この記事で伝えたいこと
ここでは、私が設計を勉強しながらコーディングした経験から、初心者でも簡単に実践できる簡単なルールを3つピックアップしました。
この3つを守れば、破滅的なクソコードであれば割と簡単に防げるかと思います。
この記事における「破滅的なクソコード」は「一切のリファクタリングの余地も残されていないほどのコード」を意味し、この記事の目的は、「破滅的なクソコード」から、「最低限リファクタリングすればなんとかなるコード」になる程度の手法を紹介することです。
マサカリは大歓迎ですがお手柔らかにお願いします。
読む上で留意して欲しいこと
この記事はあくまで 「初心者のための破滅的なクソコードを書かないための簡単な方法論」 であって、「効率的で分かりやすい設計の方法論」ではありません。
この3つは「銀の弾丸」ではないですし、「実践すれば必ずきれいなコードが書ける」という訳でもありません。
この点は最後にまた解説します。
対象読者
- 最近オブジェクト指向を完全に理解した。
- 自分のコードが汚いのはわかるけどどう直せばいいのかわからん。
- 綺麗なコードは書きたいけどどう書けばいいのかわからん。
- 絶賛1000行クラス記述中
この記事は主に 「個人開発をしていて、自分がスパゲッティを書いているのはわかるけど、どうやって直せばいいのか分からない」 という方を一番のターゲットにしています。
そのため、現場でバリバリコードを書かれている方からすると「いやそこは違うだろ」となる方もいるかもしれませんが、ご容赦ください。
前置きが長くなりました。
ここから本編です。
一つのクラスは150行以内に収める
簡単です。一つのクラス(ソースファイル)は150行以内に納めましょう。
オーバーしてはいけません。
1000行あるクラスと100行あるクラス、どちらが早く読めるかは火を見るより明らかでしょう。
また、1000行もあると 様々な関数や変数が相互作用し、処理を追うのがかなり面倒 になってしまいます
解決したい課題
- 1000行神クラスの発生
- そのクラスで何をやっているのかすぐにわからない
- 単一責任の原則を守れていない
課題の原因
SOLID原則の一つである 「単一責任の原則」 への理解や、責任の粒度が適切でないことが原因です。
クラスにおける責任と、単一責任の原則を理解し、適切な責任の粒度で分割すること重要となります。
まずは単一責任の原則をざっくり理解する
単一責任の原則の概要
クラスには単一責任の原則というルールがあります。
めっちゃざっくりいうと、 「そのクラスがやるべきことはひとつまで」 ということです。
いろんなことをするクラスを作ってはいけません。
単一責任をまもるとなにがいいか?
単一責任の原則を守ると、 そのクラスがやるべきことが明確になります。
クラスがやるべきことが明確になると、バグ修正や仕様追加の時、どこを変更してパッと分かるようになります。
1000行あるクラスで一つの関数を変更した時、知らない間に他の場所に影響してバグが発生する可能性があります。(私はこれで酷い目に遭いました)
ですが、150行程度の行数であれば、ある程度制御可能でどこを変更するとどう影響するのかわかりやすくなります。
150行にすると単一責任を守りやすくなる
単一責任の原則を守るためには、「そのクラスがやること」を適切に分割することが重要です。(この点は単一責任の粒度で詳細に解説しています。)
ですが、「適切」という単語は曖昧で、初心者の方にはどこまで分割すれば適切なのかわからないと思います。
そこで、150行以内という制約をつけます。
150行以内であれば、たくさんの責務を持つクラスは書きにくくなるでしょう。
もちろん、守ったからといって必ずしも単一責任の原則を守れるわけではありません。
ですが、ある程度処理が分割されたコードを書けるようになるでしょう。
初心者の方がそこまでできればとりあえずOKです。
絶対に150行以内でなければならない?
はい、これははっきりとNOです。
先ほども言った通り、150行以内だからと言って必ずしも単一責任ではないですし、150行以上でも単一責任が守られているコードがあるときがあります。
むしろ、絶対に守ろうと思って三項演算子を使いまくったりして読みづらくなっては意味がありません
例えば、上と下はどちらの方が読みやすいでしょうか?
