1,言語データを分類するにあたって、機械学習を使ってどんなことができるか
2,言語処理のタスクを自動的にこなすための言語モデルを構築するにはどうすればよいか
3,そのモデルから言語に関する何を学ぶことができるか
#教師あり分類
分類とは、与えられた入力に対して正しいクラスラベルを選ぶタスクである
・スパムメール診断
・カテゴリー分類
自然言語処理的にはbankという単語を
土手と訳すか、銀行と訳すか
という分類を行う
教師あり分類機のイメージ
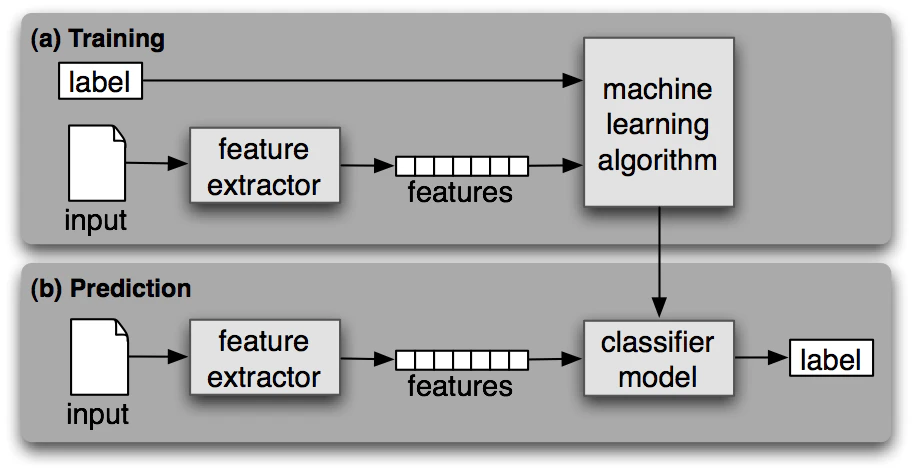
##性別の決定
名前から男女を分類する
分類機を作る最初のステップは
どんな素性が関連しているか決定すること
その素性をどのように符号化するか決定すること
の二つである
性別においては、名前の最後の文字が
a,e,iで終わる名前は女性が多く
k,o,r,s,tで終わる名前は男性が多い
なのでまずは名前の最後の文字を見ることから始める
>>> def gender_features(word):
... return {'last_letter': word[-1]}
>>> gender_features('Shrek')
{'last_letter': 'k'}
次はサンプルデータと対応するクラスラベルを用意する
男性の名前をmale、女性の名前をfemaleとする
>>> from nltk.corpus import names
>>> labeled_names = ([(name, 'male') for name in names.words('male.txt')] +
... [(name, 'female') for name in names.words('female.txt')])
>>> import random
>>> random.shuffle(labeled_names)
これをトレーニングセットとテストセットに分ける
そして「単純ベイズ」分類器にかける
>>> featuresets = [(gender_features(n), gender) for (n, gender) in labeled_names]
>>> train_set, test_set = featuresets[500:], featuresets[:500]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
ここで訓練データに出ていない名前を入れて見る
>>> classifier.classify(gender_features('Neo'))
'male'
>>> classifier.classify(gender_features('Trinity'))
'female'
あっている
テストセットで性能を見て見る
>>> print(nltk.classify.accuracy(classifier, test_set))
0.77
最後にどの素性が名前から性別を判断するのに有効だったかみる
>>> classifier.show_most_informative_features(5)
Most Informative Features
last_letter = 'a' female : male = 33.2 : 1.0
last_letter = 'k' male : female = 32.6 : 1.0
last_letter = 'p' male : female = 19.7 : 1.0
