あふれるデータ
会社で、Treasure Dataを使った分析システムを作っている。ゲーム情報を収集して、ユーザーの体験向上に役立てるためだ。そのため、ユーザーの行動を細かく把握する必要がある。勢いデータ容量は増えてしまう。加えて、オンラインのゲームは、パッケージゲームと違い売って終わりではなく、その後何年にも渡って、サービスを提供する。そのため、ユーザーの行動ログは数億件に達することも珍しくない。
Treasure Dataでのログ分析
先に書いたが、大量のログに対応するため、hadoopを利用した問題解決が様々な企業から提供され始めている。タイトルに有るTreasure Dataもその企業の一つだ。こちらからは、ログを送るだけでhadoopやhiveを用いた分析環境を提供してくれる。一方で、こちらが分析機材を用意するわけではないため、どのくらいの速度で分析できるかわからない。特に複雑なHiveクエリーの場合どの程度時間がかかるか?データ量が増えた時にどのような振る舞いを示すのかは、自分自身で試さなければ、本当のところはわからない。
Treasure Dataを使ったhiveベンチマーク
そのため、Treasure Dataを使ったhiveのベンチマークを行った。使用したデータは、実際のゲームを模倣したダミーのデータだ。
このダミーデータを10 億件入れたテーブル(データサイズは305GB)を作成し、それに対して、そこそこ複雑なHiveクエリーを投げた。
{"response":
{"presents":
[
{
"id":335,
"type":1,
"name":"連続ガチャ",
"quantity":1,
"unit": {
"mode":0,
"is_new":false,
"master_id":3027,
"unit": {
"id":5495,
"master_id":3027,
"level":1,
"exp":0,
"skill_learning": [
{
"master_id":30012,"exp":0
}
],
"learned_action_ids":[9930032,9930033,9930036,9930054,9930057,9930058],
"union_count":0,
"state":null,
"role":1
}}}]}}
