アンサンブル学習ー異なるモデルの組み合わせ
本章では以下の内容を取り上げる
- アンサンブル学習
- バギング
- アダブースト
アンサンブル学習
アンサンブル法は、さまざまな分類器を一つのメタ分類器として組み合わせる
この方法であれば、分類器を個別に使用するよりも高い汎化性能が得られる
分類器を作成する方法は何種類かある
ここではアンサンブルの仕組みとそれらが高い汎化性能をもたらす理由の基本的な見解を示す
最も知られているアンサンブル法は多数決の原理を利用する
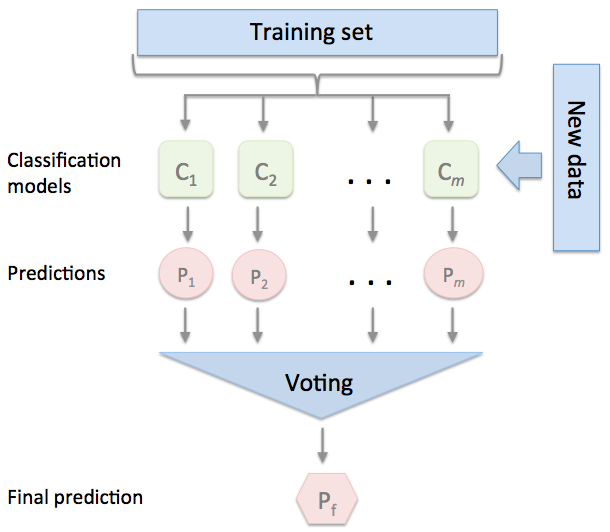
トレーニングデータセットを利用して、m種類の分類器(C1・・・Cm)のトレーニングを行う
手法によっては、決定木、サポートベクトルマシン、ロジスティック回帰分類器など、さまざまな分類アルゴリズムを使ってアンサンブルを構築できる
このアプローチの典型的な例は、さまざまな決定木分類器を組み合わせたランダムフォレストアルゴリズムである。
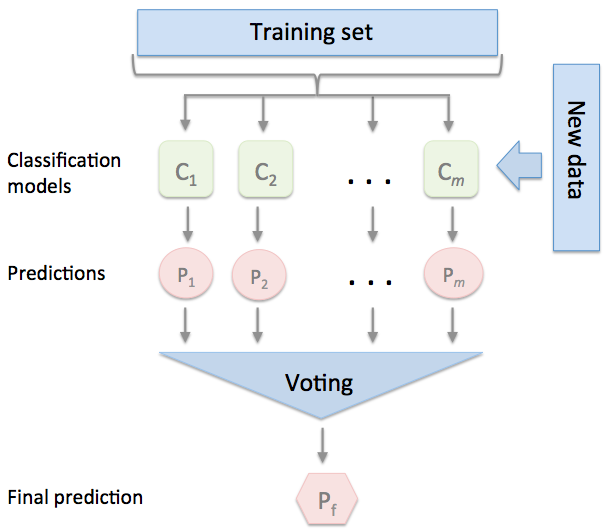
単純な多数決または相対多数決に基づいてクラスラベルを予測するには、個々の分類器Cjで予測されたクラスラベルをまとめ、最も票数の多いクラスラベルyを選択する
アンサンブル法のほうが単体の分類よりも効果がある理由
二値分類の11個のベース分類器の誤分類率が等しく0.25であるとする。
ベース分類器が11個中6個間違えて多数決の結果、誤分類になる確率は
これを二項分布として誤分類率を計算すると、0.034となり、o.25よりもはるかに低くなることがわかる
単純な多数決分類器の実装
まず多数決方式の単純なアンサンブル分類器をpythonで実装してみる
ここでの目的は、データセットに対する個々の分類器の弱点を保管しあうような
より強力なメタ分類器を構築することである
y=argmax\sum_{j=1}^{m}W_jX_A(C_j(x)=i)
y:予測されたクラスラベル
Xj:ベース分類器Cjに関連付けられている重み
XA:特性関数
確率論で確率変数の分布の特性を示す関数で,確率密度のフーリエ変換をいう。 (2) 一般に集合 Xの部分集合 Aに対し,Aを指定するために x∈Aなら1,x∉Aなら0として,xが Aに入るかどうかを判断すればよいが,これを X上の関数と考えて Aの特性関数という。
A:クラスラベルの集合
分類器の重みが等しい場合は
y=mode{C_1(x),C_2(x),C_3(x)・・・C_m(x)}
重み付けとは
■重みが同じ場合
C_1(x) = 0 ,C_2(x)=0, C_3(x)=1
0を選択
■重みが違う場合
C_1(x) = 0*0.2 ,C_2(x)=0*0.2, C_3(x)=1*0.6
1を選択
アンサンブル学習器をpythonで実装してみる
rom sklearn.base import BaseEstimator
from sklearn.base import ClassifierMixin
from sklearn.preprocessing import LabelEncoder
from sklearn.externals import six
from sklearn.base import clone
from sklearn.pipeline import _name_estimators
import numpy as np
import operator
class MajorityVoteClassifier(BaseEstimator, ClassifierMixin):
#基本的な機能を取得するためBaseEstimator, ClassifierMixinを継承
""" 多数決アンサンブル分類器
Parameters
----------
classifiers : array-like, shape = [n_classifiers]
アンサンブルの様々な分類器
vote : str, {'classlabel', 'probability'} (default='label')
classlabelの場合:クラスラベルの予測はクラスラベルのargmaxに基づく
probabilityの場合:クラスラベルの予測はクラスの所属確率に基づく
weights : array-like, shape = [n_classifiers], optional (default=None)
intまたはfloatの値のリストが提供された場合、分類器は重要度で重み付けされる
"""
def __init__(self, classifiers, vote='classlabel', weights=None):
self.classifiers = classifiers
