Dataprepとは?
端的に言うとデータを準備するツールです。
大きなデータでも、様々な技術で簡単に扱えるようになり『データの民主化』という言葉が出てきました。しかし、データソースを加工するのはバッチなどで処理をするため、プログラムを組んだりエンジニアが介在している部分が多くありました。
それすらももっと簡単に出来ないか?データの使い手側が自身で出来ないか?という議論が生まれ、このようなツールが生まれました。
ちなみにDataprepそのものはGoogleが開発したわけではなく、TrifactaというツールをGoogleCloudPlatform上で実装したものになります。
まだアクセス権を付与されていない人で試したい方はTrifactaのデスクトップ版をダウンロードして使ってみてください。
※注:2017/04/08時点ではPrivateBetaですので、本記事で記載している画面や機能はGAの際には違うものになっている可能性があります。
対応しているフォーマット
データソース側はDataprepの画面から直接アップロードも可能ですし、CloudStorageに保存されているデータでも可能です。文字コードはUTFのみ対応しているようです。
また、BigQueryのテーブルを参照することも可能です。
- Excel(XLS/XLSX) ←GCPでExcelってシュール!
- CSV
- JSON
- Plain Text
- Avro
- BigQuery
処理後のデータは同じようにCloudStorageに保存したり、Avroで出力されてBigQueryへ投入することも可能です。
- CSV
- JSON
- Avro
実際に触ってみる
処理の流れなどをどのように説明しようかと思いましたが、実際に触って画面を見ながらの方が早そうだなと。
今回は用意したCSVファイルを少しデータを処理してBigQueryに取り込んでみます。
youtubeでも紹介されているので、こちらも是非観てください。
Dataprepのコンソール
最初にアクセスすると、Flowの画面が表示されます。まだ何も使っていないので表示されません。
まずは処理するデータソースを選択していきましょう。