private bool CheckMarriage(string userName,int age,bool isMale,bool isMarried)
{
return !isMarried && userName.Length < 20 && (18 <= age && isMale) || (16 <= age && !isMale);
}
private bool CheckMarriage(string userName,int age,bool isMale,bool isMarried)
{
if (isMarried)
{
return false;
}
if (20 <= userName.Length)
{
return false;
}
if (isMale)
{
return 18 <= age;
}
else
{
return 16 <= age;
}
}
ちなみにこのプログラムは、「結婚していなくて、ユーザー名が20字未満で、男の時は18歳以上、女の時は16歳以上の時にtrueを返す」プログラムです。
おそらく、下の方が読みやすいと思います。
そうです、行数が短いからといってプログラムが読みやすいわけではないのです。
150行以内にする目的は、責任を分割することであることを留意してください。
特にアルゴリズムを中心としたクラスは、むしろこのように冗長に書いたほうがわかりやすくなると思います。
読みやすさを優先して150行を超えることは大いにありです。
ですが、それでもやり過ぎには気をつけましょう。
個人的には長くても200行ぐらいまでで、それ以上になりそうだったら別のクラスに分けるなどした方が良いと思います。
単一責任の原則について詳細に理解する
さて、この章では単一責任の原則について詳細に解説していきます。
これを知らなくてもこの記事の目的は果たせますが、もし気になったら読んでみてください。
結構難解になると思いますので、わからないなーと思ったら単一責任の粒度まで飛んでください。
単一責任の原則とは?
単一責任の原則とは何でしょうか
それは、
(クラスを)「変更するための理由が、一つのクラスに対して二つ以上あってはならない」
(There should never be more than one reason for a class to change)
と言われています。
...いまいちよくわかりませんが、この文章は二つに分けて解釈することができるでしょう。
「変更するための理由」が、「一つのクラスに対して二つ以上あってはならない」
「一つのクラスに対して二つ以上あってはならない」のくだりは「単一」ということを表していそうです。
であるならば、「変更するための理由」が「責任」を表していると言えそうです。
変更するための理由 is 何
「変更するための理由」が「責任」を表していそうですが、それは一体なんなんでしょうか。
単純に考えれば、バグの修正や仕様の変更が「変更するための理由」と言えそうですが、あまりしっくり来ません。
だって、一回の仕様変更でそのクラスが変わるのは一回じゃん?
実は、単一責任の原則が守られていないとき、一回の仕様変更でそのクラスは二回以上変わる可能性があります。
そうなると、「変更するための理由が一つのクラスに対して二つ」になってしまい、単一責任の原則を守れなくなってしまいます。
次章ではその具体例を見ています。
変更するための理由が一つのクラスに対して二つあるパターン
ゲームの敵を考えてみます。
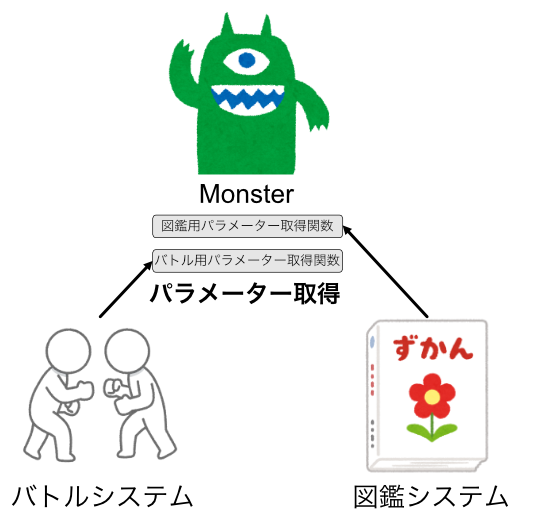
例えば、Monsterというクラスがあったとします。
このMonsterはバトルにも使われますが、図鑑からも閲覧することができます。
そのため、バトル用パラメーター取得関数と、図鑑用パラメーター取得関数があります。

また、「バトルシステム」と「図鑑システム」はこのMonsterに依存しています。
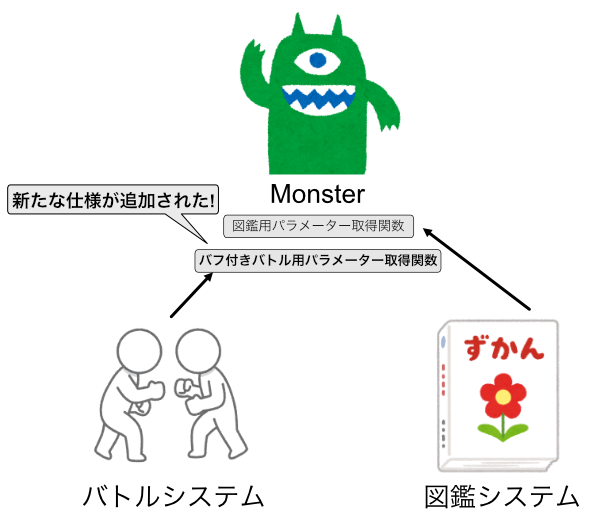
さて、このMonsterに、バトル中にバフ(強化されること)がかかる仕様変更が行われました。
バトル用パラメーター取得関数を変更して、バフの仕様を追加しましょう。
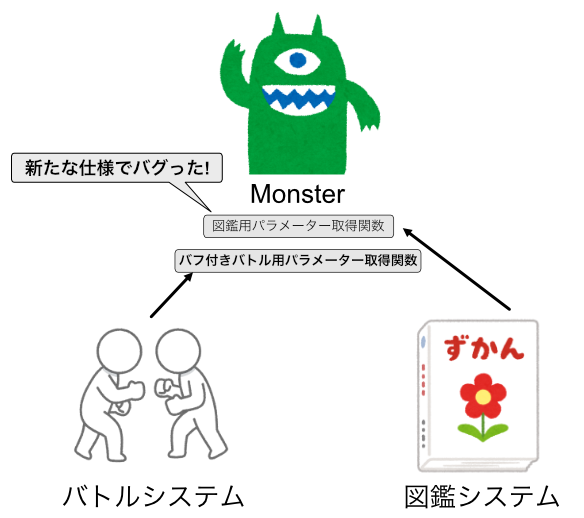
ですが、先ほどの仕様変更によって、図鑑用パラメーター取得関数にバグが発生していることがわかりました。
なんと、バフ付きの値が図鑑用パラメーターとして取得できるようになってしまいました!