self.named_classifiers = {key: value for key, value
in _name_estimators(classifiers)}
self.vote = vote
self.weights = weights
def fit(self, X, y):
""" Fit classifiers.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
y : array-like, shape = [n_samples]
Vector of target class labels.
Returns
-------
self : object
"""
if self.vote not in ('probability', 'classlabel'):
raise ValueError("vote must be 'probability' or 'classlabel'"
"; got (vote=%r)"
% self.vote)
if self.weights and len(self.weights) != len(self.classifiers):
raise ValueError('Number of classifiers and weights must be equal'
'; got %d weights, %d classifiers'
% (len(self.weights), len(self.classifiers)))
# Use LabelEncoder to ensure class labels start with 0, which
# is important for np.argmax call in self.predict
self.lablenc_ = LabelEncoder()
self.lablenc_.fit(y)
self.classes_ = self.lablenc_.classes_
self.classifiers_ = []
for clf in self.classifiers:
fitted_clf = clone(clf).fit(X, self.lablenc_.transform(y))
self.classifiers_.append(fitted_clf)
return self
def predict(self, X):
""" Predict class labels for X.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Matrix of training samples.
Returns
----------
maj_vote : array-like, shape = [n_samples]
Predicted class labels.
"""
if self.vote == 'probability':
maj_vote = np.argmax(self.predict_proba(X), axis=1)
else: # 'classlabel' vote
# Collect results from clf.predict calls
predictions = np.asarray([clf.predict(X)
for clf in self.classifiers_]).T
maj_vote = np.apply_along_axis(
lambda x:
np.argmax(np.bincount(x,
weights=self.weights)),
axis=1,
arr=predictions)
maj_vote = self.lablenc_.inverse_transform(maj_vote)
return maj_vote
#平均確率を返す
def predict_proba(self, X):
""" Predict class probabilities for X.
Parameters
----------
X : {array-like, sparse matrix}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number of samples and
n_features is the number of features.
Returns
----------
avg_proba : array-like, shape = [n_samples, n_classes]
Weighted average probability for each class per sample.
