ニコニコ動画のデータ公開
ニコニコ動画は日本最大級の動画サイトだ。他の動画サービスにない特徴として動画にコメントを付けることが出来、それがユーザーの視聴体験を特別なものにしている。
一般的に知られていないが国立情報学研究所には、ニコニコ動画の動画データ及びコメントデータが公開されている。
2012年11月にリリースされて(前回提供版)、2016年8月(今回提供版)に内容をアップデートしている。
詳しい詳細は以下のようになっている。
| 前回提供版 | 今回の更新版 | |
|---|---|---|
| 対象期間 | 2007年3月6日-2012年11月7日 | 2007年3月6日-2016年8月31日 |
| 総動画数 | 8,305,696(約830万) | 14,269,919(約1,400万) |
| 総コメント数 | 2,474,388,485(約25億) | 3,465,469,245(約35億) |
コメントは、35億件となかなかのボリュームがある。結構大きいので、BigQeuryなどで解析しないとしんどいだろう。
動画データと、コメントデートを取得する
国立情報学研究所のこちらのページの「ニコニコ動画コメント等データ」申請ページ」からデータ取得の申請を行う。別に研究者ではなくてデータを取得できる(野生の研究者でも良い)。
サイトの案内にもあるがwget -r 指定されたURLでデータを手に入れる。ダウンロードされたファイルの場所は結構深くなる。
動画情報で、約3.5GB,コメント情報で、64GBある。
データをBigQueryに入れづらい点
コメント情報にsmidが無い。
コメントを手に入れて、中味を見るとまず次のことに気づく。
{"date":1184538870,"vpos":18011,"content":"なんか、すごい難しそうだねー","command":null}
{"date":1184543281,"vpos":2638,"content":"最近大戦の動画が多くてマジでうれしい","command":null}
{"date":1184583414,"vpos":21052,"content":"スナイプ諦めた?","command":null}
{"date":1184583586,"vpos":37454,"content":"すげー","command":null}
{"date":1184585664,"vpos":30266,"content":"M2!しかも前に出てきているw","command":null}
{"date":1184585746,"vpos":38557,"content":"ano","command":null}
smidがない
このまま、BigQueryに突っ込んでも、動画IDが無いので動画ごとのコメントの集計が出来ない。
動画IDはjsonl外のファイル名にある。この場合は、sm630023.jsonlがファイル名になっている。どうにかして、jsonlの中に、smidを付与しないとデータを入れられない。
動画情報
zipである。形式としては、jsonlをzipに固めたものになっている。その為、GCSにそのままおいて、BQに入れると言った方式が取れない。
BigQueryに入れる方式を検討する
コメントの例を見てもそうだが、video_idを情報に入れ込むなど、何らかの対策が必要になる。その手段を検討する。やらなければならないことは、zipを解凍し、中に入っているファイルを一つ一つ走査し、jsonを辞書化した後に、その辞書に対して、ファイル名から取得したvideo_idを埋め込むという作業が必要になる。
