Distributed computing (Apache Hadoop, Spark, ...) Advent Calendar 2016 の24日目です。この記事では、Hadoop クラスタを手軽に手元に構築したいときに便利な、Apache Bigtop の機能について紹介したいと思います。
Apache Bigtop とは
Apache Bigtop は、Hadoop とその周辺ソフトウェアをビルドし、 deb や rpm といった形式でパッケージ化することで、各種 Linux ディストリビューションへの導入を容易にするためのプロジェクトです。それ以外にも、以下のような機能を持っています。
- 作成したパッケージをクラスタ内の各ノードにデプロイし、適切に設定するためのプロビジョニング機能
- デプロイ結果の確認や、ソフトウェアバージョン間の相互運用性の担保に使われる、統合テスト・スモークテスト機能
- デプロイしたクラスタ上で動作させるためのサンプルアプリや、アプリで使用する業務データのジェネレータ
- 1のプロビジョニングや2の統合テスト・スモークテストを、VirtualBox 上の VM や Docker コンテナに対して実行する機能
この記事では最後の、Docker コンテナに対する Hadoop クラスタのプロビジョニング機能について紹介します。
前提
動作確認には以下の環境を使用しました。
- 環境: Microsoft Azure
- Virtual Machine Size: Standard DS11 v2 (2 cores, 14 GB memory)
- OS: Ubuntu Server 16.04 LTS
また、動作確認時の Bigtop の HEAD リビジョンは以下の通りです。
sekikn@bigtop:~/bigtop$ git rev-parse HEAD
f4d023b4c505efbb3c5b52cb0aa7ceb9dc20cc60
単一ノードでの Hadoop クラスタ構築
起動したクラウド上のマシンにログインし、事前準備を行います。
まず、初期状態だと Docker がインストールされていないので、Docker 本体と docker-compose をインストールします。
その後、Docker サービスを起動するとともに、ユーザを docker グループに追加します (追加後、一度ログアウトする必要があるかもしれません).
sekikn@bigtop:~$ sudo apt-get install docker.io docker-compose
sekikn@bigtop:~$ sudo service docker start
sekikn@bigtop:~$ sudo gpasswd -a sekikn docker
また、後述するスクリプトの実行に必要なので、Ruby もインストールしておきます。
sekikn@bigtop:~$ sudo apt-get install ruby2.3
これで準備が整いましたので、GitHub の Bigtop リポジトリをローカルに clone してきます。
sekikn@bigtop:~$ git clone https://github.com/apache/bigtop.git
そして、Docker 用のプロビジョナを提供しているディレクトリに移動します
sekikn@bigtop:~$ cd bigtop/provisioner/docker
sekikn@bigtop:~/bigtop/provisioner/docker$ ls
config config_centos7.yaml config_debian.yaml config_ubuntu.yaml config.yaml docker-compose.yml docker-hadoop.sh README.md
これらのファイルの役割を簡単に説明します。
-
configディレクトリは、作成されたコンテナにマウントされ、コンテナに対してプロビジョニングや名前解決の情報を提供します。ユーザが編集する必要はありません。 -
config_から始まる YAML ファイルは Docker コンテナ起動時の設定ファイルで、使用する Linux ディストリビューションごとにサンプルが付いています (config_centos7.yaml: CentOS 7, config_debian.yaml: Debian, config_ubuntu.yaml: Ubuntu). 設定ファイルを指定しない場合、config.yamlファイル (CentOS 6) が使われます。ユーザは使いたいディストリビューションに応じて使用するファイルを選択するとともに、ファイルの内容を変更します。 -
docker-compose.ymlは、複数の Docker コンテナを管理するためのツールである docker-compose が使用するファイルです。基本的には編集する必要はありません。 -
docker-hadoop.shが、ユーザが実行するスクリプトです。指定した設定ファイルの記述に従い、docker-compose と連携して、必要なコンテナの起動やプロビジョニングなどを行います。 -
README.mdは、docker-hadoop.shの詳しい使用方法が書いてある、文字通りの README ファイルです。
それでは、クラスタを起動しましょう。使用する設定ファイルは -C オプションで指定しますが、個人的に Ubuntu を使用することが多いことから、config_ubuntu.yaml を指定します。また、-c オプションはクラスタの起動を指示しますが、引数として起動するノードの台数を取ります。今回は単一ノードで起動しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -C config_ubuntu.yaml -c 1
(snip)
Notice: Finished catalog run in 367.28 seconds
