EC2安くなる
気がついたら、EC2がだいぶ値下げしていて、我が家の ニコニコデータセットの分析環境のHive利用料も安くなっていた。
参考
【AWS発表】42回目の値下げ!EC2、S3、RDS、ElastiCache、そしてElastic MapReduceも!
http://aws.typepad.com/aws_japan/2014/03/aws-price-reduction-42-ec2-s3-rds-elasticache-and-elastic-mapreduce.html
値段の問題もあり、ニコニコデータセット分析環境は、hadoopのバージョン1系でm1.mediumを3台利用して、分析を行っていた。しかし、Elastic Map Reduceがhadoop2系からimpalaをサポートしたこともあり、hadoopのバージョンを上げて、impalaで分析出来ないか検証することにした。
impalaとは
cludieraの作っているhiveの何倍のレスポンスが早い分析環境。hiveのデータベースをそのまま流用できる。
http://www.cloudera.co.jp/products-services/cdh/cloudera-impala.html
実験のまとめ
先に実験のまとめを書く。興味のある人は下を読んでね。
EC2の値下げにより、ElasticMapreduceも値下げしており、また、hadoopがバージョンアップし、hive以外の選択肢も出てきた。hiveの代わりとしてimpalaを使えないかと評価を行った。概ね、5倍から20倍程度高速化した。impalaは、中間一致的なクエリーはそんなに早くならないのではないと思ったが、きちんと早くなった。
この評価をする前に、m3.xlargeでコメントデータの中間一致検索を行ったがその場合は60秒程度で結果が帰ってきた。hiveの代わりに簡単なクエリーはimpalaを使うのはありだと感じた。
ニコニコ動画のデータをまとめた、ニコニコデータセットはこちらにある。
動画情報と、コメント情報、ニコニコ大百科の情報を利用できる。
Hive Impala分析環境の準備
Elastic mapreduce(EMR)環境で、impalaを利用する場合、設定は簡単だ。EMRのクラスターを作る際に以下のように最も新しいhadoopを選んで、impalaを追加すれば良い。
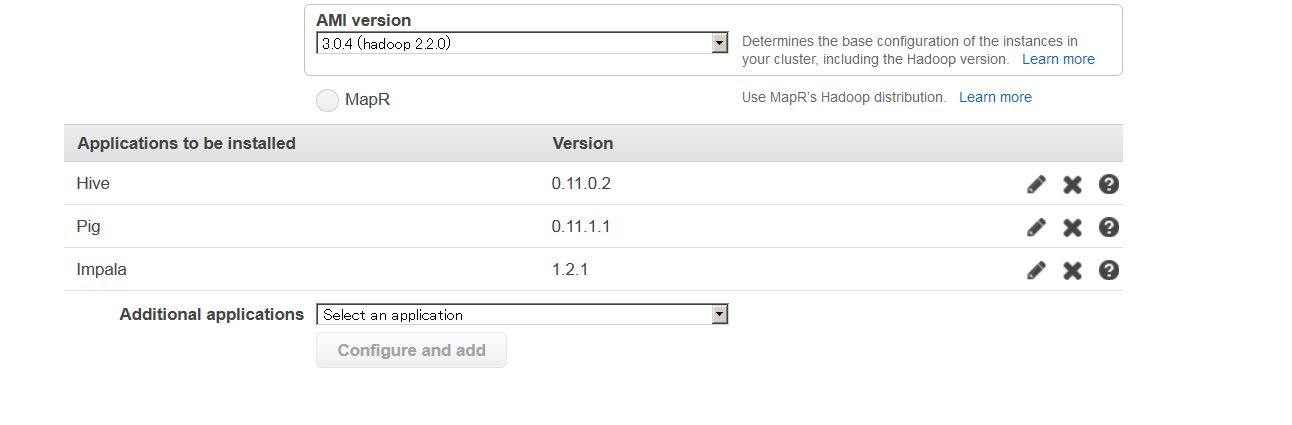
ruby製のクライアントであるelastic-mapreduce-ruby-cliを使う場合は、最新版を落としてきて、credentials.jsonを自分の環境に書き換えて、クラスター作成時に、--hive-interactiveを抜いて、--impala-interactiveを付け足せば良い。
シェルを晒すとこのような起動シェルを書いた
# !/bin/bash
~/elastic-mapreduce-ruby-cli/elastic-mapreduce --create --alive --impala-interactive --name "niconico_impala_test" \
--instance-group master --instance-type m1.medium --instance-count 1 --bid-price 0.3 \
--instance-group core --instance-type m1.large --instance-count 3 --bid-price 0.3 \
--ami-version 3.0.4
データの投入は、一旦手元の環境にデータを持ってきてから行う。s3上のデータをマウントすることもできるが、ネットワーク越しのデータを使ってimpalaが早くなるか不安があったので、手元に持ってきた。
データをs3からコピーするために以下の様なコマンドを書いた
# !/bin/bash
hadoop fs -mkdir -p /mnt/nico-data/
hadoop fs -cp s3n://nicovideo-info-data/videoinfo_sampling10 /mnt/nico-data/videoinfo_sampling10
hadoop fs -cp s3n://nicovideo-info-data/videoinfo_sampling100 /mnt/nico-data/videoinfo_sampling100
hadoop fs -cp s3n://nicovideo-info-data/comment_data_sampling10 /mnt/nico-data/comment_data_sampling10
hadoop fs -cp s3n://nicovideo-info-data/comment_data_sampling100 /mnt/nico-data/comment_data_sampling100
hadoop fs -cp s3n://nicovideo-info-data/videoinfo-rcfile /mnt/nico-data/videoinfo-rcfile
hadoop fs -cp s3n://nicovideo-info-data/comment-data-rcfile /mnt/nico-data/comment-data-rcfile
hadoop fs -cp s3n://nicovideo-info-data/tags /mnt/nico-data/tags
hadoop fs -cp s3n://nicovideo-info-data/tags_sampling10 /mnt/nico-data/tags_sampling10
hadoop fs -cp s3n://nicovideo-info-data/tags_sampling100 /mnt/nico-data/tags_sampling100
昔のhadoopと違っていた点は、mkdir に-pオプションを付けないと、複数段のディレクトリを作ってくれない。cpの際に、後ろに/があるときちんとコピーされないの2点だった。
このようにデータを入れたあと、
set hive.exec.compress.intermediate=true;
set hive.exec.compress.output=true;
set mapred.map.output.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