今回は、commentが34億件あり、大量のデータであるので、どうにか分散環境で処理を行うか、速いプログラムを書いて処理したい。
候補として考えたのはこちら。
- Google Cloud Function
- Google DataFlow
- embulk
- 手製のスクリプト
できれば、手製のスクリプトは最後の手段にした。そのための他の方式を検討した。
Google Cloud Function
Google Cloud Functionは、AWSのlambdaと同じで、サーバレスに処理を実行する方式だ。イベントに処理をアタッチ出来る。例えばアクセスがあったとか、ファイルをGCSに追加したなどのイベントをトリガーに処理を記述できる。
GCSにファイルをおいた際に、zipファイルを解凍し、ファイル名を取得して、jsonlを辞書化してファイル名を入れ込むと言ったこともできそうだ。調べる限り、zipを解凍するライブラリもあるらしい。
javascript(node.js)で実行出来るため便利かなとは感じた。
今回は、時間の無く、デバックがやりやすいとも思えなかったので採用を見送った。
Google Cloud DataFlow
Google Cloud DataFlowは大量のデータを取得するのに向いている。一斉にマシンを立ち上げ、処理をして速やかにマシンを落とす。クラウドで大量のデータ処理に向いたシステムだ。
DataFlowでやろうと思っていたが、zipファイルを読み込んだ際に、書庫ファイル名が簡単には取れないようなので今回は諦めた。
embulk
embulkはtreasuredataが公開している大量データの一括処理に適したライブラリだ。Commons Compress decoder plugin for Embulk を使えば、zipファイルを読み込める。
ただこちらも、DataFlowと同じく簡単には、書庫名が取り出せないようだ。
自前実装
仕方がないので、自前で実装を行った。手元の非力なマシンだと、34億のデータを処理するのに何時間かかるかわかったものでは無いので、GCPで早めのマシンを借りて、そちらで処理することにした。このような短期間のコンバート処理などでは、24時間しか寿命がないが低価格プリエンプティブインスタンスが経済的だ。自分は、16coreをマシンを借りた。通常のマシンに比べて、価格が大体1/4位だ。
BigQueryにデータを入れる。
ビデオ情報をBQに入れる。
zipからgzへ変換
zipのままでは、BQが読んでくれないので、gzに変更する。zipの中では、一zip->一jsonlになっているので、jsonlを取り出してgzにする。
作ったスクリプトはこちら
こちらで、zipを読み込み、gz変換する。
それを、GCSにあげて、BQにloadする。反省点としては、ファイルを大きくしてしまったので、bq loadにやたら時間がかかった。GCS経由でBQにloadする際には、ファイルのサイズを小さくしたほうが早く、load出来るようだ。(圧縮1GBファイル3つをBQにロードするのに、大体2時間程度かかった)。
後日、圧縮20MB位で、300個に分割して、GCSからBQにロードしたら、2分程度で終わった。
実行したBQloadコマンドは以下
bq load --project_id=[PROJECT_ID] --source_format=NEWLINE_DELIMITED_JSON --schema video.json nico_data.video "gs://[GCS]/video/*.gz"
途中に出て来るvideo.jsonのフォーマットはこちら
コメント情報をBQに入れる。
