新せず(Passive)、データを誤分類したら、そのデータを正しく分類できる最小限の量だけ重みを更新します(Aggressive)。
\begin{align}
\mathbf{w}_{i+1} & = \mathbf{w}_i + \tau_i y_i\mathbf{x}_i \ , \ l_t = \max\{0, 1-y_i \mathbf{w}_i^{\mathrm{T}}\mathbf{x}_i\} \\
\tau_i & = l_t / ||\mathbf{x}_i||^2 \ , \ (\mathrm{PA}) \\
\tau_i & = \min\{C, l_t / ||\mathbf{x}_i||^2\} \ , \ (\mathrm{PA1}) \\
\tau_i & = l_t / ||\mathbf{x}_i + 1/2C||^2 \ , \ (\mathrm{PA2})
\end{align}
PAは誤分類したら必ず分離平面が移動するため、ノイズに弱く、分離平面がバタついてしまうという問題があります。そこで $\tau$ の設計を見直し、誤分類をある程度許容することで頑健性を向上させたPA1, PA2も合わせて提案されています。
今回はPA2を可視化してみます。perceptronほどではないものの,分類平面がバタついていることがわかります.

CW: Confidential Weighted Algorithm
CWでは重みがガウス分布に従うという仮定を置いて、重みの確信度に基づいて適応的な更新を行います。もう学習は十分進んでいるという自信のある重みの更新は少なく、まだ学習は進んでいないという自信のない重みの更新を大きくします。
重み $\mathbf{\mu}$ の分散共分散行列を $\mathbf{\Sigma}$ とします。CWでは、入力データ$(\mathbf{x}_i, y_i)$を確率 $\eta$ 以上で分類できるという制約のもとで、更新前のガウス分布とのKL距離が最小になるように$(\mathbf{\mu},\mathbf{\Sigma})$を更新します。
\begin{align}
(\mathbf{\mu}_{i+1},\mathbf{\Sigma}_{i+1}) & = \mathrm{arg}\min_{\mathbf{\mu}, \mathbf{\Sigma}} KL(\mathcal{N}(\mathbf{\mu}, \mathbf{\Sigma}) \mid \mathcal{N}(\mathbf{\mu}_i, \mathbf{\Sigma}_i)) \\
\mathrm{subject\ to \ \ } & Pr_{\mathbf{w} \sim \mathcal{N}(\mathbf{\mu}, \mathbf{\Sigma})} (y_i \mathbf{w}^{\mathrm{T}} \mathbf{x}_i \geq 0) \geq \eta \ \ (0.5 \leq \eta \leq 1.0)
\end{align}
確率0.5以上で必ず分類しなさい,という強い制約が存在しているため,データに誤ったラベル付けがされている状況やノイズが多い状況では急激に性能が劣化してしまいます.

AROW
CWのノイズに弱いという弱点を克服するためにAROWは提案されました.
AROWでは次のように平均ベクトルと分散共分散行列を更新します.
(\mathbf{\mu}_{i+1},\mathbf{\Sigma}_{i+1}) = \mathrm{arg}\min_{\mathbf{\mu}, \mathbf{\Sigma}} KL(\mathcal{N}(\mathbf{\mu}, \mathbf{\Sigma}) \mid \mathcal{N}(\mathbf{\mu}_i, \mathbf{\Sigma}_i)) + \lambda_1 (\max\{0, 1-y_i \mathbf{\mu}_i^{\mathrm{T}}\mathbf{x}_i\})^2 + \lambda_2 \mathbf{x}_i^{\mathrm{T}}\mathbf{\Sigma}_i\mathbf{x}_i
それぞれの項の保つ役割に付いて説明すると,次のようになります.
- 第一項は更新前のガウス分布とのKL距離を最小化する,すなわち分布の形が急激に変化することを防ぐ役割があります.これはCWと同じですね.
- 第二項は損失関数であり,現在の入力データに対してよくフィットするように学習をすすめることを表しています.
- 第三項はデータが増えるにつれて確信度が増加する,すなわち$\mathbf{\Sigma}$が小さくなることを表しています.
CWの確率$\eta$で分類しなさい,という制約の代わりに第二項と第三項を目的関数に組み込むことにより,ノイズ耐性を増強させています.
可視化結果を見てみると分離平面のバタつきがなくなっていることがわかります.