"""
probas = np.asarray([clf.predict_proba(X)
for clf in self.classifiers_])
avg_proba = np.average(probas, axis=0, weights=self.weights)
return avg_proba
def get_params(self, deep=True):
""" Get classifier parameter names for GridSearch"""
if not deep:
return super(MajorityVoteClassifier, self).get_params(deep=False)
else:
out = self.named_classifiers.copy()
for name, step in six.iteritems(self.named_classifiers):
for key, value in six.iteritems(step.get_params(deep=True)):
out['%s__%s' % (name, key)] = value
return out
では実際にアルゴリズムをためしてみる
まずデータを準備する
今回はscikit-learn.datesetのirisを使用
さらに、分類問題も難しくするよう「がく片の長さ」と「花びらのながさ」
という二つの特徴量のみを選択する
そして、データセットをトレーニングセットとテストセットを50%:50%に分割する
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import LabelEncoder
if Version(sklearn_version) < '0.18':
from sklearn.cross_validation import train_test_split
else:
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
X, y = iris.data[50:, [1, 2]], iris.target[50:]
le = LabelEncoder()
y = le.fit_transform(y)
X_train, X_test, y_train, y_test =\
train_test_split(X, y,
test_size=0.5,
random_state=1)
三種の分類器(ロジスティック回帰、決定木、k近傍法)を一つのアンサンブル分類器にまとめる前に
トレーニングデータセットを使ってそれらをトレーニングし、10分割交差検証を行ってトレーニングデータセットでの性能を調べてみる。
クロスバリデーションで評価する。
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.pipeline import Pipeline
if Version(sklearn_version) < '0.18':
from sklearn.cross_validation import cross_val_score
else:
