音声認識を手軽に使いたい!という方必見.
googleの音声認識WebAPIのように使える音声認識サーバを立ち上げよう!
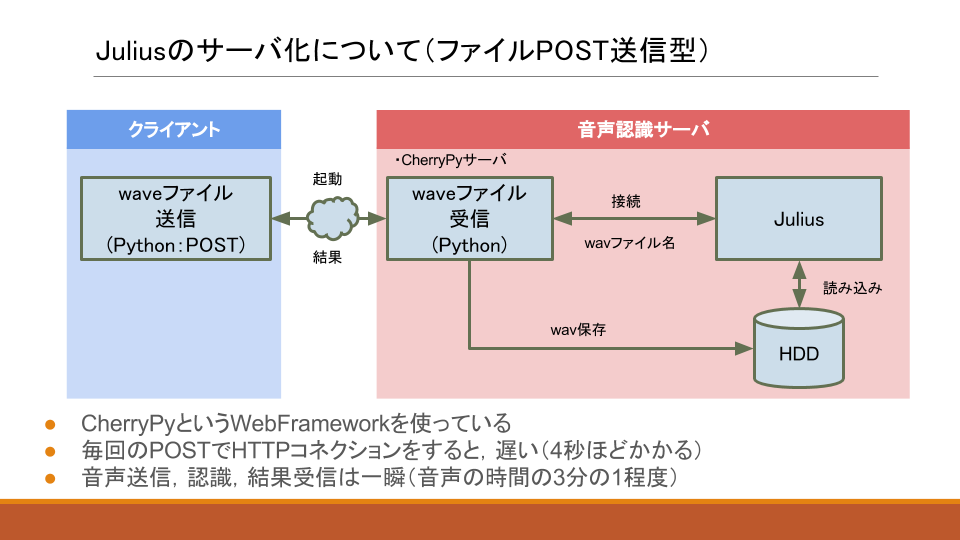
Juliusサーバに,音声ファイルをPOST送信することで,音声認識結果が返ってくるという,サーバの構築方法を以下に記載します.
Pepperで音声認識させる場合,元から入っている音声認識ソフトウェアだと,音声認識させたい単語をChoregrapheなどで予め入れておく必要があり,なんでも認識できるというわけではありません(Qiitaの記事:Pepperは人間が喋った任意の言葉を認識できるか?).
(できるかもしれないけど,面倒くさい)
そこで,Pepperアプリ開発者がたどり着くのが,google音声認識です.Pepperのマイクからの音を録音して,googleに音をPOST送信して,結果を受け取るものです.認識できる言葉は多いし,認識精度も良いのですが,結果が返ってくるまでの時間がとても遅く,API使用回数制限もあり,実用に耐えません.
NICTが公開しているRaSCというオープンソース・ソフトウェアがあり,これが使えれば,Juliusと共に用いることで,とても良い音声認識サーバが構築できますが,私は動作させることができませんでした.CentOSじゃないとできないのかな??私はUbuntuで何度か挑戦しましたが,うまくいかないので諦めました.
使うソフトウェア
・Julius:汎用大語彙連続音声認識エンジン
・Python
・CherryPy:Web Framework
サーバ構築環境
- Ubuntu14.04日本語版
1.Juliusインストール
1.1ソースをダウンロードしてコンパイル
$ cd ~/Downloads
$ wget --trust-server-names "http://osdn.jp/frs/redir.php?m=iij&f=%2Fjulius%2F60273%2Fjulius-4.3.1.tar.gz"
$ tar zxvf julius-4.3.1.tar.gz
$ cd julius-4.3.1
$ ./configure
$ make
1.2音声認識用モデルをダウンロード
$ cd ~/Downloads
$ wget --trust-server-names 'http://osdn.jp/frs/redir.php?m=iij&f=%2Fjulius%2F60416%2Fdictation-kit-v4.3.1-linux.tgz'
$ tar xvzf dictation-kit-v4.3.1-linux.tgz
1.3ディレクトリ構成を綺麗にする
~/Software/julius の下に,コンパイルしたjuliusバイナリと音声認識用モデルを置く.
$ cd ~
$ mkdir -p ~/Software/julius
$ cp ~/Downloads/julius-4.3.1/julius/julius ~/Software/julius/.
$ mv ~/Downloads/dictation-kit-v4.3.1-linux ~/Software/julius/julius-kit
1.4テスト用音声ダウンロード(私の声です(´・ω・`))
「これはマイクのテストです」というwavファイルをダウンロード
$ cd ~/Software/julius
$ mkdir test_wav
$ cd test_wav
$ wget http://sayonari.com/data/test_16000.wav
音を聞いてみたい場合には,play test_16000.wavを実行すれば良い.(実行には,soxがインストールされている必要がある.)
1.5音声認識テスト
$ cd ~/Software/julius/
$ ./julius -C ./julius-kit/am-gmm.jconf -C ./julius-kit/main.jconf -input rawfile
実行すると以下のように表示される
(何やらザザザーっと表示されて)
----------------------- System Information end -----------------------
Notice for feature extraction (01),
*************************************************************
* Cepstral mean normalization for batch decoding: *
* per-utterance mean will be computed and applied. *
*************************************************************
------
### read waveform input
enter filename->
認識させたいファイル名./test_wav/test_16000.wavを入力すると以下のように出力される.
### read waveform input
enter filename->./test_wav/test_16000.wav
Stat: adin_file: input speechfile: ./test_wav/test_16000.wav
STAT: 52832 samples (3.30 sec.)