NHERD
NHERDもAROWやCWと同様に,重み$\mathbf{w}$はガウス分布から生成されるという仮定を置いて学習を行います.
更新式は以下のようになります.
\begin{align}
\mathbf{\mu}_{i+1} & = \mathbf{\mu}_{i} + y_i \frac{\max\{0, 1-y_i \mathbf{\mu}_i^{\mathrm{T}}\mathbf{x}_i\}}{\mathbf{x}_i^{\mathrm{T}}\mathbf{\Sigma}_i\mathbf{x}_i + 1/C}\mathbf{\Sigma}_i\mathbf{x}_i \\
\mathbf{\Sigma}_{i+1} & = \mathbf{\Sigma}_{i} - \mathbf{\Sigma}_{i}\mathbf{x}_i\mathbf{x}_i^{\mathrm{T}}\mathbf{\Sigma}_{i} \frac{C^2\mathbf{x}_i\mathbf{\Sigma}_i\mathbf{x}_i^{\mathrm{T}}+2C}{(1+C\mathbf{x}_i\mathbf{\Sigma}_i\mathbf{x}_i^{\mathrm{T}})^2}
\end{align}
平均 $\mathbf{\mu}$ の更新式をよく見てみると,PA2の更新則と非常によく似ています.
NHERDは,各重みベクトルをPAの条件に従って更新した後,これをガウス分布で近似する,というアプローチを取ります.CW, AROWはKL距離の意味で分布を更新していましたが,NHERDではマハラノビス距離を使って分布を更新します.
個人的な体感では,NHERDよりもAROWの方が精度が出る場合が多いので,AROWを使うことが多いです.

近傍探索器
近傍探索器では,学習済みデータ群から現在の入力データの近傍$k$点を探索し,それらのラベルを踏まえて入力データのラベルを決定します.Jubatusには厳密な近傍計算を行うeuclidean, cosine,ハッシュに基づき近傍計算を行うeuclid_lsh, lsh, minhashがあります.今回はeuclidean, cosineについて紹介します.
ユークリッド距離 euclidean
euclideanでは,$k$近傍点を探索した後,各近傍点のラベル毎に距離計算を行い,どのラベルに属するかを判断します.
\begin{align}
& y = \mathrm{arg}\min_c \{\sum_i \exp(\alpha \cdot d(\mathrm{x}, \mathrm{x}_{i,c}))\} \\
& d(\mathrm{x}_i, \mathrm{x}_j) = || \mathrm{x}_i - \mathrm{x}_j ||
\end{align}
ここで$\alpha$はlocal_sensitivityと呼ばれるユーザパラメータです.距離計算時にexpを取ることで,近傍点を重視したスコア計算が行われます.

コサイン類似度 cosine
cosineでは,原点から各ベクトルのなす角度から類似度を計算する手法です.
コサイン類似度の意味で$k$近傍点を探索した後,各近傍点のラベル毎に類似度計算を行い,どのラベルに属するかを判断します.
\begin{align}
& y = \mathrm{arg}\min_c \{\sum_i \exp(-\alpha \cdot (1 - s(\mathrm{x}, \mathrm{x}_{i,c}))\} \\
& s(\mathrm{x}_i, \mathrm{x}_j) = \frac{\mathrm{x}_i^{\mathrm{T}}\mathrm{x}_j}{||\mathrm{x}_i|| \cdot ||\mathrm{x}_j||}
\end{align}
euclideanと異なり,cosineでは原点から放射状に分離平面が構築されます.