last_letter = 'v' male : female = 18.6 : 1.0
last_letter = 'f' male : female = 17.3 : 1.0
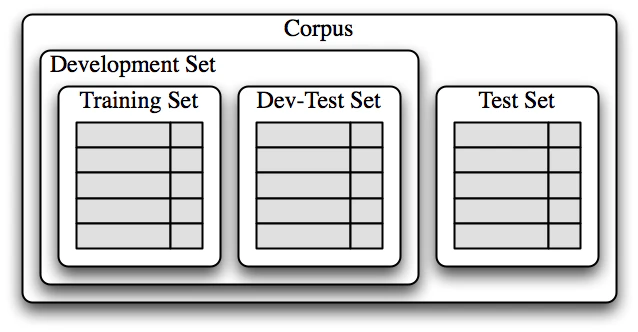
###過学習を避ける
過学習を避けるために、テストセットと開発セットに分ける
さらに検証用に開発セットをトレーニングセットと検証セットにわける
###文書の分類
コーパスを利用して、まだラベル付けされていない文書に適切なカテゴリのラベルを自動的につける分類器を作ることができる
MovieReviewsCorpusにはレビューが肯定的、否定的かで分類されている
>>> from nltk.corpus import movie_reviews
>>> documents = [(list(movie_reviews.words(fileid)), category)
... for category in movie_reviews.categories()
... for fileid in movie_reviews.fileids(category)]
>>> random.shuffle(documents)
コーパス全体から2000個の頻出単語のリストを作成する
そして、それぞれの単語が与えられた文書中に存在するかどうかをチェックする素性抽出器を定義している
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000] [1]
def document_features(document): [2]
document_words = set(document) [3]
features = {}
for word in word_features:
features['contains({})'.format(word)] = (word in document_words)
return features
得られた分類器がどれくらいかをチェックするために
テストセットと使って精度を計算する
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> print(nltk.classify.accuracy(classifier, test_set)) [1]
0.81
>>> classifier.show_most_informative_features(5) [2]
Most Informative Features
contains(outstanding) = True pos : neg = 11.1 : 1.0
contains(seagal) = True neg : pos = 7.7 : 1.0
contains(wonderfully) = True pos : neg = 6.8 : 1.0
contains(damon) = True pos : neg = 5.9 : 1.0
contains(wasted) = True neg : pos = 5.8 : 1.0
セガールが出たら否定的、デイモンがでたら肯定的な感じになる
##品詞のタグ付け
タグつけにあたり、5章では正規表現ダガーを指定した
今回は、どんな接尾辞がもっとも有益であるかを計算する分類器を訓練して行ってみる
まずは頻出する接尾辞を探す
>>> from nltk.corpus import brown
>>> suffix_fdist = nltk.FreqDist()