set mapred.output.compression.type=RECORD;
create database nicodata;
use nicodata;
CREATE TABLE videoinfo(
smid STRING,
thread_id STRING,
title STRING,
description STRING,
thumbnail_url STRING,
upload_time STRING,
length INT,
movie_type STRING,
size_high INT,
size_low INT,
view_counter INT,
comment_counter INT,
mylist_counter INT,
last_res_body STRING)
STORED AS RCFILE;
CREATE TABLE `comment_data`(
smid STRING,
`date` INT,
vpos INT,
no INT,
command STRING,
`comment_string` STRING)
STORED AS RCFILE;
CREATE TABLE `tags`(
smid STRING,
locked TINYINT,
category TINYINT,
tag STRING
)
STORED AS RCFILE;
LOAD DATA INPATH "/mnt/nico-data/videoinfo-rcfile" INTO TABLE videoinfo;
LOAD DATA INPATH "/mnt/nico-data/comment-data-rcfile" INTO TABLE comment_data;
LOAD DATA INPATH "/mnt/nico-data/tags/" INTO TABLE tags;
CREATE TABLE videoinfo_sampling10 LIKE videoinfo;
CREATE TABLE videoinfo_sampling100 LIKE videoinfo;
LOAD DATA INPATH "/mnt/nico-data/videoinfo_sampling10" INTO TABLE videoinfo_sampling10;
LOAD DATA INPATH "/mnt/nico-data/videoinfo_sampling100" INTO TABLE videoinfo_sampling100;
CREATE TABLE comment_data_sampling10 LIKE `comment_data`;
CREATE TABLE comment_data_sampling100 LIKE `comment_data`;
LOAD DATA INPATH "/mnt/nico-data/comment_data_sampling10" INTO TABLE comment_data_sampling10;
LOAD DATA INPATH "/mnt/nico-data/comment_data_sampling100" INTO TABLE comment_data_sampling100;
CREATE TABLE tags_sampling10 LIKE tags;
CREATE TABLE tags_sampling100 LIKE tags;
LOAD DATA INPATH "/mnt/nico-data/tags_sampling10" INTO TABLE tags_sampling10;
LOAD DATA INPATH "/mnt/nico-data/tags_sampling100" INTO TABLE tags_sampling100;
上記のコマンドを実行すると次のようなデータが入る。
| テーブル | 件数 |
|---|---|
| 動画情報 | 800万 |
| タグ情報 | 4000万 |
| コメント情報 | 24億 |
コンピュータで自動生成したわけではない、生のデータが大量に手に入るのは検証に便利だ。
impala実行
ここまでやって、やっとテーブルの設定が出来た。あとは、出来上がったクラスターにアクセスして、次のコマンドを実行。
impala-shell -r
-rオプションをつけているのは、接続後implaraのメタテーブルをrefreshするためにだ(そうしないとhiveで行った変更が反映されない)。
[ip-10-156-249-127.ap-northeast-1.compute.internal:21000] > select tag,count(*) as cnt from tags group by tag order by cnt desc limit 10;
Query: select tag,count(*) as cnt from tags group by tag order by cnt desc limit 10
+----------------------+---------+
| タグ名 | 件数 |
+----------------------+---------+
| ゲーム | 3593302 |
| 実況プレイ動画 | 1134356 |
| 音楽 | 874535 |
| 歌ってみた | 549536 |
| 投稿者コメント | 444108 |
| アニメ | 332877 |
| エンターテイメント | 320617 |
| 東方 | 231043 |
| もっと評価されるべき | 224274 |
| VOCALOID | 218548 |
+----------------------+---------+
Returned 10 row(s) in 17.98s
4千万のデータの集約が17秒。だいぶ早い。ちなみにhiveで行うと6分かかった。
結構早い。大体21倍程度
impalaの制約
impala-shell>で、日本語を含むSQLの実行が出来なかった。エラーが起こった。日本語を含むsqlも実行できると思うけど、やり方はわからなかった。
impalaとhiveの速度比較
impalaもhiveも同じHDFSを読めるし、同じマシンで実行できるので、速度の比較を行った。使用したマシンは、m1.large 4台だ。m3.xlargeでも試したが、結果を取り忘れた。
m1.largeはメモリが8GBある。インパラはメモリーが多いほどスコアが上がるので、本当はもっとあったほうが良いかもしれない。
wwwwを最も多く含んでいる動画はなに?