コンテナが起動し、プロビジョニングが完了するまで、しばらく時間がかかります。今回の環境では6分ほどで完了しました。
それでは、動作中のコンテナを -l オプションで確認しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -l
WARNING: The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
Name Command State Ports
----------------------------------------------------------
20161204142027r27164_bigtop_1 /sbin/init Up
起動していることが確認できたら、このノードにログインしてみましょう。次のコマンドは、クラスタ内の1台目のノードに対し、bash コマンドを実行することを意味します。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -e 1 bash
WARNING: The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
root@eafb5ee278dc:/#
無事、コンテナにログインできました。少し状態を調べます。
root@eafb5ee278dc:/# jps
10750 JobHistoryServer
11766 Jps
11263 NameNode
10414 ResourceManager
11512 DataNode
10967 NodeManager
10269 WebAppProxyServer
root@eafb5ee278dc:/# hdfs dfs -ls /
Found 7 items
drwxr-xr-x - hdfs hadoop 0 2016-12-04 14:27 /apps
drwxrwxrwx - hdfs hadoop 0 2016-12-04 14:27 /benchmarks
drwxr-xr-x - hbase hbase 0 2016-12-04 14:27 /hbase
drwxr-xr-x - solr solr 0 2016-12-04 14:27 /solr
drwxrwxrwt - hdfs hadoop 0 2016-12-04 14:27 /tmp
drwxr-xr-x - hdfs hadoop 0 2016-12-04 14:27 /user
drwxr-xr-x - hdfs hadoop 0 2016-12-04 14:27 /var
root@eafb5ee278dc:/# yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar pi 100 100
Number of Maps = 100
Samples per Map = 100
(snip)
Job Finished in 226.281 seconds
Estimated value of Pi is 3.14080000000000000000
Hadoop の主要プロセスが起動されており、HDFS や YARN (MRv2) が利用できることがわかります。
Web UI にもアクセスしてみましょう。まず、コンテナのIPアドレスを確認します。
root@eafb5ee278dc:/# ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:ac:11:00:02
inet addr:172.17.0.2 Bcast:0.0.0.0 Mask:255.255.0.0
(snip)
今回はクラウド上のマシンで作業を行っているので、SSHポートフォワードを利用して、コンテナ上で開かれているポートにアクセスします。
以下のコマンドを手元のマシンで実行します。xxx.xxx.xxx.xxx は、クラウド上のマシンのグローバルアドレスです。
sekikn@local:~$ ssh -N -L 50070:172.17.0.2:50070 xxx.xxx.xxx.xxx
この状態で http://localhost:50070/ にアクセスすると、以下のように HDFS Web UI が表示されました。
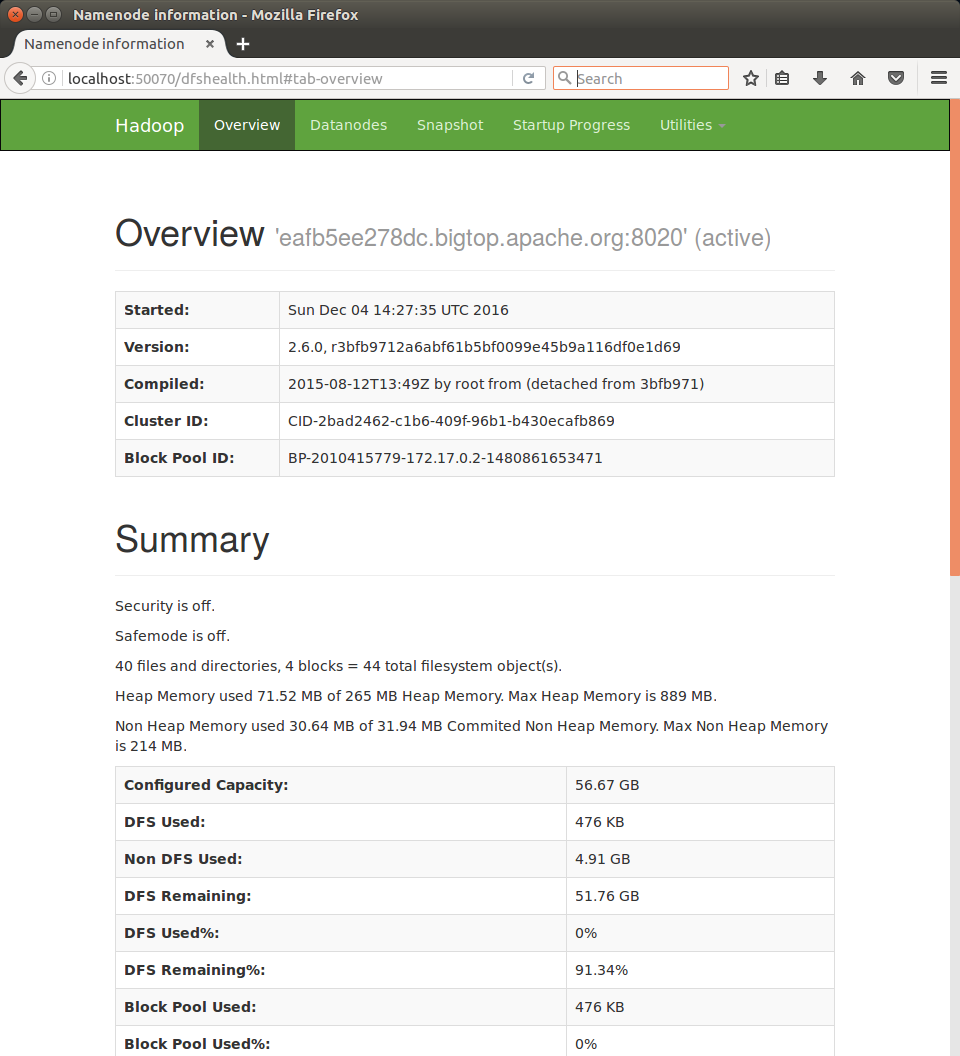
このように、Bigtop のプロビジョニング機能と Docker サポートを使うことで、ものの10分程度で Hadoop クラスタを手元に構築することができました。
複数ノードでの Hadoop クラスタ構築と、追加コンポーネントの導入
さて、上で構築した Hadoop クラスタは、クラスタとは名ばかりの1台構成でした。また、jps の結果からもわかるとおり、Hadoop の基本的な構成要素 (HDFS, YARN) しかインストールされていません。そこで、次はクラスタのノード数を増やすとともに、Hive と Spark といったコンポーネントもインストールしてみましょう。
まず、先ほど作ったクラスタをいったん破棄します。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -d
なお、今回の環境では、上記のコマンド実行時に、以下のエラーが出ていました。
./docker-hadoop.sh: line 128: ./config/hosts: Permission denied
このファイルは、コンテナ起動時に各コンテナに付与されたホスト名とIPアドレスの対応関係が書き込まれた後、Docker コンテナ上に /etc/hosts としてマウントされることで、各ノードの名前解決に使われます。前回の設定が残ってしまっているので、チェックアウト時の状態 (空) に戻しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ git status
(snip)