from sklearn.model_selection import cross_val_score
clf1 = LogisticRegression(penalty='l2',
C=0.001,
random_state=0)
clf2 = DecisionTreeClassifier(max_depth=1,
criterion='entropy',
random_state=0)
clf3 = KNeighborsClassifier(n_neighbors=1,
p=2,
metric='minkowski')
pipe1 = Pipeline([['sc', StandardScaler()],
['clf', clf1]])
pipe3 = Pipeline([['sc', StandardScaler()],
['clf', clf3]])
clf_labels = ['Logistic Regression', 'Decision Tree', 'KNN']
print('10-fold cross validation:\n')
for clf, label in zip([pipe1, clf2, pipe3], clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
10-fold cross validation:
ROC AUC: 0.92 (+/- 0.20) [Logistic Regression]
ROC AUC: 0.92 (+/- 0.15) [Decision Tree]
ROC AUC: 0.93 (+/- 0.10) [KNN]
以上の結果からそれぞれの分類きの性能はそんなにかわらないことがわかる
では、アンサンブルな形にしていこう
多数決を使ってクラスラベルを予測するために、個々の分類器をMajorityVoteClassfierで組み合わせてみる
Majority Rule (hard) Voting
mv_clf = MajorityVoteClassifier(classifiers=[pipe1, clf2, pipe3])
clf_labels += ['Majority Voting']
all_clf = [pipe1, clf2, pipe3, mv_clf]
for clf, label in zip(all_clf, clf_labels):
scores = cross_val_score(estimator=clf,
X=X_train,
y=y_train,
cv=10,
scoring='roc_auc')
print("ROC AUC: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
ROC AUC: 0.92 (+/- 0.20) [Logistic Regression]
ROC AUC: 0.92 (+/- 0.15) [Decision Tree]
ROC AUC: 0.93 (+/- 0.10) [KNN]
ROC AUC: 0.97 (+/- 0.10) [Majority Voting]
このようにMajority Votingの方が性能が性能が良い事がわかる