zipからgzへ変換。
同じく、zipをBQは読めないので次のようにする。
zipを解凍
↓
書庫のファイル名を取り出す。
↓
書庫の中味(jsonl)を取り出す。
↓
jsonlをデコードして辞書化
↓
辞書にファイル名から取り出した、ビデオIDを入れる。
↓
その辞書を再度jsonにエンコード
↓
それをgzに圧縮
↓
処理済みのzipを処理済みとして別の場所に移動(GCPが途中で落ちて、処理が中断されても、未処理の分だけやれば良いようにした)。
という方法を取る。何にせよ34億件程度あるので、GCPで16coreを借り、pythonのmultiprocessでプロセス数を20にして、処理を行った。
ソースコードはこちら
16coreで大体6-7時間で処理が終わった。
その後作られたgzファイルを、GCSに移して、BQにloadした、ダウンロードしたzipのファイル量と同じく、3000ファイルに分割して、bq loadを行ったので、20分程度でデータを入れられた。
データロードの欠けに関して
video情報でデータロード時にロードに失敗したものは無かった。
comment情報では、vposの値が以上に大きなデータが5件ほどあった。
次のようなエラーがでた。
[gs://nico-data-201608/comment/2906.gz] JSON parsing error in row starting at position 66110830: Could not convert value 'double_value: 9.2233720368547758e+18' to integer. Field: vpos; Value: 9223372036854775808.000000
その為、エラーが出ても処理を続けるmax_bad_records パラメータを付けコマンド実行した。
BQ loadコマンドは次のようになっている。
bq load --project_id=[PROJECT_ID] --source_format=NEWLINE_DELIMITED_JSON --max_bad_records 10000 --ignore_unknown_values --schema comment.json nico_data.comment "gs://[GCS]/comment/*.gz"
途中出てくるcomment.jsonのフォーマットはこちら。
BQにビデオ情報、コメント情報が入った。
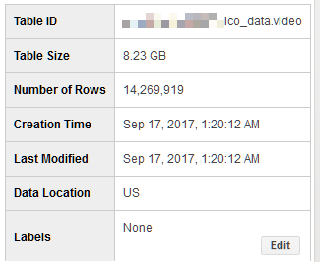
動画情報
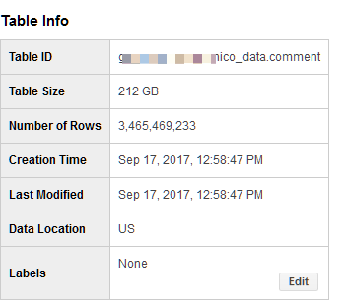
コメント情報
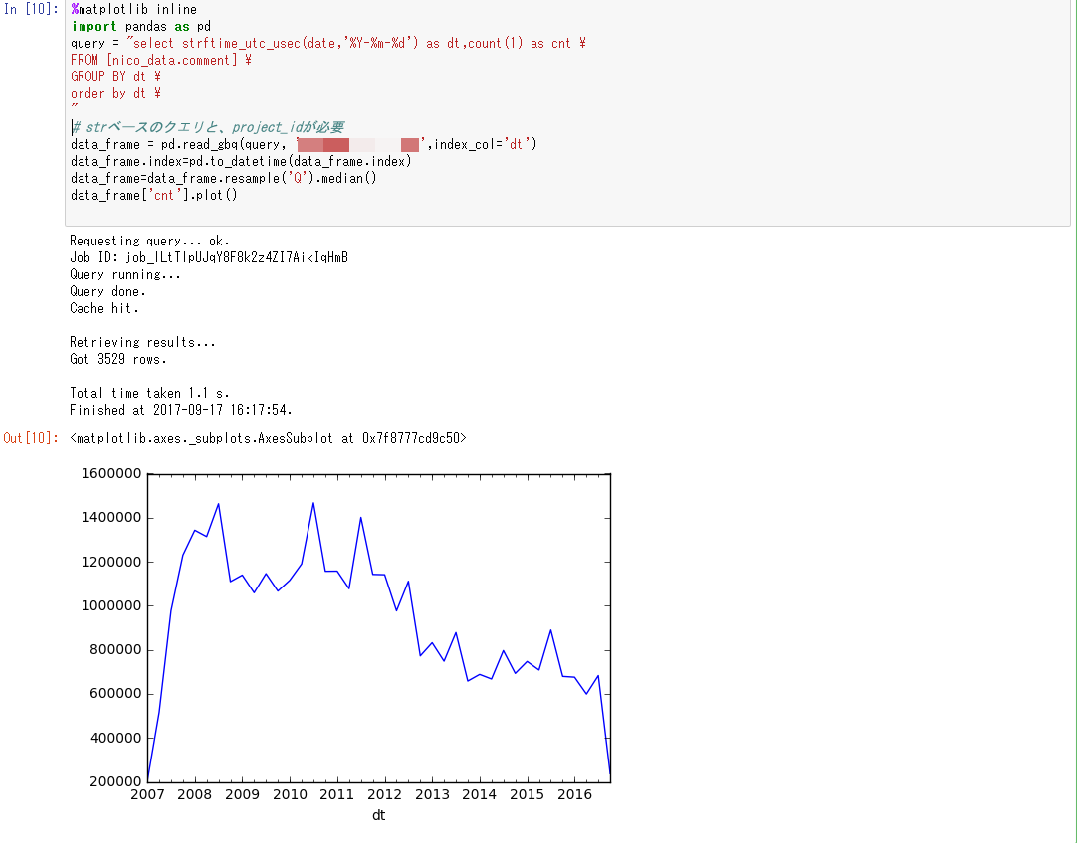
BQにデータが入ることで、jupyterとの連携も可能になった。
まとめ
ニコニコ動画は動画情報、コメント情報を、公開している。それらの情報を取得し、加工した上で、BigQUeryに入れた。
BigQueryにデータを入れる際には幾つかの選択肢があったが、最終的に自前スクリプトを作り、BigQueryが理解できる方式に変更した。
その際には、自前スクリプトを自分のマシンで実行せず、GCPを使うとコストパフォーマンスが良い。特に、プリエンプティブを使うと安く済む。
GCS経由でBigQueryにデータを入れる際には、データを細かく分割したほうがロードに時間はかからない。
最後にドワンゴさんにお願い。
これからも継続的に動画情報、コメント情報は出して下さい。
あと、コメント情報に、video_id を含めてもらえると助かります。
、