modified: config/hosts
no changes added to commit (use "git add" and/or "git commit -a")
sekikn@bigtop:~/bigtop/provisioner/docker$ git checkout config/hosts
sekikn@bigtop:~/bigtop/provisioner/docker$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory clean
そして、設定ファイルを編集し、インストールされるコンポーネントに Hive と Spark を追加しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ vi config_ubuntu.yaml # 以下の行を変更する
sekikn@bigtop:~/bigtop/provisioner/docker$ git diff
diff --git a/provisioner/docker/config_ubuntu.yaml b/provisioner/docker/config_ubuntu.yaml
index e4ea6f3..e5fcd01 100644
--- a/provisioner/docker/config_ubuntu.yaml
+++ b/provisioner/docker/config_ubuntu.yaml
@@ -23,7 +23,7 @@ boot2docker:
repo: "http://bigtop-repos.s3.amazonaws.com/releases/1.0.0/ubuntu/trusty/x86_64"
distro: debian
-components: [hadoop, yarn]
+components: [hadoop, yarn, hive, spark]
namenode_ui_port: "50070"
yarn_ui_port: "8088"
hbase_ui_port: "60010"
それでは、-C オプションの引数に変更後の設定ファイルを、-c オプションの引数にノード数 (5とします) を指定して、docker-hadoop.sh を実行しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -C config_ubuntu.yaml -c 5
(snip)
Notice: Finished catalog run in 566.56 seconds
起動するコンテナの数と、インストールするコンポーネントの数が増えた分、構築に必要な時間が少し伸びて、10分弱かかりました。では、5つのコンテナが起動していることを確認しましょう。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -l
WARNING: The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
Name Command State Ports
----------------------------------------------------------
20161204153854r30862_bigtop_1 /sbin/init Up
20161204153854r30862_bigtop_2 /sbin/init Up
20161204153854r30862_bigtop_3 /sbin/init Up
20161204153854r30862_bigtop_4 /sbin/init Up
20161204153854r30862_bigtop_5 /sbin/init Up
複数台構成の場合は、最初の1ノードがマスター、それ以外はスレーブという扱いになります。
それではマスターサーバにログインして、追加したコンポーネントが使えることを確認しましょう。まずは Hive です。
sekikn@bigtop:~/bigtop/provisioner/docker$ ./docker-hadoop.sh -e 1 bash
WARNING: The DOCKER_IMAGE variable is not set. Defaulting to a blank string.
root@3fde12cd3334:/# hive
(snip)
hive> create table hoge(fuga string);
OK
Time taken: 0.815 seconds
hive> insert overwrite table hoge values ('foo'), ('bar');
Query ID = root_20161204155353_7f63418d-ed5d-4978-8f31-dfc76c7b80fb
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1480866447700_0001, Tracking URL = http://3fde12cd3334.bigtop.apache.org:20888/proxy/application_1480866447700_0001/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1480866447700_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2016-12-04 15:53:19,603 Stage-1 map = 0%, reduce = 0%
2016-12-04 15:53:26,892 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.94 sec
MapReduce Total cumulative CPU time: 940 msec