※アンサンブル分類器の評価とチューニングは前回と同じ流れなので飛ばす
バギング:ブートストラップ標本を使った分類器アンサンブルの構築
バギングはアンサンブル学習手法の一つ
ただし、アンサンブルを構成する個々の分類器の学習に同じトレーニングデータセットを使用するのではなく
最初のトレーニングデータセットからブートストラップ標本を抽出(ランダムな復元抽出)
ランダムフォレストはバギングの1形態で、個々の決定木の学習において特徴量をランダムに取得している
バギングは1994年に報告されている
この報告で示されている事は、バギングによって、不安定なモデルの予測制度を向上させ、か学習を予測できる事である
アダブーストによる弱学習器の活用
ブースティングというアンサンブル法を取り上げ、その最も一般的な実装であるアダブーストに着目する
ブースティング
ブースティングでは、アンサンブルは単純な分類器で構成される
ブースティングの概念は、分類の難しいトレーニングサンプルに焦点を合わせている
つまり、誤分類されたトレーニングサンプルをあとから弱学習器に学習させることで
アンサンブルの性能を向上する
このアルゴリズムでは、トレーニングセットからランダムに非復元抽出されたトレーニングサンプルセットを使用する
1,トレーニングセットDからランダムに非復元抽出しd1を作成→弱学習器c1を作成
2,トレーニングセットDからランダムに非復元抽出 +1で誤分類されたサンプルをあとから弱学習器に学習させることでアンサンブルの性能を向上させる
3,トレーニングセットDからC1C2の結果が異なるトレーニングサンプルd3を洗い出し
三つめの弱学習器C3をトレーニングする
4,弱学習器C1,C2,C3を多数決により組み合わせる
ブースティングでは、バギングと比べてバイアスとバリアンスが低くなる事がある
だが実際には、アダブーストなどのブースティングのアルゴリズムはバリアンスが高い事でも知られている
アダブースト
アダブーストでは、トレーニングセット全体を使って弱い学習器をトレーニングする
トレーニングサンプルはイテレーションのたびに重み付けされる
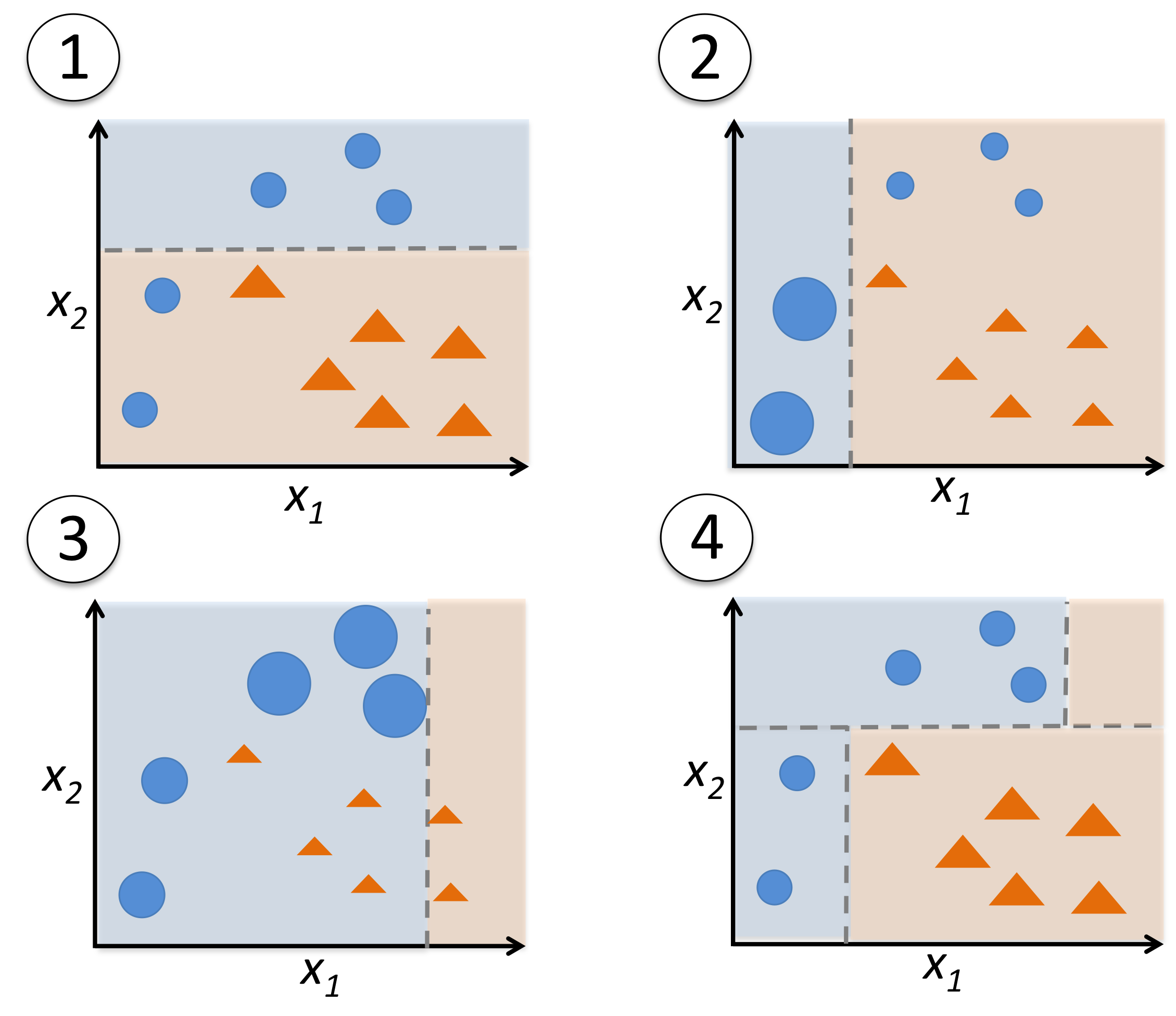
1,全てのトレーニングセットが等しく重み付けされた2値分類のトレーニングセット
これを使用して決定株をトレーニングする
2,二回目のトレーニングセットでは、前回誤分類された二つのサンプルの重みを大きくしている
さらに正しく分類されたサンプルの重みを小さくしている
3,2と同じ
4,トレーニングセットに対して異なる重み付けで学習した三つの弱い弱学習器を重み付けの多数決で組み合わせることになる
擬似コードで見てみる
x:トレーニングデータの特徴行列
y:クラスラベルのベクトル
w:サンプルの重みベクトル
1,サンプルの重みを等しく設定する
\sum_iw_i = 1
2,3~8のステップをm回繰り返す
3,弱学習器Cjをトレーニングする
C_j = train(X,y,w)
4,クラスラベルyを予測する
y' = predict(c_j,X)
5,重み付けされた誤分類率eを計算する
e = w・(y' == y)
6,重みの更新に用いる係数α_jを計算する
