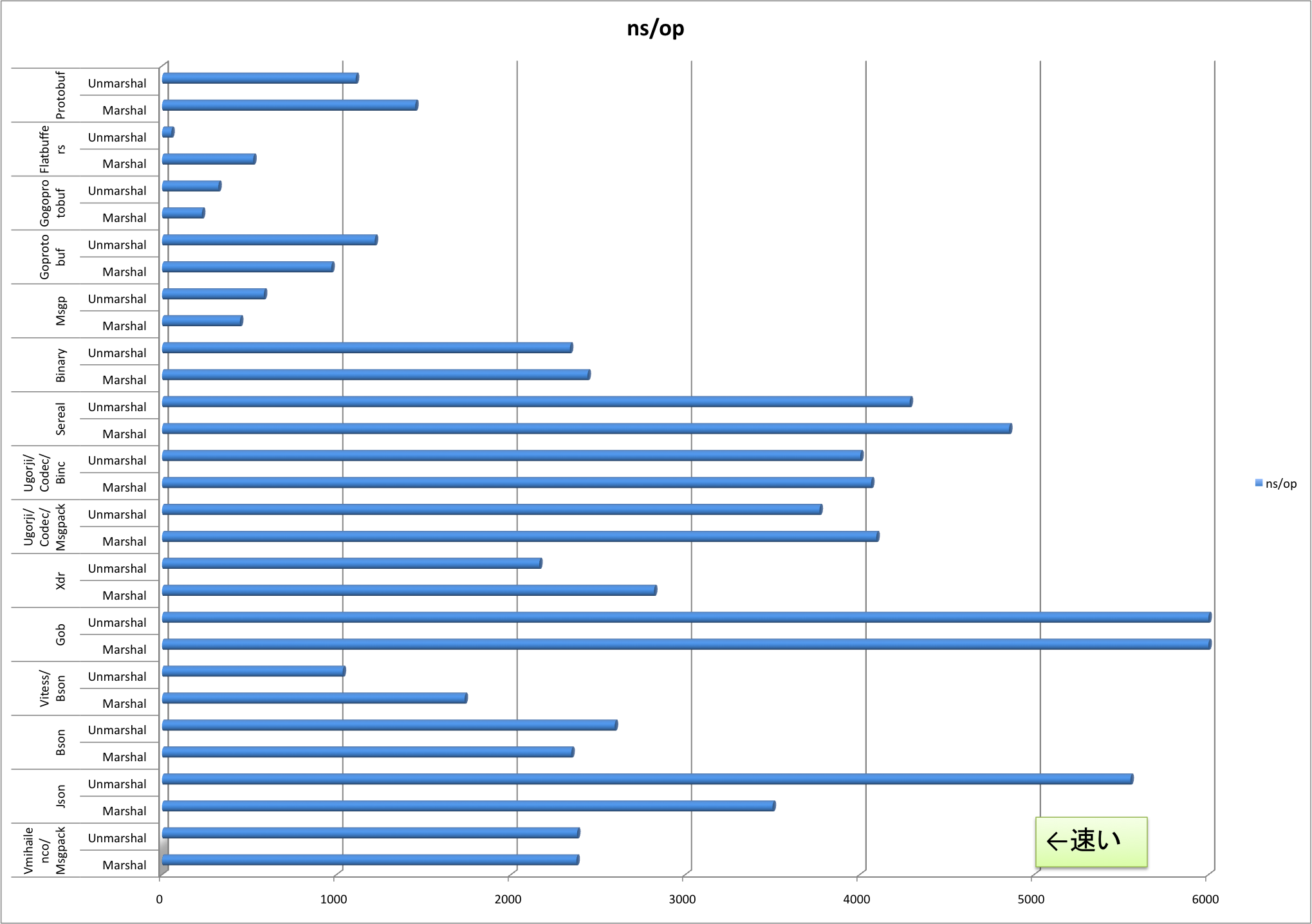
GoCon 2015 Winterでは、社内での取り組みとしてExcelのパースの時間のロスを避けるために、簡易データ構造を使ってMessagePack + LZ4で圧縮して高速化したことを紹介しました。それでも十分速くはなったのですが、LTで発表のあったシリアライズ系のライブラリのベンチマーク比較でFlatbuffersが最速だったので、ちょっと試してみました。
↑のグラフは、こちらのベンチマークの結果をExcelでグラフにしてみたものです。Gobがダントツ遅かったのでそちらは振りきっています(Gobに合わせると他のものの比較がしにくくなるので範囲を狭めた)。GoConで発表した通り、今MessagePackを使っているのはデータのキャッシュです。作成に多少がかかっても、後の読み出しが速い方がトータルとしてはうれしい領域なので、Unmarshalが最速のFlatbuffersに俄然興味を惹かれました。
基本的には本家のドキュメントを見れば一通りは分かると思います。スライドで紹介した軽量Excelフォーマットの構造体のFlatbuffers対応に挑戦してみました。なかなか説明がされてなくてつらいことが多かったので、僕の屍を越えていく人のためにアドベントカレンダーとしてTipsを載せていこうと思います。
ちなみに、サンプルはGoで書いていますが、試してないけど基本的な考え方は他の言語でも同じだとおもいます。
まずはfbsファイルを作成
Protocol Buffersと同じように、スキーマ定義を書いていきます。Flatbuffersは専用のフォーマットで書いていきます。関数定義のないオブジェクト指向言語的な雰囲気です。まあ難しくないですね。ちなみに構造体というのもあって、それは3個の数値が一セットで三次元座標みたいな密結合なDDDで言うところのバリューオブジェクトのデータ構造を定義するのに使います。Golangの構造体や一般的な構造体などのエンティティはテーブルを使います。
namespace lightxlsx;
enum fbCellType : byte {StringType= 1, BooleanType, NumericType, FormulaType, OtherType}
table fbRow {
cells:[string];
cellTypes:[fbCellType];
}
table fbSheet {
name:string;
rows:[fbRow];
}
table fbFile {
sheets:[fbSheet];
}
root_type fbFile;
こんな感じで実行すると、lightxlsxというフォルダにファイルがばらばらとできます。
$ flatc --go lightxlsx.fbs
$ ls -1 lightxlsx
fbCellType.go
fbFile.go
fbRow.go
fbSheet.go
package宣言もついて(namespaceがそのままpakcage名になる)、そのままコンパイルできるコードなのでこれでこれでもう読み書きバッチリだと思うでしょ?実はまだまだです。これからが大変なんです。
Flatbuffersの処理系で自動生成されるのは、だいたいこんな感じのコードのみです。
- 読み込み時に使う、bytes.Bufferのシーク先のインデックス情報を持ったタグ(構造体)
- 型情報付きで書き込むWrite関数
実際に構造体のデータを流し込むには、生成された関数+アルファを使ってBufferを組み立てる処理を書く必要があります。また、読み込み時は、インデックス情報を参照しながらデータをピックアップしてくる処理が必要です。