>>> for word in brown.words():
... word = word.lower()
... suffix_fdist[word[-1:]] += 1
... suffix_fdist[word[-2:]] += 1
... suffix_fdist[word[-3:]] += 1
>>> common_suffixes = [suffix for (suffix, count) in suffix_fdist.most_common(100)]
>>> print(common_suffixes)
['e', ',', '.', 's', 'd', 't', 'he', 'n', 'a', 'of', 'the',
'y', 'r', 'to', 'in', 'f', 'o', 'ed', 'nd', 'is', 'on', 'l',
'g', 'and', 'ng', 'er', 'as', 'ing', 'h', 'at', 'es', 'or',
're', 'it', '``', 'an', "''", 'm', ';', 'i', 'ly', 'ion', ...]
続いて、与えられた単語に対してそれらの接尾辞をチェックする素性抽出器を定義する
>>> def pos_features(word):
... features = {}
... for suffix in common_suffixes:
... features['endswith({})'.format(suffix)] = word.lower().endswith(suffix)
... return features
分類器は入力データをラベル付けする際、それらの目立たせられている属性値だけを利用する
最後に決定木というアルゴリズムによって分類する
【まとめ】
機械学習は自然言語処理に使える
##評価
分類モデルがパターンを正確にとらえることができるかを見るためには、モデルを評価する必要がある。
評価の結果はそのモデルがどれくらい信頼に足るものかを決定するために重要である。
ほとんどの評価手法では、
テストセットからの入力に対してつけたラベルと正しいラベルを比較、突き合わせて確認する。
分類を評価するために利用できるもっとも簡単な評価基準は正解率、つまりテストセットからの入力のうち正しく分類できた割合である。
例えば、100個のうち70個を正しく分類できたら正解率70%である。
nltkにはモデルの正解率を計算する機能がある。
featuresets = [(document_features(d), c) for (d,c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> print(nltk.classify.accuracy(classifier, test_set)) [1]
0.81
また、正解率を見るポイントとしては以下の4つのカテゴリに注意する必要がある。
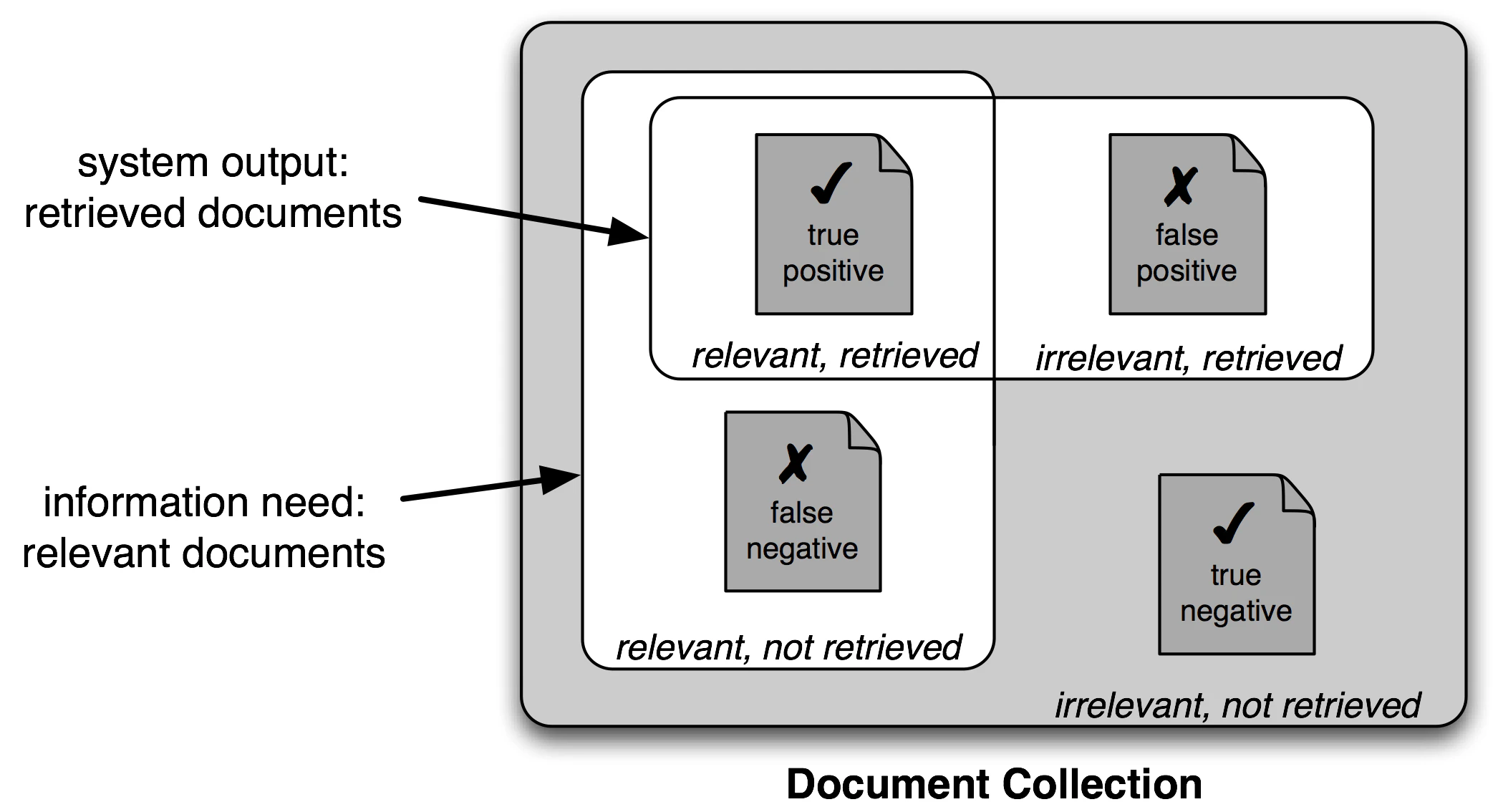
また、これらの値を利用して、以下の測定基準が定義される
・精度
TP/(TP + FP)
関連があると判断した要素のうち、本当に関連があった要素の数
・再現率
TP(TP/FN)
関連がある要素のうちいくつを見つけることができたか
・F値
(2×精度×再現率)/(精度 + 再現率)
精度と再現率を一つにまとめたもの
機械学習に関して、詳しくは下記の本をぜひ読んでみてください。