Ended Job = job_1480866447700_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://3fde12cd3334.bigtop.apache.org:8020/tmp/hive/root/c0a3b0f9-e833-4e52-9bf9-f4893cc77289/hive_2016-12-04_15-53-10_742_4565711671967633591-1/-ext-10000
Loading data to table default.hoge
Table default.hoge stats: [numFiles=1, numRows=2, totalSize=8, rawDataSize=6]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 0.94 sec HDFS Read: 302 HDFS Write: 76 SUCCESS
Total MapReduce CPU Time Spent: 940 msec
OK
Time taken: 17.571 seconds
hive> select count(*) from hoge;
Query ID = root_20161204155353_a3977e8c-b08b-4e2a-b665-2a62dbf1ab92
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1480866447700_0002, Tracking URL = http://3fde12cd3334.bigtop.apache.org:20888/proxy/application_1480866447700_0002/
Kill Command = /usr/lib/hadoop/bin/hadoop job -kill job_1480866447700_0002
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2016-12-04 15:53:41,241 Stage-1 map = 0%, reduce = 0%
2016-12-04 15:53:47,492 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.82 sec
2016-12-04 15:53:52,679 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 1.8 sec
MapReduce Total cumulative CPU time: 1 seconds 800 msec
Ended Job = job_1480866447700_0002
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 1.8 sec HDFS Read: 238 HDFS Write: 2 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 800 msec
OK
2
Time taken: 18.505 seconds, Fetched: 1 row(s)
問題なく使えているようです。次は Spark です。
root@3fde12cd3334:/# spark-shell
tput: No value for $TERM and no -T specified
16/12/04 16:00:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/12/04 16:00:59 INFO SecurityManager: Changing view acls to: root
16/12/04 16:00:59 INFO SecurityManager: Changing modify acls to: root
16/12/04 16:00:59 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)
16/12/04 16:00:59 INFO HttpServer: Starting HTTP Server
16/12/04 16:00:59 INFO Server: jetty-8.y.z-SNAPSHOT
16/12/04 16:00:59 INFO AbstractConnector: Started SocketConnector@0.0.0.0:35650
16/12/04 16:00:59 INFO Utils: Successfully started service 'HTTP class server' on port 35650.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.3.1
/_/
(snip)
scala> sc.parallelize(1 to 100).filter(_ % 2 == 0).count
16/12/04 16:02:54 INFO SparkContext: Starting job: count at <console>:22
16/12/04 16:02:54 INFO DAGScheduler: Got job 0 (count at <console>:22) with 2 output partitions (allowLocal=false)
16/12/04 16:02:54 INFO DAGScheduler: Final stage: Stage 0(count at <console>:22)
16/12/04 16:02:54 INFO DAGScheduler: Parents of final stage: List()
16/12/04 16:02:54 INFO DAGScheduler: Missing parents: List()
