この記事はPostgreSQL Advent Calendar 2016 の2日目の記事です。
少し前にpgpool + EC2にホストしたPostgresqlを、pgpool + RDS for Postgresqlに変更するという構成変更を行ったのですが、その時に、ネット上であまり似たような事例を見つけられなかったので、まとめてみました。
TL;DR
pgpool + RDS for Postgresqlの組み合わせ便利!
What is pgpool?
- PostgreSQL サーバとクライアントの間に入ってプロキシサーバとして動作するソフトウェア
- connection poolingや、様々な方法でのPostgresqlのクラスタ管理(クエリの分散、Postgresqlサーバに異常があった時のハンドリング etc..)を行うことができる
- 詳細はここにまとめられています http://lets.postgresql.jp/documents/technical/pgpool/1/
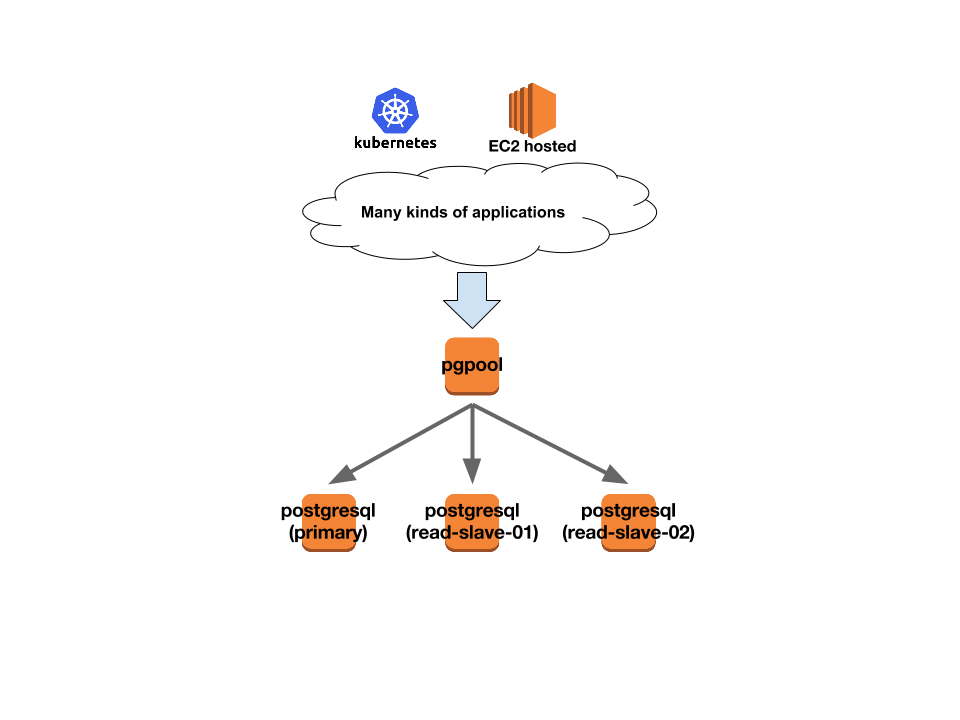
before
- pgpool + postgreql 3台のclusterをEC2上にhost
- streaming replicationでreplicatinさせ、pgpoolがclusterの管理やfailoverを担当
- 各アプリケーション(kubernetes cluster上 or EC2上)はpgpool EC2インスタンスに接続
- 2年半くらい前、SPOFとなっていたPostgresqlを、pgpoolを使ったクラスタ構成に移したが、この時の移行時にはRDS for postgresqlが無かった
problem with the previous architecture
- database clusterを運用に対するコストや人的な依存の発生
- pgpoolの柔軟性との引き換えに、failover時のリカバリの仕組みが少し複雑だが、滅多に起きない事象かつDB専門チームではないなので、記憶を退化させない and 人が入れ替わっていく中で知識をkeep up to dateし続けることが難しい。しかし、起きた時はめちゃくちゃクリティカル...