α_j = 0.5log\frac{1-e}{e}
7,重みを更新する
w:=w×exp(-α_j × y’× y)
8,重みを正規化し、合計を1にする
w:=\frac{w}{\sum_iw_i}
9,入力された特徴行列Xに対する最終予測y'を計算する
各ステップで推定した重みαjで予測結果を重み付けた平均が0よりも
大きければy_i = 1
小さければy_i = -1
y' = (\sum_{j=1}^{m}(α_j × predict(C_j, X)) > 0)
アダブーストを実装してみる
scikitlearnを使ってアダブーストアンサンブル分類器をトレーニングしてみよう
今回はWineデータセットを使用する
base_estimator引数を使用する事で、500個の決定株でAdaBoostClassifierをトレーニングする
tree = DecisionTreeClassifier(criterion='entropy',
max_depth=1,
random_state=0)
ada = AdaBoostClassifier(base_estimator=tree,
n_estimators=500,
learning_rate=0.1,
random_state=0)
tree = tree.fit(X_train, y_train)
y_train_pred = tree.predict(X_train)
y_test_pred = tree.predict(X_test)
tree_train = accuracy_score(y_train, y_train_pred)
tree_test = accuracy_score(y_test, y_test_pred)
print('Decision tree train/test accuracies %.3f/%.3f'
% (tree_train, tree_test))
ada = ada.fit(X_train, y_train)
y_train_pred = ada.predict(X_train)
y_test_pred = ada.predict(X_test)
ada_train = accuracy_score(y_train, y_train_pred)
ada_test = accuracy_score(y_test, y_test_pred)
print('AdaBoost train/test accuracies %.3f/%.3f'
% (ada_train, ada_test))
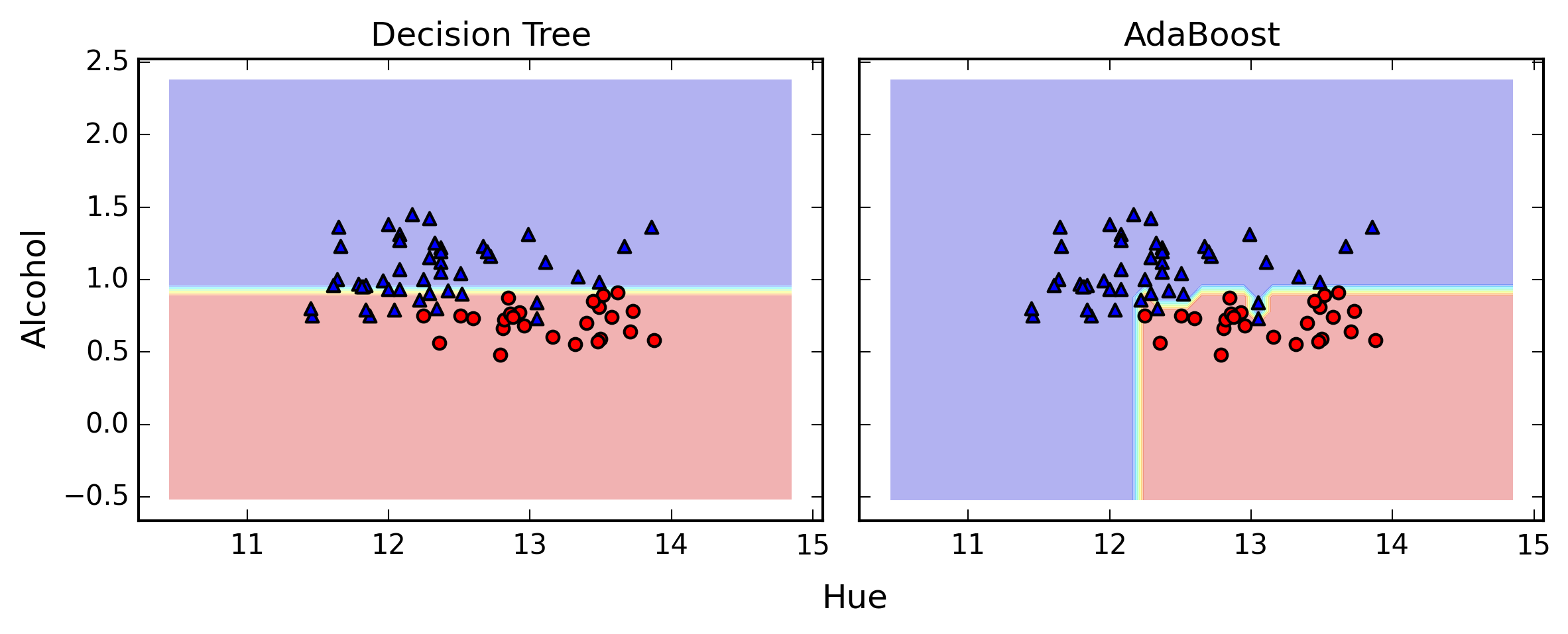
Decision tree train/test accuracies 0.845/0.854
AdaBoost train/test accuracies 1.000/0.875
結果
決定株と比べて性能が上昇している
トレーニングデータセットのクラスラベルが全て正しく予測されている
しかし、バリアンスが増えている
まとめ
・アンサンブル学習は、個々の分類器と比べて計算の複雑さが増す
しかし、多くの場合予測性能の改善は比較的穏やかなものである
現実的には、計算量と性能のトレードオフを検討する必要がある