記載する予定のもの
- 概要
- インストール方法(CentOS 7にSonarQubeを立ち上げる)
- Maven、Jenkinsを使用してCIに組み込む(今回)
- SonarQubeで行った品質レポートの見方
- SonarQubeのバージョンアップ方法
今回はSonarQubeをCIに組み込むところまでを書こうと思います。
環境は前回の投稿の通りで以下です。
OS:CentOS7
Java:jdk1.8
SonarQube 5.1
MySQL5.6
前回(SonarQubeでプログラムの品質管理をはじめる(インストール))の投稿はこちら
CI環境に組み込むものは以下とします。
CI:Jenkins
SCM:GitHub
ビルダー:Maven
1.Jenkinsのインストール
yumでインストールできるのでyumで入れます。
Jenkinsリポジトリの登録
# cd /etc/yum.repos.d/
# curl -OL http://pkg.jenkins-ci.org/redhat/jenkins.repo
# rpm --import http://pkg.jenkins-ci.org/redhat/jenkins-ci.org.key
インストール
# yum install -y jenkins
自動起動設定
# chkconfig jenkins on
firewallの設定
# firewall-cmd --zone=public --add-port=8080/tcp --permanent
firewallの再起動
# service firewalld restart
jenkinsを動かすのにjavaを使用しますが、
デフォルトで/usr/bin/javaを見に行き、ないと起動エラーになります。
前回の投稿でjavaは上記に入れていませんので、前回入れた場所を見に行くようにします。
/etc/sysconfig/jenkinsを以下のとおり編集します。
JENKINS_JAVA_CMD=""
↓↓↓
JENKINS_JAVA_CMD="/usr/local/java/latest/bin/java"
serviceを起動してブラウザから以下にアクセスしてオッサンのページが出ればJenkinsのインストールはOKです。
http://{Jenkinsをインストールした端末のIPアドレス}:8080
2.Mavenのインストール
以下のコマンドでダウンロードします。
# wget http://ftp.yz.yamagata-u.ac.jp/pub/network/apache/maven/maven-3/3.3.3/binaries/apache-maven-3.3.3-bin.tar.gz
ダウンロードしたら解凍し、移動します。
# tar xvf apache-maven-3.3.3-bin.tar.gz
# mv apache-maven-3.3.3 /opt
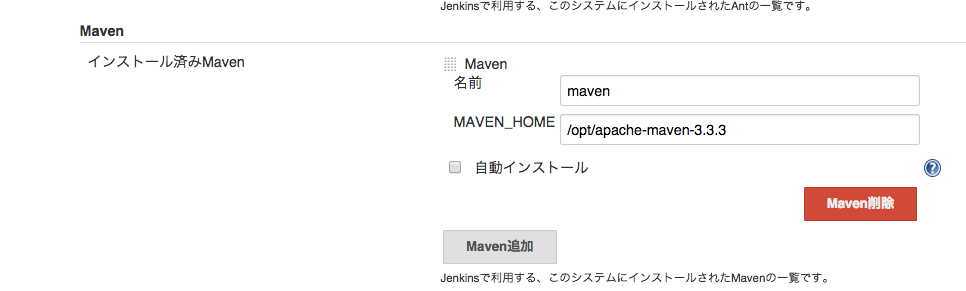
Jenkinsのシステム設定([Jenkinsの管理] - [システム設定])でMAVEN_HOMEを設定します。
