ふと気になったので、タグによってストック数の分布が変わったりするのか、少し調べてみました。
構想とデータの取得
特に難しいことはなく、
・タグのフォロワー数と投稿数を拾う
・タグのデータを1ページずつ開く
・ストック数、記事名、投稿時刻、投稿者をスクレイピング
・データフレームをマージし続ける
こんなことを考えました。
そして、以下のようなソースを少しずつ書き換えて動かすことで、各タグに対するストック数のデータを得たのでした。
library(rvest)
library(stringr)
df.all <- data.frame(stock=1,title="a",post_by="a",post_date="a")
df.all <- df.all[F,]
tag <- "関数型言語"
# R/43
# PHP/259
# Python/222
# Haskell/49
# 関数型言語/6
for(page in 1 : 6){
q <- html(sprintf("http://qiita.com/tags/%s/items?page=%s", tag, page))
# stock
data <- html_nodes(q, xpath = '//ul[@class="list-unstyled list-inline publicItem_statusList"]') %>%
iconv("utf-8", "cp932") %>%
str_replace_all("\\n","") %>%
str_replace_all("commentsCount.+","") %>%
str_replace_all("</li.+","") %>%
str_replace_all(".+>","") %>%
str_replace_all(".+publicItem_","")
data <- data.frame(stock=data)
# title
data$title <- html_nodes(q, xpath = '//div[@class="publicItem_body"]/h1') %>%
html_text() %>%
iconv("utf-8", "cp932")
# post_by
data$post_by <- html_nodes(q, xpath = '//div[@class="publicItem_status"]/a') %>%
html_text() %>%
iconv("utf-8", "cp932")
# post_date
data$post_date <- html_nodes(q, xpath = '//div[@class="publicItem_status"]') %>%
html_text() %>%
iconv("utf-8", "cp932") %>%
str_replace_all(".+が","") %>%
str_replace_all("に投稿.*","") %>%
str_replace_all(".+posted on ","")
df.all <- merge(df.all, data, all.x=T, all.y=T)
Sys.sleep(1)
}
本当に簡単にスクレイピングできるのが手軽で楽です。
可視化
などというほどたいそうな物でもないですが。。。
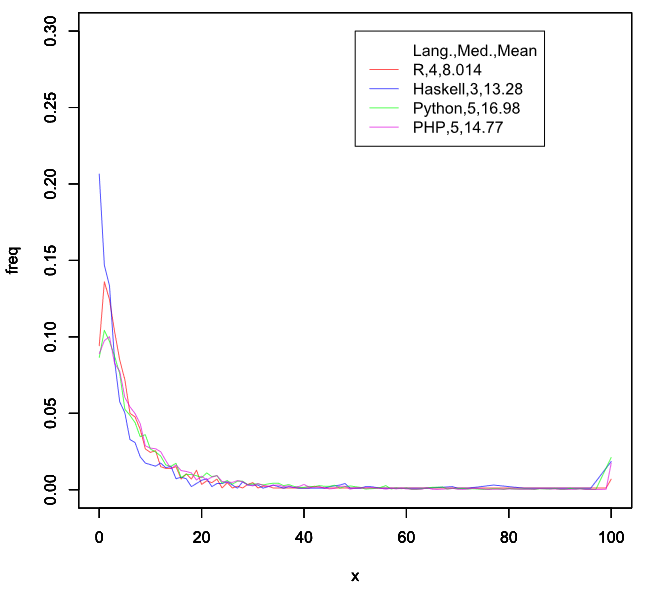
意外と同じぐらいなんですね。画像を作ったソースも貼ってみます。
ただし、dfの形を若干整えています。
library(plyr)
library(tidyr)
png("scrape.png")
intvl <- c(1:100,10000)
colsv <- c("#FF0000AA","#0000FFAA","#00FF00AA","#DD00DDAA")
cols <- list(R="#FF0000AA",Haskell="#0000FFAA",Python="#00FF00AA",PHP="#DD00DDAA")
mds <- list()
means <- list()
for(tag in c("R", "Haskell", "Python", "PHP")){
means[[tag]] <- summary(df[df$tags==tag, ]$stock)["Mean"]
mds[[tag]] <- summary(df[df$tags==tag, ]$stock)["Median"]
df.t <- findInterval(df[df$tags==tag, ]$stock, intvl) %>% count()
df.t$freq <- df.t$freq / sum(df.t$freq)
plot(df.t, col=cols[[tag]], ylim=c(0,0.3), type="l")
par(new=T)
}
legend(50,0.3,legend=paste(c("Lang.","R", "Haskell", "Python", "PHP"), c("Med.",mds), c("Mean",means), sep=","),
lwd = 1, col=c("white",colsv))
dev.off()
考察
Rは人口が少ないからストックされにくいのかと思ったのですが、そういうことでもないようです。ストック数を増やすためには、駄作を量産するのではなく、ちゃんと人が読んで意味のある記事を書け、ということですね。
Meanの値で見ると、Rはストック数が少ないようにも見えますが、これはマイナー言語だと大当たりする記事が少ないということなんでしょうね。
ただ、Rは検索したタグたちの中では唯一、フォロワー数よりも記事の数が多い言語でした。
タグにおける記事数とフォロワー数の比率は、ある種の指標になりそうでしたが、あまり色々言うと変なことになりそうなので、とりあえず気にしないことにします。
ちなみに、これ、グラフに載せていない「関数型言語」だと、かなりストック数が増えます。平均67ストックです。でも、ポエム含有率は意外と低かったです。たくさんのポエムが駆逐されてしまったんですね。(ポエム含有の定義は、タイトルにポエムという文言を含むか否か。。。)
もうちょっと考察
Qiita自体の自力、少なくとも検索にかかる度合はかなり高いと思いますが、それは直接はストック数にはつながらないように思われます。ストック数やビュー数を稼ごうとすると、twitter等のQiita外の媒体からの集客の効果が高いような気がします。
特にオチもなくおしまい。