16/12/04 16:02:54 INFO DAGScheduler: Submitting Stage 0 (MapPartitionsRDD[1] at filter at <console>:22), which has no missing parents
16/12/04 16:02:54 INFO MemoryStore: ensureFreeSpace(1776) called with curMem=0, maxMem=278302556
16/12/04 16:02:54 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1776.0 B, free 265.4 MB)
16/12/04 16:02:54 INFO MemoryStore: ensureFreeSpace(1285) called with curMem=1776, maxMem=278302556
16/12/04 16:02:54 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1285.0 B, free 265.4 MB)
16/12/04 16:02:54 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 3fde12cd3334.bigtop.apache.org:36932 (size: 1285.0 B, free: 265.4 MB)
16/12/04 16:02:54 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
16/12/04 16:02:54 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:839
16/12/04 16:02:54 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[1] at filter at <console>:22)
16/12/04 16:02:54 INFO YarnScheduler: Adding task set 0.0 with 2 tasks
16/12/04 16:02:54 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, 59ee358fd33a.bigtop.apache.org, PROCESS_LOCAL, 1260 bytes)
16/12/04 16:02:54 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, 479b6117c03a.bigtop.apache.org, PROCESS_LOCAL, 1317 bytes)
16/12/04 16:02:55 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 479b6117c03a.bigtop.apache.org:38012 (size: 1285.0 B, free: 530.3 MB)
16/12/04 16:02:55 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on 59ee358fd33a.bigtop.apache.org:45933 (size: 1285.0 B, free: 530.3 MB)
16/12/04 16:02:55 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 677 ms on 479b6117c03a.bigtop.apache.org (1/2)
16/12/04 16:02:55 INFO DAGScheduler: Stage 0 (count at <console>:22) finished in 0.717 s
16/12/04 16:02:55 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 714 ms on 59ee358fd33a.bigtop.apache.org (2/2)
16/12/04 16:02:55 INFO DAGScheduler: Job 0 finished: count at <console>:22, took 0.928298 s
16/12/04 16:02:55 INFO YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
res0: Long = 50
こちらも問題ないようです。
まとめ
Hadoop クラスタを Docker コンテナ上にお手軽に構築することができる、Apache Bigtop の機能を紹介しました。
今回の手順では、Bigtop が提供している公開リポジトリからダウンロードされたパッケージがインストールされますが、代わりに自作のパッケージをインストールしたり、その状態で Bigtop が提供するテスト群を実行したりすることも可能です。詳細は bigtop/provisioner/docker/README.md などをご参照ください。
また、Docker が利用できない環境では、VirtualBox 上に Vagrant で構築した VM 上に Hadoop ソフトウェアスタックをインストールすることもできます。bigtop-deploy/vm/vagrant-puppet-vm 以下のファイル群をご参照ください。docker-hadoop.sh コマンドの代わりに vagrant up コマンドで VM を起動するなど、細かい違いはありますが、概ね上記の知識が流用できます。たとえば、設定ファイルである vagrantconfig.yaml の記述方法は Docker 版の config_ ファイル群と同様です。