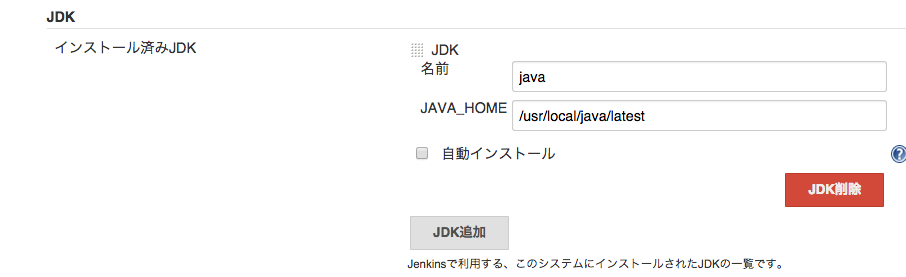
また、このすぐ上にあるJDKの設定についても設定します。
3.JenkinsとGitHub連携
Jenkinsのアップデートセンターで以下のプラグインをインストールします。
Git Plugin
GitHub Plugin
今の環境だとGitが入っていないため、Gitのインストールを行います。
yumでインストールします。
# yum install -y git
4.プロジェクト作成
Jenkinsにプロジェクト作成します。
今回は、Mavenプロジェクトの作成を選んで新規作成します。
ソースコード管理のチェックをgitにし、
URLは以下にします。
https://github.com/sh-ogawa/sonar-maven-demo.git
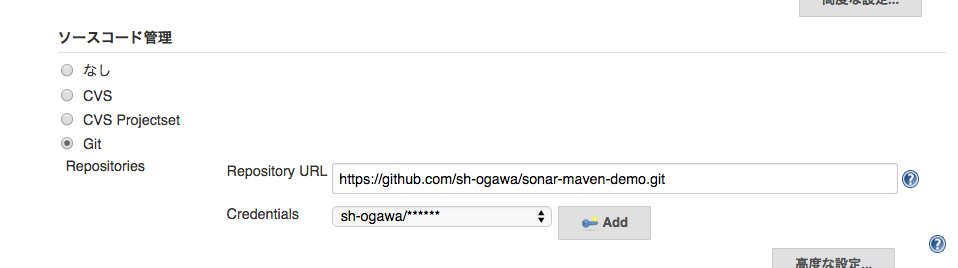
Credentialsの設定は不要です。
ビルドのゴールとオプションに以下を指定します。
clean install -Dmaven.test.skip=true -e
後処理にMavenの呼び出しを指定し、ゴールとオプションを以下にします。
実行は前処理の結果によらず、必ず実行させてください。
sonar:sonar -e
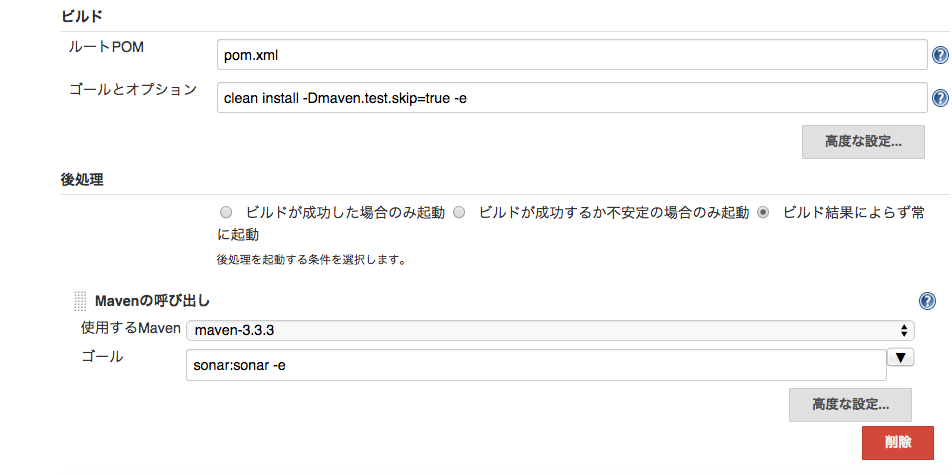
実行を2つに分けているのは、1つにまとめてしまうとtestにエラーがあると後続処理の解析処理(上記のsonar:sonar)が走らないためです。
上記を設定した状態でプロジェクトの設定を保存し、Jenkinsの画面からビルドの実行をポチッとしてあげればテストや解析結果がSonarに取り込まれてWeb画面で見れるようになります。
今回は細かく触れませんが、以下のような画面が出てきます。
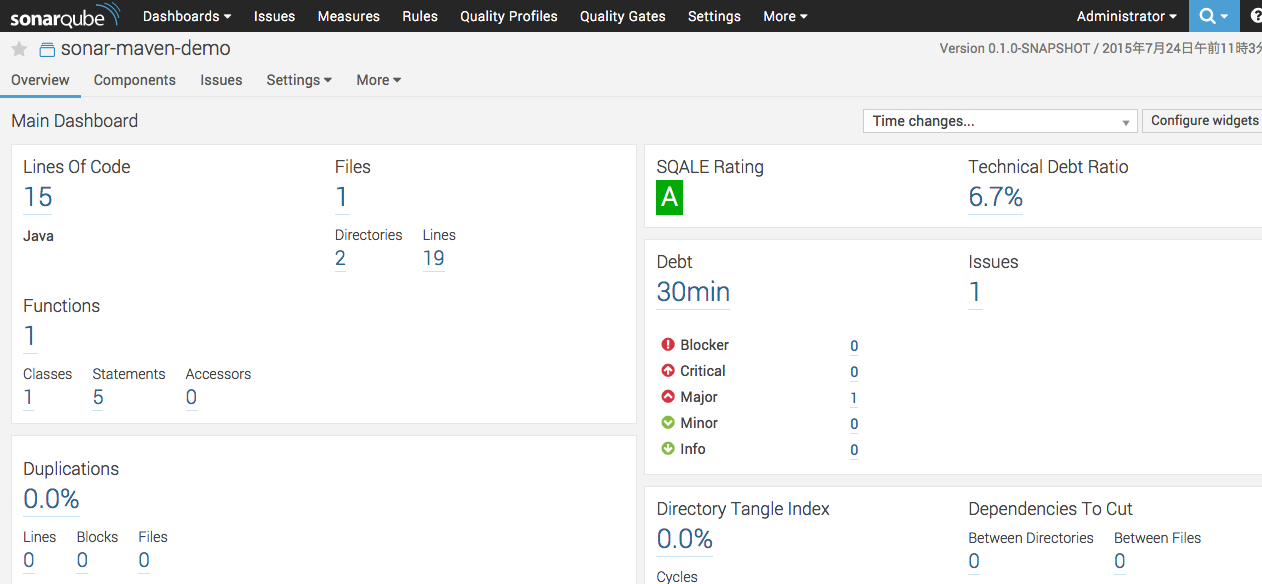
今回は簡単なデモコードで作ってみました。
実際のPJに適応する場合は、対象のコードが変わるだけでやることは同じでできるはずです。
いま現在、junitも使っていないし、CheckStyleみたいな静的解析もしてないよ!というプロジェクトでも、ここまでの設定をすることで始められるようになります。
ただ、サブシステムが適切に分かれていなかったり、長年の保守でなんだかよくわからない巨大なプロジェクトと化しているものには向きません。(と個人的に思っています。)
この4月くらいにそういったプロジェクトで使えるように設定しましたが、
解析が自分のマシンだと3日くらいかかる・・・とか、解析終わってDBに結果をインポートしようとしたら、まさかのSQLクエリバイトサイズの上限オーバーで設定を変えてやり直しとかありました。
少し愚痴が混ざってしまいましたが、大きいプロジェクトに後追いで入れるには、新規で最初から入れるよりも相応のコストがかかります。
もしこの記事を見て既存システムに組み込んでみようと思う人がいましたら、その点だけは注意してください。
これで今回は終わろうと思います。
次回は結果の見方などを書こうと思います。