Flatbuffersバイナリを作成するコードの作成
生成されたファイルには fbFile fbSheet といった構造体らしきものと、 fbSheetStart() や fbSheetAddName() といった、断片的なデータ追加の関数があります。構造体はまず無視して、Flatbuffersバイナリを作成するコードを作ります。
参考になったのはCicatriceさんの「FlatBuffersを使ってみる2のブログエントリーです。
やることは、 b := flatbuffers.NewBuilder(0)で作ったビルダーオブジェクトに対して、データを登録していく作業です。自動生成した関数を使って登録していくと、 GetRootAsfbFile() 関数一発でバイト列から構造体が作れるようなデータができます。
上記のエントリーにもありますが、__階層をばらしてボトムアップで1層ずつデータを作っていく__必要があります。今回のファイルは次のような構造になっています。
File
- []Sheet
- []Row
- []string
- []CellType
まずは、元になるExcelファイルの全セルをスキャンして文字列を登録していきます。同じ文字列がいくつもあるとムダかなと思ってExcelの内部構造と同様に先に文字列マップを作りました。本当は4重ループを回していますが、省略するとこんな感じです。数値系はそのまま登録できますので事前に登録する必要はありません。
stringMap := map[string]flatbuffers.UOffsetT{}
for _, str := range ファイル/シート/行/セルの4重ループ {
builder.CreateString(str)
}
一番下の階層を作っていきます。構造体的には[]stringと[]CellTypeを持つRowテーブルが一番下のように見えますが、実は配列も1つの階層になります。上記の定義ファイルは、実は7階層あるデータ構造ということになります。一層ずつ作ってそのIDを取っておいて、次の階層を作るという手順になります。flatbuffersのBuilderはネストされると一瞬で顔を真赤にして怒り出します。
File
- Vector
- Sheet
- Vector
- Row
- Vector
- string
- Vector
- CellType
配列の登録
配列への登録は、先ほど自動生成された関数と、builderのメソッドの両方を使います。
fbRowStartCellsVector(builder, len(文字列の配列))
for i := len(文字列の配列) -1; i > -1; i-- {
builder.PrependUOffsetT(stringMap[str])
}
cellsIndex := builder.EndVector(len(文字列の配列))
まずは fbRowStartCellsVector() を要素数指定して呼んで配列をこれから登録することを宣言します。その後、 builder.PrependUOffsetT() を必要なだけ呼んで文字列を登録します。最後に ```builder.EndVector()`` を呼びます。最後のメソッド呼び出しでまたオフセット値を返してくるのでどこかにとっておきます。注意点としては、配列は逆順に登録していく必要がある という点ですね。
今回はセルの種類は少ししかないのでバイトで格納していきますが、PrependUOffsetT()の代わりに、固定長の型を登録するメソッドを呼べばOKです。