よくやる検索。wwwを含むコメントを抜き出し、そのコメントが最も多い動画を探す。検索的には、中間一致検索なので、カラム指向DBでもそんなに早くならないと予測した。データサイズは24億件だ。
impala
[ip-10-156-249-127.ap-northeast-1.compute.internal:21000] > select count(*) from (select smid,count(*) from comment_data where comment_string like "%wwwww%" group by smid) a;
Query: select count(*) from (select smid,count(*) from comment_data where comment_string like "%wwwww%" group by smid) a
+----------+
| count(*) |
+----------+
| 2133268 |
+----------+
Returned 1 row(s) in 283.81s
hive
hive> select count(*) from (select smid,count(*) from comment_data where comment_string like "%wwwww%" group by smid) a;
MapReduce Jobs Launched:
Job 0: Map: 117 Reduce: 37 Cumulative CPU: 4496.83 sec HDFS Read: 20356796592 HDFS Write: 4292 SUCCESS
Job 1: Map: 3 Reduce: 1 Cumulative CPU: 8.26 sec HDFS Read: 13681 HDFS Write: 8 SUCCESS
Total MapReduce CPU Time Spent: 0 days 1 hours 15 minutes 5 seconds 90 msec
OK
2133268
Time taken: 1372.008 seconds, Fetched: 1 row(s)
| タイプ | 秒数 |
|---|---|
| impala | 283秒 |
| hive | 1372秒 |
大体4倍位高速。24億件サイズのデータを個人が手が出るお値段で5分程度で解析できるのはすさまじい。
最も長い動画を探せ
800万件のデータから、最も動画長の長い動画を探す。
impala
Query: select max(length) from videoinfo
+-------------+
| max(length) |
+-------------+
| 65535 |
+-------------+
Returned 1 row(s) in 3.57s
hive
hive> select max(length) from videoinfo;
Job 0: Map: 7 Reduce: 1 Cumulative CPU: 53.31 sec HDFS Read: 56293172 HDFS Write: 6 SUCCESS
Total MapReduce CPU Time Spent: 53 seconds 310 msec
OK
65535
Time taken: 71.146 seconds, Fetched: 1 row(s)
| タイプ | 秒数 |
|---|---|
| impala | 3.5秒 |
| hive | 71秒 |
3.5秒 vs 71秒なので大体20倍位違う。
私達が解析するデータは意外と少ないデータも多いので、少ないデータでレスポンスが短いimpalaはありがたい。
単純にコメント数を測る
単純に、コメント件数を測った。複雑ではないのであまり性能の指標にはならない。
impala
[ip-10-156-249-127.ap-northeast-1.compute.internal:21000] > select count(*) from nicodata.comment_data;
Query: select count(*) from nicodata.comment_data
+------------+
| count(*) |
+------------+
| 2474388510 |
+------------+
Returned 1 row(s) in 133.86s
hive
hive> select count(*) from comment_data;
MapReduce Jobs Launched:
OK
2474388510
Time taken: 872.161 seconds, Fetched: 1 row(s)
| タイプ | 秒数 |
|---|---|
| impala | 133秒 |
| hive | 872秒 |
133秒 vs 872秒 で6.5倍高速
まとめ
EC2の値下げにより、ElasticMapreduceも値下げしており、また、hadoopがバージョンアップし、hive以外の選択肢も出てきた。hiveの代わりとしてimpalaを使えないかと評価を行った。概ね、5倍から20倍程度高速化した。impalaは、中間一致的なクエリーはそんなに早くならないのではないと思ったが、きちんと早くなった。
この評価をする前に、m3.xlargeでコメントデータの中間一致検索を行ったがその場合は60秒程度で結果が帰ってきた。
やはり10秒立たずに結果が帰ってくるのは、モチベーションの維持につながると思った。