となると、この図鑑用パラメーター取得関数も修正しないといけませんね。
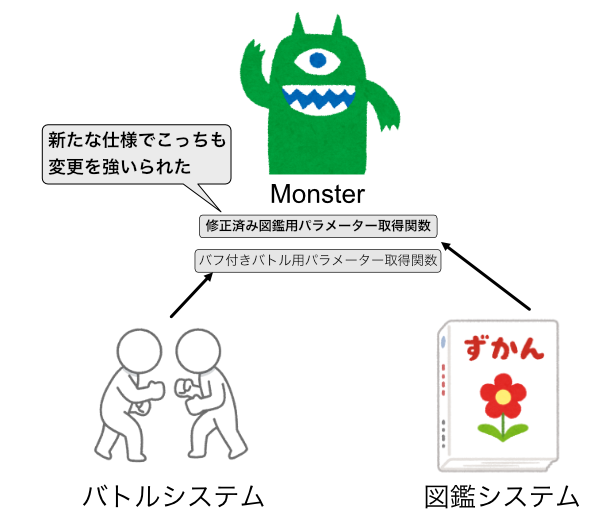
本来、バトル用パラメーター取得関数だけ修正すればいいと思っていましたが、図鑑用も修正しないといけなくなりました。
この場合、このクラスは、「バトル中にバフがつく仕様変更」と「仕様変更によるバグの修正」という2つの理由によって変更されてしまいました。
これでは単一責任の原則を守られていません。
もしこの図鑑用パラメーター取得関数と、バトル用パラメーター取得関数が別々のクラスで別れていれば、このようなことは起きなかったでしょう。
今回は仕様変更に対するバグは一つでしたが、もっと規模の大きいクラスになると、一つの仕様変更によって発生するバグは多くなる可能性があります。
「変更するための理由が一つでないといけない」のイメージがついたでしょうか?
「変更する理由が同じものは集める、変更する理由が違うものは分ける。」1
さて、先ほどの例で、変更する理由が二つあるとダメな事例を見ました。
ではどうやって先ほどのことを起こさないようにしたらいいでしょうか?
それは
「変更する理由が同じものは集める、変更する理由が違うものは分ける。」1
ということを意識します。
上記の例で言うと、バトルシステムはバトルシステム同士の処理を集めるべきで、図鑑システムは図鑑システム同士の処理で集めるべきで、それぞれをごっちゃにしてはいけないということです。
これらのバトルシステムや図鑑システムなどの適切な処理の集まりを、それぞれのクラス同士でさらに「変更する理由」が一つになるように分割すればいいわけですね。
これができれば「単一責任の原則」を満たしているといえるのではないでしょうか。
ですが、これを守るためには経験が必要だと思います。
もしこの章があまりよくわからなかったのであれば、「とりあえず150行にしておけばいいんだなー」と思っておいてください。
単一責任の粒度
クラスについての責任と、単一責任の原則はわかりました。
しかし、どの粒度で単一責任といえば良いのでしょうか?
プレイヤーの管理は単一責任?
ゲームのプレイヤーを考えてみましょう。
プレイヤーの処理をにまとめ、「変更する理由」が一つになるように分割していきます。

- 「プレイヤーを正しく管理する」
なんとなく単一責任っぽい感じをします。だって、「プレイヤーのバグ修正」や「プレイヤーへの仕様変更」が入ればここを変更すればいいわけですから。
ですが、実はこの責任は大きすぎます。
「管理」とは具体的に何をする?