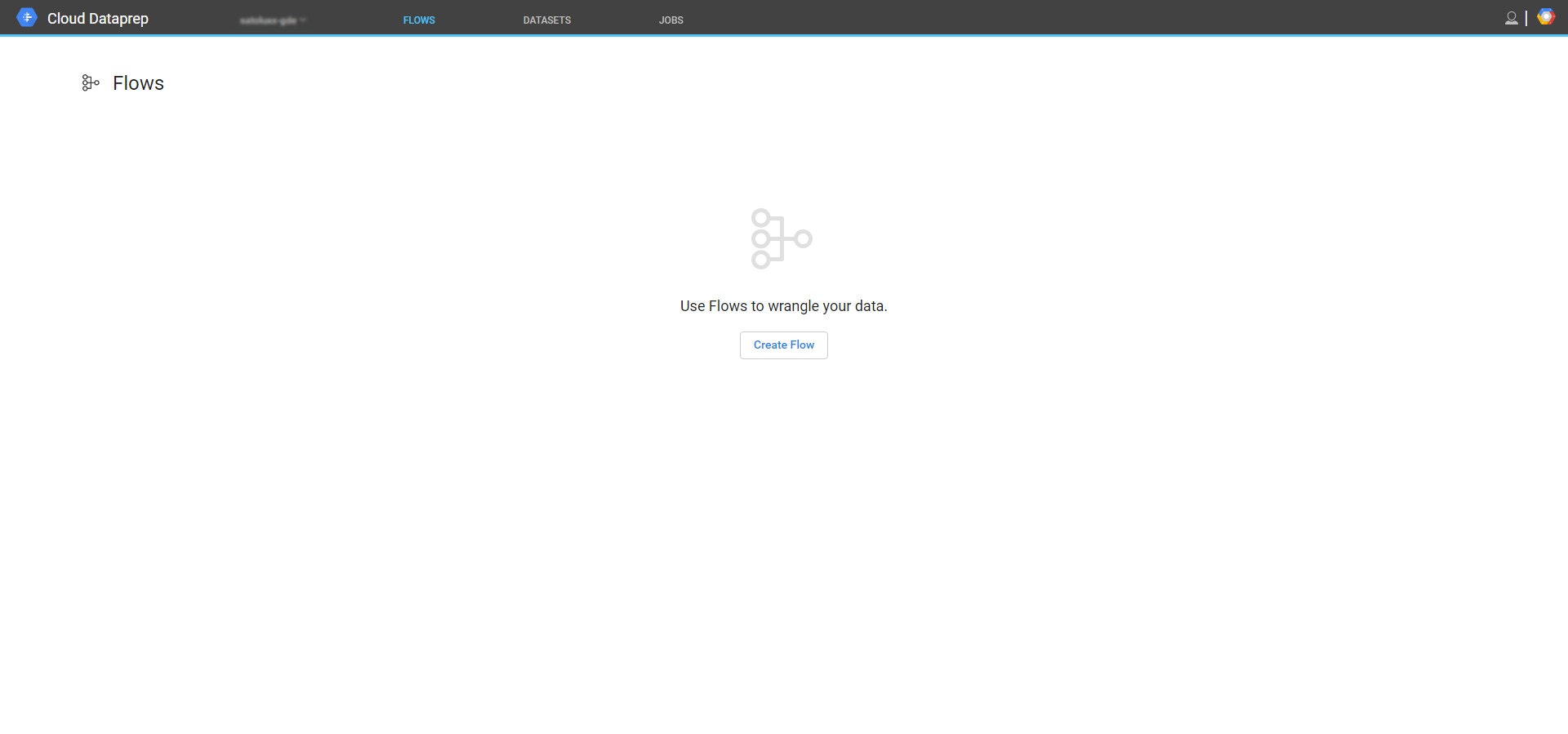
データソースを選択する
Datasets >> Import Dataと選ぶとデータソースを選択する画面が表示されます。
ここでファイルをアップロードしたり、CloudStorageやBigQueryのテーブルを選択します。用意したCSVファイルをアップロードしてみました。
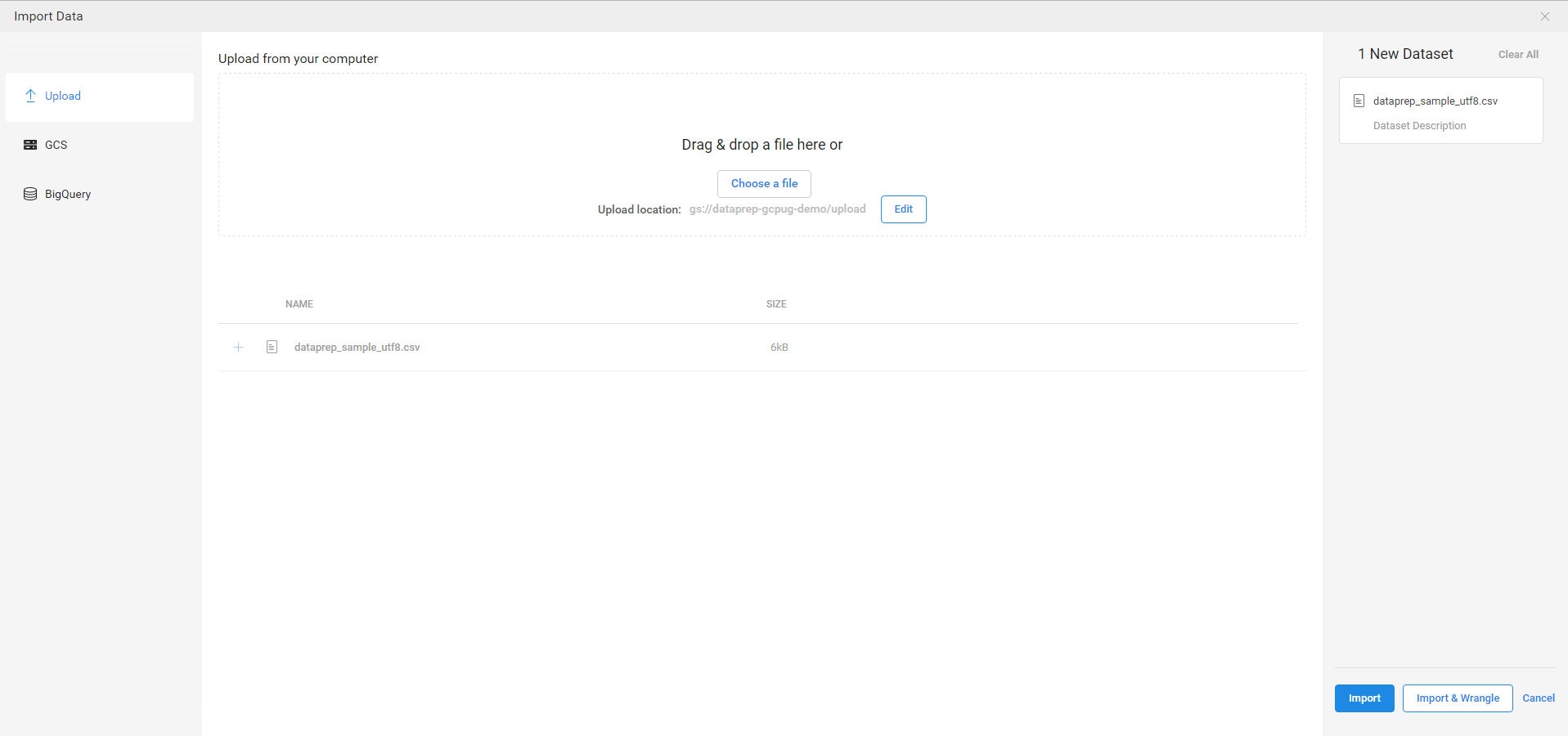
このまま右下の【Import & Wrangle】というボタンを押下して、データを処理する画面に進みます。
データを処理する画面
これがデータを処理する画面です。
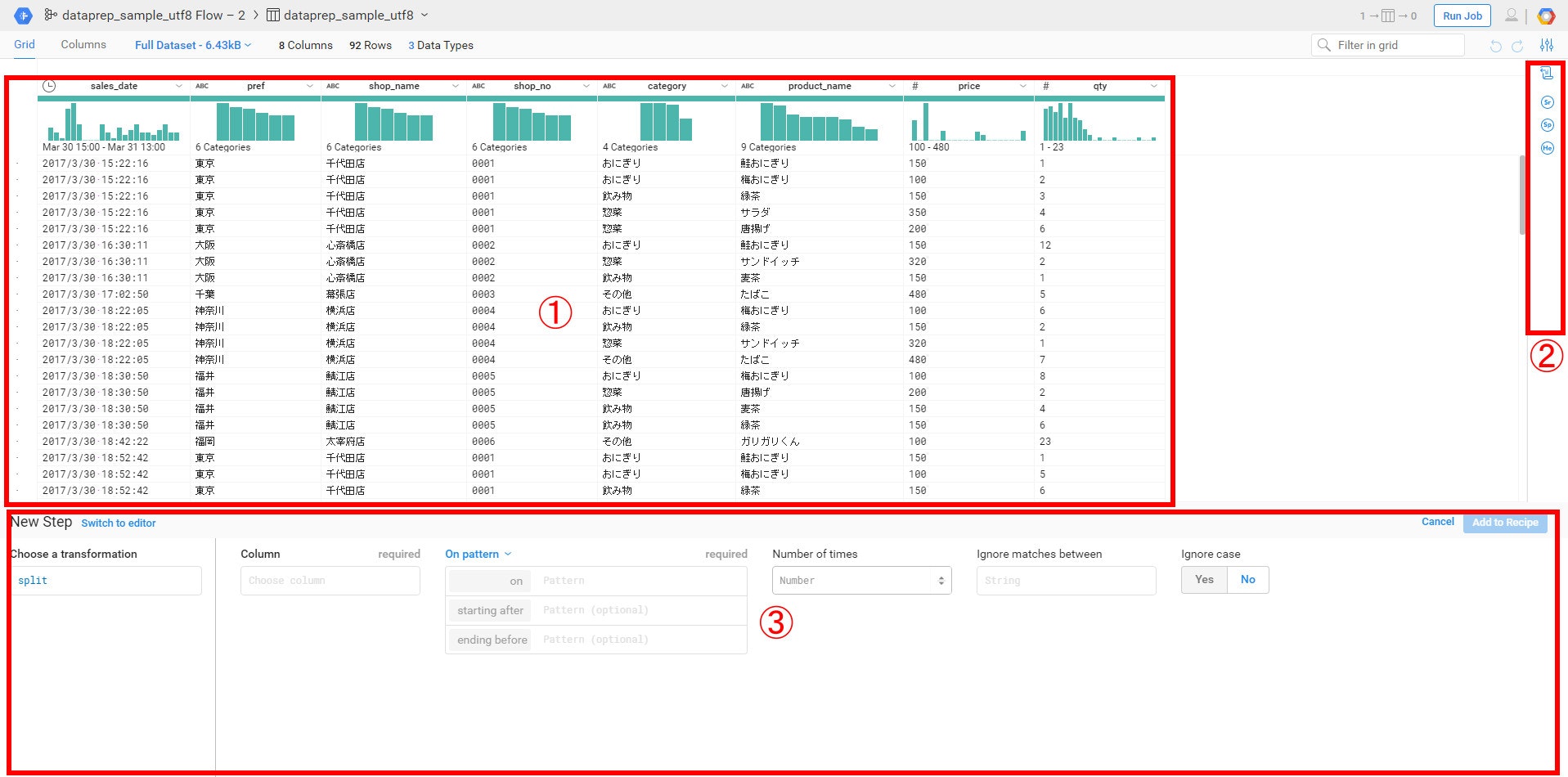
①はデータを処理した結果がプレビューされています。
②はデータの処理のフローが表示されています。取り込んだ時点ですでに3つの処理が施されています。
・改行コードで1レコードとして扱う
・カンマでデータを分割
・1行目をカラム名として利用
③は処理の方法を設定していきます。