- pgpoolの柔軟性との引き換えに、failover時のリカバリの仕組みが少し複雑だが、滅多に起きない事象かつDB専門チームではないなので、記憶を退化させない and 人が入れ替わっていく中で知識をkeep up to dateし続けることが難しい。しかし、起きた時はめちゃくちゃクリティカル...
参考:
http://www.pgpool.net/docs/latest/pgpool-en.html#online-recovery
-
primary failoverの発動コストが高い
- 新しいprimaryとslaveの間でdata directory全体のrsyncが走るため、DBが大きくなるにつれ、時間がかかるように。(pg-rewind というPostgresql9.5からの機能を使えば改善できそう)
- failoverして、最初のslaveが上がってくるまでは、DB一台状態なので、syncが終わるまでかなりドキドキ
- 実際にはサーバが壊れるという事象には遭遇せず、heavy queryが大量に入ってきてdbが一時的に応答不能、AWSのネットワークの瞬断等、(pgpoolのプログラムとしては正しい挙動ではあるものの、)こっち的にはfailoverをtriggerして欲しくない時にtriggerされ、その度に不要なドキドキがあった
clusterのinitial set-up を完全に自動化することが難しく、もう一つ別の環境を作ろうとなった時にある程度の時間がかかり、インフラ全体のコード化(cloudformation, teraform等)のブロッカーになっている
Let's use RDS!!
- 他プロジェクトで1年以上利用してきたが、安定してるし、とても楽チン。
why only RDS is not enough?
- pgpoolはclusterの管理に加え、insert/update/delete はprimaryへ、selectはslaveへという振り分けも行っており、このfunctionalityを担う何かが必要
- アプリケション側での振り分けも可能 (e.g. https://github.com/eagletmt/switch_point) だが、3つのプログラミング言語のアプリケーションが存在し、各プログラミング言語毎にライブラリを探して(or 作って) 、各アプリケーション毎にその実装を入れるというコストは避けたかった。
- アプリケーションで振り分けをやるとslaveの増減等、postgresqlのcluster構成を変更する時、全アプリケーションに設定をばらまく必要があるが、pgpoolだと、そこに情報を集約できる
resolution
- pgpoolをコンテナにして、各アプリケーションはそのコンテナに接続
- 大半のapplicationはkubernetes上で動いているので、pgpoolをserviceとして動かし、各アプリケーションは環境関係なく
pgpoolというhostに接続 - 複数のpgpoolコンテナを立てた時のload balanceはkubernetes任せ
- (EC2 hosted applicationは負荷の少ない社内ツールばかりなので暫定的にRDSに直接接続。)
- 大半のapplicationはkubernetes上で動いているので、pgpoolをserviceとして動かし、各アプリケーションは環境関係なく
- queryのdistributionはpgpoolが担当
- failoverの管理はRDSにお任せ
- RDSはprimaryのfailover時、end-pointはそのままにinstanceの切り替えが行われるので、pgpoolのconfigのbackend_flag を
DISALLOW_TO_FAILOVERにset
The failover mechanism automatically changes the DNS record of the DB instance to point to the standby DB instance.
As a result, you will need to re-establish any existing connections to your DB instance.