STAT: ### speech analysis (waveform -> MFCC)
### Recognition: 1st pass (LR beam)
........................................................................................................................................................................................................................................................................................................................................pass1_best: これ は マイク の テイスト です 。
pass1_best_wordseq: <s> これ+代名詞 は+助詞 マイク+名詞 の+助詞 テイスト+名詞 です+助動詞 </s>
pass1_best_phonemeseq: silB | k o r e | w a | m a i k u | n o | t e: s u t o | d e s u | silE
pass1_best_score: -7939.280273
### Recognition: 2nd pass (RL heuristic best-first)
STAT: 00 _default: 33334 generated, 3165 pushed, 363 nodes popped in 328
sentence1: これ は マイク の テスト です 。
wseq1: <s> これ+代名詞 は+助詞 マイク+名詞 の+助詞 テスト+名詞 です+助動詞 </s>
phseq1: silB | k o r e | w a | m a i k u | n o | t e s u t o | d e s u | silE
cmscore1: 0.564 0.538 0.329 0.399 0.227 0.131 0.588 1.000
score1: -7946.526367
------
### read waveform input
enter filename->
これでJuliusインストールは成功
2.Webサーバのインストール
CherryPyというシステムを用いて,Juliusをサーバー化させる.
http://www.cherrypy.org/
2.1CherryPyのインストール
$ cd ~/Downloads
$ wget https://pypi.python.org/packages/source/C/CherryPy/CherryPy-3.8.1.tar.gz#md5=919301731c9835cf7941f8bdc1aee9aa
$ tar zxvf CherryPy-3.8.1.tar.gz
$ cd CherryPy-3.8.1
$ sudo python setup.py install
2.2ASRサーバ起動
サーバ起動用のPythonスクリプト
ASRServer.py
サーバ用スクリプトの7行目から13行目までが,設定項目になっています.
特に,JULIUS_HOME,ASR_FILEPATHは,絶対に設定を変更する必要があります.
JULIUS_HOMEは,juliusの実行バイナリがあるディレクトリ.
ASR_FILEPATHは,音声認識用の音声ファイルや出力テキストなどを保存しておく,temporary的なディレクトリ.
### configure ###########
JULIUS_HOME = "/home/nishimura/Software/julius/."
JULIUS_EXEC = "./julius -C ./julius-kit/am-gmm.jconf -C ./julius-kit/main.jconf -input file -outfile"
SERVER_PORT = 8000
ASR_FILEPATH = '/home/nishimura/Public/asr/'
ASR_IN = 'ch_asr.wav'
ASR_RESULT = 'ch_asr.out'
OUT_CHKNUM = 5 # for avoid that the output file is empty
以下のように実行すると,localhostの8000番ポートに,音声認識サーバが立ち上がります.
$ python ASRServer.py
動作説明(上記pythonスクリプト)
- juliusを
-input file(ファイル入力)モードで起動 - 標準入力からファイル名を入れると,そのファイルの認識を行う
- 外部サーバから,POSTでwaveファイルを送信
- サーバ上の
/home/nishimura/Public/asr/ch_asr.wavに上書き - このファイルをjuliusで認識
- 認識結果を
/home/nishimura/Public/asr/ch_asr.outに出力- 出力用ファイル
ch_asr.outは,毎回消される - juliusから.outファイルが生成された後,出力結果が5行になるまでループで待つ
- (待たないと,ファイル内容が無いうちに,中身0なファイルを出力して処理が完了してしまう)
- 出力用ファイル
2.3クライアントからの使い方
waveデータを,サーバに対してPOST送信すれば良い.Pythonでは,requestsライブラリを用いると簡単にPOST送信できる.requestsが入っていない場合には,以下のようにして入れると良い.
$ pip install requests
2.3.1クライアントスクリプト
requestsを用いたPOST送信の方法は以下のとおり.urlとfilesの中のwavファイル名は,各自書き換えること.
ASRClient_simple.py
音声ファイル:test_16000.wav
(※音声ファイルは,「右クリック→ファイルへ保存」などで保存してください.)
import requests
url = "http://nishimura-asr.local:8000/asr_julius"
files = {
'myFile': open('test_16000.wav', 'rb')
}
s = requests.Session()
r = s.post(url, files=files)
print r.text
POST送信する際に,毎回セッションを張り直していると,接続がとても遅くなるので,上記スクリプト内であるように,s = requests.Session()でセッションを張り,以降はそれを再利用すると早くなる.
例)
s = requests.Session()
r = s.post(url, files=files)
print r.text
r = s.post(url, files=files2)
print r.text
r = s.post(url, files=files3)
print r.text
2.3.2POST用セッションの接続時間チェック
また,以下のクライアント用スクリプトを用いると,セッションを張るのにかかった時間,再接続時の音声認識の時間などの確認ができます.
ASRClinet.py
音声ファイル:test_16000.wav
音声ファイル:long_16000.wav
音声ファイル:yokohama_16000.wav
(※音声ファイルは,「右クリック→ファイルへ保存」などで保存してください.)
2.4おまけ
webブラウザを用いて,直接サーバにアクセスすると,音声ファイルアップロードフォームが表示されます.そこから,PC上の16kHz,monoのwavファイルを選択してアップロードすると,音声認識結果がブラウザで確認できます.
同一マシン上からなら http://localhost:8000/
別マシンからなら http://IPorホスト名指定:8000/
例)http://nishimura-asr.local:8000/