builder.PrependByte(byte(cellType))
テーブルの登録
テーブルの要素は自動生成された関数を使います。Start/Endの間でメンバーを登録していきますが、先ほどの配列生成でできたインデックスを渡します。
fbRowStart(builder)
fbRowAddCells(builder, cellsIndex)
fbRowAddCellTypes(builder, cellTypeIndex)
rowIndex := fbRowEnd(builder)
今回はテーブルのみを使って構造体は使っていないのですが、構造体に関する注意は上記のブログにありまして、作成と同時に登録(こいつだけはネスト可能)が必要とのことです。
後は同じように、 fbSheetStartRowsVector() - builder.EndVector() 間で builder.PrependUOffsetT() を使って fbRowEnd() の返り値のインデックスをすべて登録した配列を作り、 fbSheetStart() - fbSheetEnd() で配列のインデックスを登録し・・・というのを、一番トップの fbFile まで行います。lz4圧縮もしちゃいましょう。
fbFileStart(builder)
fbFileAddSheets(builder, sheetList)
fileEnd := fbFileEnd(builder)
builder.Finish(fileEnd)
data := builder.FinishedBytes()
outputFile, err := os.Create(filePath)
defer outputFile.Close()
if err != nil {
log.Fatal(err)
}
compressed, err := lz4.Encode(nil, data)
if err != nil {
log.Fatal(err)
}
outputFile.Write(compressed)
めでたしめでたし。
最終回じゃないぞよ
もうちっとだけ続くんじゃ。
Flatbuffersの速度のヒミツ
Flatbuffersの速さのヒミツは、ファイルロード時にパースをしないことかと思います。生成されたコード等を読んでも、基本は生のデータをずっと持っていて、各要素はインデックス値を持っていて、それを元に必要なところをピンポイントで取りに行く処理になっています。正規表現でテキストを見に行くようなコストがまったくないのと、パースの処理を必要なところまで後倒しにしていく、明日できることは今日やらなという、アジャイルをコードに応用したような挙動をします。
全データを毎回100%使うことはそんなにないですからね。読み捨てる部分が多ければ多いほどコスト的に有利と。ベンチマーカーだましな点は、上記のようにロードと言われてもほとんど読み込み処理が未実行状態で止まっている点ですね。例えベンチマークの速度が100倍でも、実際に処理するときに借金を一部返す必要があるので、実際には差はそこまでありません。
読み込み時のメモリアロケートがゼロ、という点も特徴的ですが、それもある意味、実行時にコストを先送りしたということになります。↓詳しくは読み込みの最後を参照のこと。
理由がわかると面白いし、自分のコードでもその考え方を応用したくなりますよね。たとえばGolangでxlsxのパースが遅い時にベンチをとったところ、処理時間の大半がXMLのタグやAttributeの構造体のメモリ確保だったりしたのですが、パース時はインデックスだけを取っておいて、読み込み時に指示されてはじめて構造体を作って返す、みたいな処理とか良さそうですよね?