このクエリーも仮想のものであるが、Hiveクエリーの内容は、loginというAPIからuser_idを集計し、総ログイン者数を抜き出すものだ。distinctをしなかったのは、ダミーデータとして重複するuser_idを使いまわして使っており、 集計値が増えないので、distinctは外した。
SELECT COUNT(a.user_id)
FROM (SELECT get_json_object(v['response'],'$.user.id') AS user_id
FROM complex_10m_test_json
WHERE (v['api_name']='login')
AND (get_json_object(v['response'],'$.user.id') IS NOT NULL) ) a;
ベンチマーク結果
10億件のデータに対するベンチマークは、データを、一千万件ずつ増やしながら100回行った(表では億の値のみ抜粋)。
下に回帰式を書いたが、基本的に、処理時間は線形に増加した。最初の1億から2億件くらいでは8cpuコア以上は使っていなかったが、その後、件数が増えると32コアcpu使い出した。
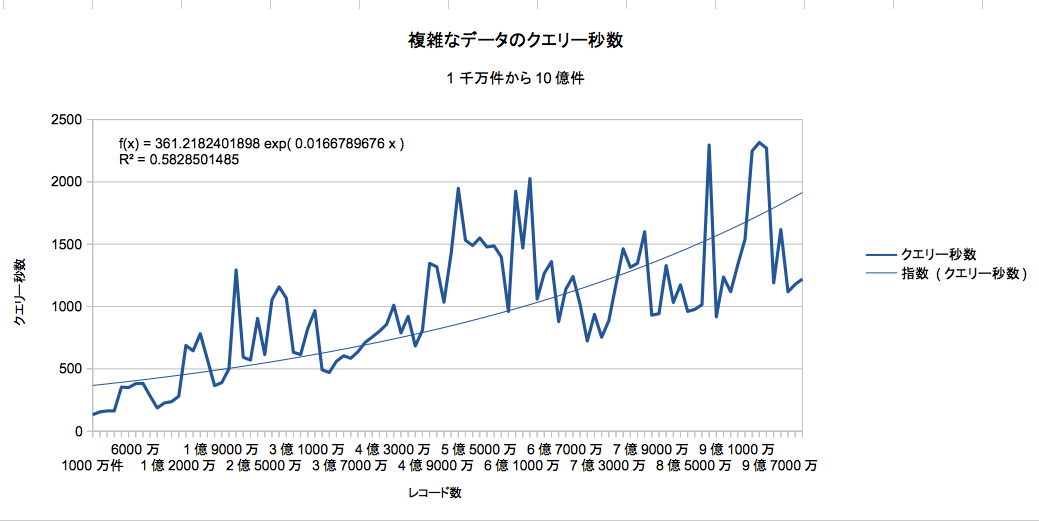
ベンチマーク結果表
| 件数 | クエリー秒数 |
|---|---|
| 1000万件 | 133 |
| 1億 | 227 |
| 2億 | 500 |
| 3億 | 615 |
| 4億 | 756 |
| 5億 | 1035 |
| 6億 | 1924 |
| 7億 | 724 |
| 8億 | 943 |
| 9億 | 1119 |
| 10億 | 1220 |
ベンチマークの結果から、回帰式を作ってみた。
f(x)=361.2182401 exp(0.01666789 * x)
R2 = 0.5828
大体5−6億件で1000秒を超えるくらいだと考えれば良いと思う。
tdのcpu利用数
Treasure Dataでは、契約マシンのCPU使用量などを公開している。上記ベンチマークを取った際の、CPU使用量についてグラフを調べた。ところどころCP使用コア数が下がっている場所は、ベンチマークプログラムにバグが有り、計測を中断した場所だ。
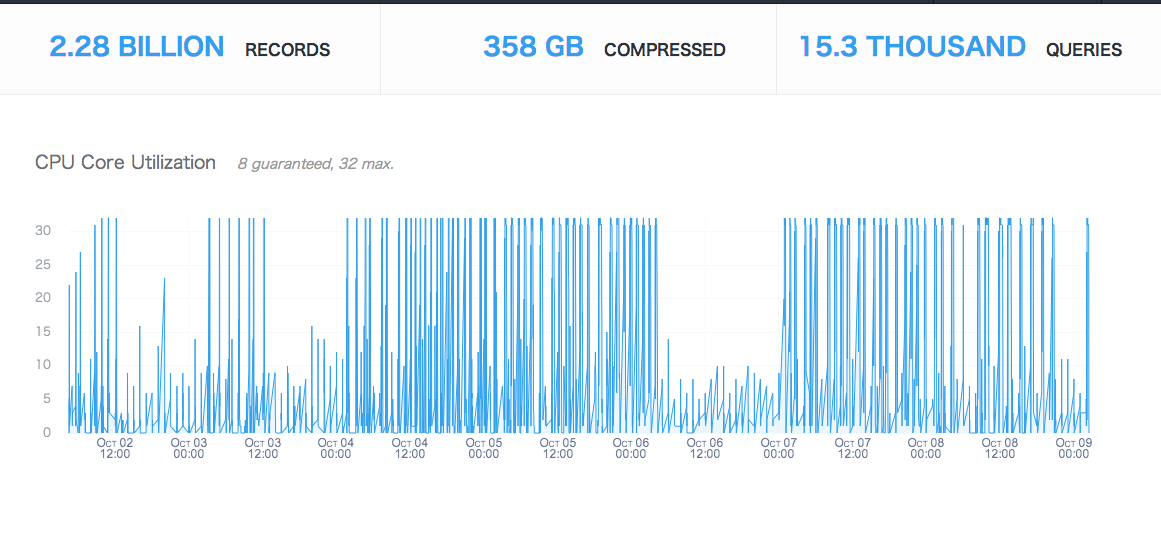
データサイズ358GB
データ容量22億件
まとめ
Treasure Dataについてベンチマークを行った。MySQLの様にデータが増えると急激に処理時間が増えるようなことも無かった。手軽に色々分析するには良い環境ではないかと思う。