データを処理してみる
では実際に処理していきましょう。
日付と時間を分けて、日付のスラッシュをハイフンに変換する
今回のデータではsales_dateのところに日時でデータを持っていますが、これを日付と時間に分けてみます。
またスラッシュをハイフンに変換してみます。一気にやってみましょう!

このように何かアクションを起こしたいところを選択すると、処理の方法を提案してくれます。やりたいことがそこになければ、Modifyを押下して自分で処理の方法を定義することも出来ます。
新しいカラムを作る
置換や分割だけでなく、カラムを追加することも出来ます。price(単価)とqty(個数)を掛け算した数値のカラムを作ってみましょう。

このように最初から自分で処理を定義することも可能です。
BigQueryにデータを入れる
データの処理は完了しました。では、これを実際に動かしてBigQueryにデータを入れてみましょう。
RunJobを押下することで、処理が始まります。

その後、Dataflowが処理をやってくれているのがわかります。
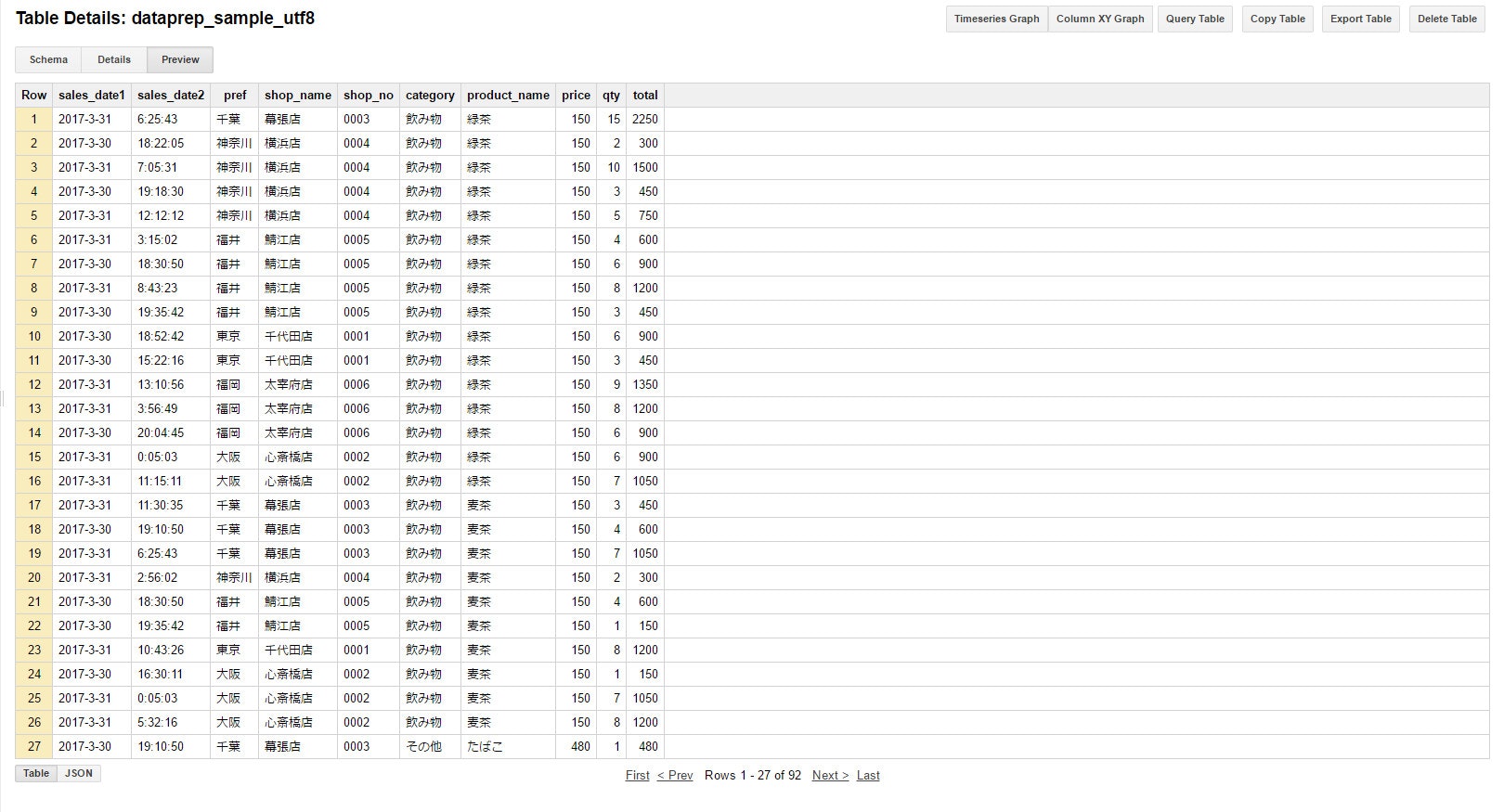
実際にBigQueryにはこのようにデータが入っています。
所感
いかがでしたか?
GUIで可視化しながら、簡単にデータを処理することが出来るようになっています。しかも、裏側はDataflowが利用されているということでインフラや分散処理など一切考える事なくよしなにやってくれます。Dataflowが出てきたときにはそれを使う側は処理のコードを書くことに集中できるということでしたが、コードすらも必要ありません。使い手側が自由にデータを入れたり出したり出来るようになりました。
今回はBigQueryにデータを入れるところをやりましたが、逆にBigQueryにすでにあるデータを加工して機械学習に持ってくるときに使ってみたり、CSVだけじゃなくJSONに変換してデータを入れてみたりなど色々と使い勝手は広がっていきそうです。
これが本当の『データの民主化』だなぁと感じました、でシメ。
追伸:PrivateBetaにも関わらず記事やデモすることを許可してくれたGoogleとAlexisに感謝します!