Flatbuffersバイナリから取り出したデータをアプリに使えるようにするコードの作成
書き込みはできて速度のヒミツも探りました。自動生成された GetRootAsfbFile() 関数に、↑の書き込み処理で作った[]byteの塊を渡すと、トップの要素だけのインスタンスが作られます。それより下は1つずつデータを取り出すためのメソッドは生成された構造体(fbFileなど)に生えているのですが、そのままだとインタフェースが使いにくいので、何らかの構造体でラップしたAPIを提供することになると思います。今回もそうしました。方針としては2つあると思います。
- fbFile, fbSheet, fbRowのポインタを持つ、元の構造体と同じ構造の構造体を作る
- 完全なGoの構造体を作り、Flatbuffersから読み込んでデータを入れる。Flatbuffersのデータは読み込み終ったら捨てる。
すでにロジックができあがっているなら、後者の方が簡単だと思います。Flatbuffersの生データ分のメモリも節約できるのでそちらがクリティカルなら後者がいいかもしれません。また、Flatbuffersのデータをランタイム時に書き換えるのは大変なので、読み込んだデータを加工して使っていく時も後者が良いと思います。今回は少し手間がかかると思いましたが、性能面で有利そうな前者にしました。
ちなみに、最初から"fb"という小文字名が入ったテーブル名にしていたのは、後からラップしたり別インタフェースを提供するし、プライベートな要素になるからでした。
一部だけ取り出すとこんな感じです。文字列は[]byteで返ってくる点ぐらいですかね。Goの場合はコンパイルすればすぐに分かることなので、あまり気にしなくてもいいですね。
type Row struct {
src *fbRow
}
func (row *Row) CellCount() int {
return row.src.CellsLength()
}
func (row *Row) GetCellValue(i int) string {
if row.src.CellsLength() <= i {
return ""
}
return string(row.src.Cells(i))
}
func (row *Row) GetCellType(i int) CellType {
if row.src.CellsLength() <= i {
return OtherType
}
return CellType(row.src.CellTypes(i))
}
func (row *Row) GetCellAsBool(i int) bool {
if row.src.CellsLength() <= i {
return false
}
return string(row.src.Cells(i)) == "1"
}
ファイルのロードは次のように行っていきます。
var file fbFile = GetRootAsfbFile(data, 0)
sheetSrc := &fbSheet{}
src.Sheets(sheetSrc, 0)
トップよりも下の階層は構造体のインスタンスすら作られないので、自分で作って、それのポインタを渡して src.Sheets() 関数でインデックスを渡してオフセット値の設定を行います。こうやって1つずつ階層を降りていくことができます。作成時と違って階層は構造体の数だけ(配列はカウントしないで)意識すればOKです。
読み込み時のメモリアロケートがゼロというのもこのあたりがヒミツですね。実際に読み込み時にどんどん自分で構造体をアロケートしちゃうと、速度のメリットは失われちゃうので、一部は未変換のままに残すというのは必要でしょう。
読み込み処理が半分近くかかっているコードを置き換えて、かるーくベンチマークしてみたところ、読み込みも含めたトータルの処理時間は2割超下がったので、ファイル読み込みに関しての速度アドバンテージは僕のところのケースで約2倍という感じでした。
MessagePackは、JSONからほぼコストゼロで移行できて、得られる効果も比較的大きいというのはメリットかと思います。Flatbuffersは実装コストがそれなりにあるのと、構造変更でコードも直さないといけない点などがデメリットですね。ちなみにファイルサイズはLZ4圧縮後でMessagePackの方が半分ぐらいです。というかFlatbuffersの場合はオリジナルのxlsxよりもでかいことがしばしば・・・用途やデータの使われ方、読み込みのデータの転送環境(例えば3G回線経由のロードなど)次第ではベンチマークは逆転する可能性はありそうです。
たいてい、万能なアルゴリズムというものはないので、トレードオフを正しく理解した上で使える選択肢の1つに追加するのはありですね。
ちなみにこちらで紹介した各ソースコードは、実際のコードじゃなくて、説明用に簡易版でした。
明日はdeeeetさん、rjgeさん、zcheeさんです。