- slaveはcost削減のためにmulti-AZにしていないので、
ALLOW_TO_FAILOVERにset- pgpoolが全てのslaveをhealtyと認識しているかは別途monitoringし、unhealthyになっていた時にはalertを飛ばす
- 一時的なネットワークのダウンなのか、実際にインスタンスが壊れたかの判断が必要なので、ここは手動復旧にした (最終的にはここも自動で復旧できるようにしたい)
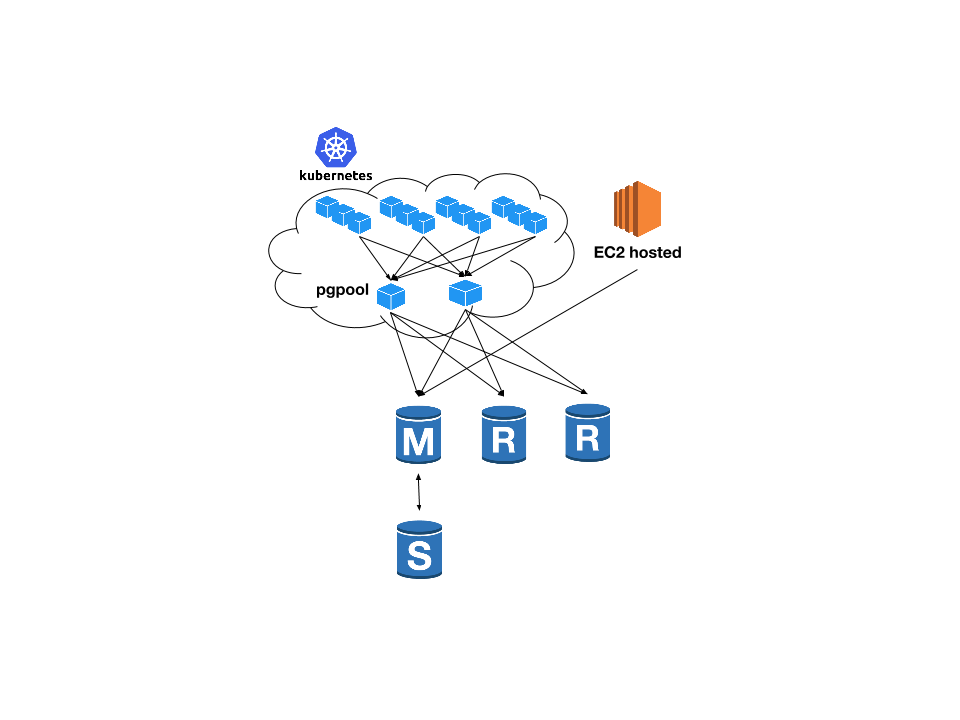
after
- pgpoolとRDSのいい所どりができた
- postgresqlのcluster構築やfailoverという、技術的にも心理的にもコストの高い運用はRDSに外出し
- クエリの振り分けやcluster情報の管理はpgpoolに集約。各アプリケーションは何も考えずにpgpoolにqueryを投げればOK
- pgpoolではpgpoolによるfailoverでは、slaveがprimaryに昇格するため、slaveもprimaryと同じインスタンスタイプにし、queryの振り分けを均等なweightにしていたが、新しい構成ではslaveがprimaryになることはないので、slaveはcheapなインスタンスを利用したり、多くのweightを持たせることが容易で、scale outしやすくなった。
- postgresqlのcluster構築やfailoverという、技術的にも心理的にもコストの高い運用はRDSに外出し
- 新しいpostgresql clusterの構築が容易になった
- 環境一式をcloudformation化やterraform化もできるはず
- サーバコストだけ見ると、RDSはEC2上にホスティングしての自前運用に比べてちょっとお高くはなるけど、自分たちの規模であれば運用コスト等を踏まえると、十分にペイすると思う
appendix
- 今回は他の要素との兼ね合いでpgpoolをcontainer化してkubernetes上で動かしましたが、EC2上にpgpoolをhostして、その手前でhaproxyでバランシングさせるとか、他の方法でもこのメリットは教授できるはず
- pgpoolを動かすhostでは
net.core.somaxconnの値に注意。 http://lets.postgresql.jp/documents/technical/pgpool-II-tcp-tuning/1/ - RDSのparameterはdefaultのままではなく、この記事等を参考に、ちょこちょこといじりました
http://qiita.com/awakia/items/9981f37d5cbcbcd155eb - DBの移行はメンテナンス時間を設けて、普通にpg_dump/pg_restoreでやりました。ここで紹介されている
LondisteやBucardoといったようなツールを使えば、ダウンタイムを短くできるようですが、今回は移行計画を早く進めることに重点を置き、試しませんでした
https://aws.amazon.com/blogs/aws/rds-postgres-read-replicas/
また、pg_dump,pg_restoreのパラメータについてはここにまとめました
http://qiita.com/seikoudoku2000/items/46d77452cf18bfea1209