まとめ
jubatusの学習の様子を人工データセットを用いて可視化してきました.
AROWとNHERDがノイズに強いということがよくわかったかと思います.
今回の可視化に使ったソースコードです.2次元ベクトルまでしか可視化できませんが,ぜひ皆さんの手元にあるデータでも実験してみてください!
明日は@TkrUdagawaさんがいらすとやを使った楽しいアプリケーションを紹介してくれるようです.楽しみですね!
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import sys
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.animation import FuncAnimation
from jubakit.classifier import Classifier, Schema, Dataset, Config
from jubakit.model import JubaDump
from sklearn.datasets import make_classification
from sklearn.utils import shuffle, check_random_state
from sklearn.preprocessing import LabelEncoder, StandardScaler
# user parameters
method = sys.argv[1]
port = 9199
regularization_weight = 1.0
seed = 42
meshsize = 50 # we can draw clear decision surface with large meshsize
# setting random seed
np.random.seed(seed)
check_random_state(seed)
# load dataset
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=42, n_clusters_per_class=1, n_classes=3, flip_y=0)
labels = np.array(['c1', 'c2', 'c3'])
y = labels[y]
X, y = shuffle(X, y, random_state=42) # sklearn iris dataset is unshuffled
# prepare encoder to plot decision surface
le = LabelEncoder()
le.fit(labels)
c = le.transform(y)
# scale dataset with (mean, variance) = (0, 1)
scaler = StandardScaler()
X = scaler.fit_transform(X)
# calculate the domain
X_min = X.min(axis=0)
# X_min = np.ones(X.shape[1])
X_max = X.max(axis=0)
X0, X1 = np.meshgrid(np.linspace(X_min[0], X_max[0], meshsize),
np.linspace(X_min[1], X_max[1], meshsize))
# make training dataset
dataset = Dataset.from_array(X, y)
# make mesh dataset to plot decision surface
contourf_dataset = Dataset.from_array(np.c_[X0.ravel(), X1.ravel()])
# setup and run jubatus
config = Config(method=method,
parameter={'regularization_weight': regularization_weight})
classifier = Classifier.run(config, port=port)
# construct classifier prediction models and dump model weights
for i, _ in enumerate(classifier.train(dataset)):
model_name = 'decision_surface_{}'.format(i)
classifier.save(name=model_name)
# prepare figure
fig, ax = plt.subplots()
def draw_decision_surface(i):
midx = int(i / 2)
sidx = int(i / 2) + (i % 2)
# load jubatus prediction model
model_name = 'decision_surface_{}'.format(midx)
classifier.load(name=model_name)
# predict
Y_pred = []
for (_, _, result) in classifier.classify(contourf_dataset):
y_pred = le.transform(result[0][0])
Y_pred.append(y_pred)
Y_pred = np.array(Y_pred).reshape(X0.shape)
# draw decision surface
ax.clear()
ax.set_xlim([X_min[0], X_max[0]])
ax.set_ylim([X_min[1], X_max[1]])
ax.contourf(X0, X1, Y_pred, alpha=0.3, cmap=plt.cm.jet)
ax.scatter(X[:sidx+1][:, 0], X[:sidx+1][:, 1], c=c[:sidx+1], s=60, cmap=plt.cm.jet)
ax.set_title('method={}, iteration={}'.format(method, sidx))
return ax
ani = FuncAnimation(fig, draw_decision_surface, frames=np.arange(0, X.shape[0]*2), interval=100)
ani.save('{}.gif'.format(method), writer='imagemagick')
plt.show()
classifier.stop()
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import absolute_import, division, print_function, unicode_literals
import os
import sys
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.animation import FuncAnimation
from jubakit.classifier import Classifier, Schema, Dataset, Config
from jubakit.model import JubaDump
from sklearn.datasets import make_classification
from sklearn.utils import shuffle, check_random_state
from sklearn.preprocessing import LabelEncoder, StandardScaler
# user parameters
port = 9299
method = sys.argv[1]
nearest_neighbor_num = 5
local_sensitivity = 1
hash_num = 512
seed = 42
meshsize = 50 # we can draw clear decision surface with large meshsize
# setting random seed
np.random.seed(seed)
check_random_state(seed)
# load dataset
X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2, random_state=42, n_clusters_per_class=1, n_classes=3, flip_y=0)
labels = np.array(['c1', 'c2', 'c3'])
y = labels[y]
X, y = shuffle(X, y, random_state=42) # sklearn iris dataset is unshuffled
# prepare encoder to plot decision surface
le = LabelEncoder()
le.fit(labels)
c = le.transform(y)
# scale dataset with (mean, variance) = (0, 1)
scaler = StandardScaler()
X = scaler.fit_transform(X)
# calculate the domain
X_min = X.min(axis=0)
X_max = X.max(axis=0)
X0, X1 = np.meshgrid(np.linspace(X_min[0], X_max[0], meshsize),
np.linspace(X_min[1], X_max[1], meshsize))
# make training dataset
dataset = Dataset.from_array(X, y)
# make mesh dataset to plot decision surface
contourf_dataset = Dataset.from_array(np.c_[X0.ravel(), X1.ravel()])
# setup and run jubatus
config = Config(method=method,
parameter={
'nearest_neighbor_num': nearest_neighbor_num,
'local_sensitivity': local_sensitivity})
classifier = Classifier.run(config, port=port)
# construct classifier prediction models and dump model weights
for i, _ in enumerate(classifier.train(dataset)):
model_name = 'nn_decision_surface_{}'.format(i)
classifier.save(name=model_name)
# prepare figure
fig, ax = plt.subplots()
def draw_decision_surface(i):
midx = int(i / 2)
sidx = int(i / 2) + (i % 2)
# load jubatus prediction model
model_name = 'nn_decision_surface_{}'.format(midx)
classifier.load(name=model_name)
# predict
Y_pred = []
for (_, _, result) in classifier.classify(contourf_dataset):
y_pred = le.transform(result[0][0])
Y_pred.append(y_pred)
Y_pred = np.array(Y_pred).reshape(X0.shape)
# draw decision surface
ax.clear()
ax.set_xlim([X_min[0], X_max[0]])
ax.set_ylim([X_min[1], X_max[1]])
ax.contourf(X0, X1, Y_pred, alpha=0.3, cmap=plt.cm.jet)
ax.scatter(X[:sidx+1][:, 0], X[:sidx+1][:, 1], c=c[:sidx+1], s=60, cmap=plt.cm.jet)
ax.set_title('method={}, iteration={}'.format(method, sidx))
return ax
ani = FuncAnimation(fig, draw_decision_surface, frames=np.arange(0, X.shape[0]*2), interval=100)
ani.save('{}.gif'.format(method), writer='imagemagick')
plt.show()
classifier.stop()