「プレイヤーの管理」は大雑把すぎます。
もっと具体的に処理を見ると以下の要素があり、単一責任とはいえません。
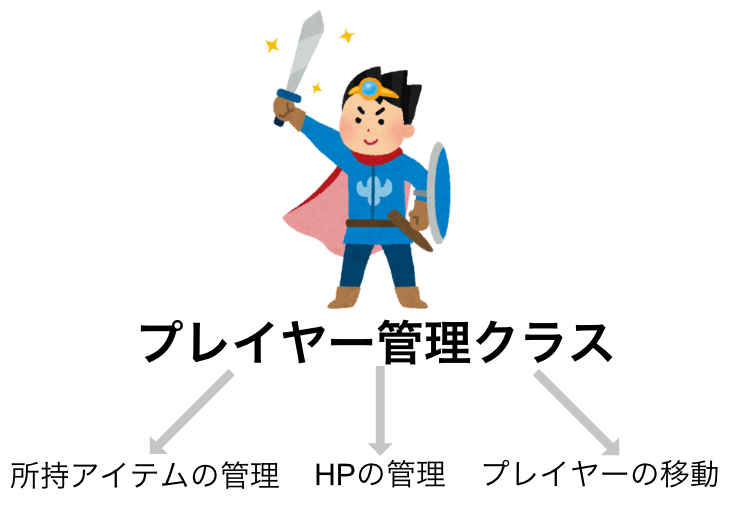
- 「プレイヤーのHPを管理する」
- 「プレイヤーの所持アイテムを管理する」
- 「プレイヤーの移動」
なんと!「プレイヤーを管理する」クラスは単一の責任ではありませんでした。
もし、「プレイヤーの移動速度変更」と「プレイヤーの最大HP変更」という2つの仕様変更があったとき、一つの「プレイヤーを管理する」クラスは別々の理由で変更が入ります。
これは明らかに、「変更するための理由が、一つのクラスに対して二つ以上あってはならない」に反しています。
責任は3つに分かれ、それぞれ単一責任を負っているように見えます。
「プレイヤーの移動速度変更」と「プレイヤーの最大HP変更」の仕様変更は、それぞれ「プレイヤーの移動」と「プレイヤーのHPを管理」を変更すれば良いので、一つのクラスに対して一つの変更になっています。
ですが、これら3つは本当にそれぞれ単一責任でしょうか?
管理する要素をもっと具体的に見る
この中からさらに「プレイヤーの移動」クラスの中をみてみましょう。

- 「ユーザーからの入力を受け取る」
- 「入力値に応じてプレイヤーの座標を変える」
- 「座標に応じて画面にプレイヤーを表示する」
どうやら「プレイヤーを移動させる」も単一責任ではなさそうです。
例えば 「プレイヤーの移動」クラスに対して、「走りたければシフトキーを押す」と「走っている間はそのモーションを表示する」という仕様変更が入れば、一つのクラスに対して二つの変更になってしまいます。
この3つに分割されれば、2つの仕様変更はそれぞれのクラスに対応しているので、一つのクラスに対して一つの変更になっています。
ですが、これは本当に....
とやっていたら、最終的に1行ずつに分割されていきそうです。
1クラスに1行しかないのは流石におかしいですね。
適切な責任の大きさが重要
つまり、単一責任の原則を守るためには、大きすぎず、小さすぎず、適切な大きさの責任を負わなければならないということになります。
この 「適切な責任の大きさ」 を手っ取り早く達成するために、1クラス150行以内という制約を設けます。 ※諸説あります。50行という人もいれば、100行という人もいます。
繰り返しますが、150行以内だからといって必ずしも単一責任の原則が守られているわけじゃないし、150行以上なら守られていないわけでもありません。 しかし、この程度の行数であれば、それなりに適切な責任の粒度にはなっているかと思います。
150行以内ならまぁ〜そんなにたくさん責任を持つクラスは書けんやろ。というイメージです。
このルールを守りつつ、皆さんのプログラムにおける適切な責任の粒度を見出して見てください。(もちろん「プレイヤーを管理する」を一つの責任と言うのはダメですよ)
循環参照はしない
循環参照とは、それぞれお互いのクラスが参照しあっているという状態です。
この状態は非常に良くありません。
解決したい課題
- 循環参照によって処理が追いづらくなる
- 再利用性が失われ、拡張性が失われる
- 特別な仕様に対応しづらくなる
課題の原因
循環参照は楽に仕様を実現できるため、初心者はやりがちな実装方法ではないでしょうか。
ですが、循環参照を許してしまうとその箇所が非常に追いづらくなります。
なぜなら、処理があっち行ったりこっち行ったり、どこで何がどう処理されているのかわからず、全体を把握することが困難になります。
まるで絡まった紐を追うかのような面倒臭さを発生させてしまいます。
また、循環参照をすると特別な仕様に対してif文で分岐させるなど、非常に泥臭いコードを書かざるを得なくなってしまいます。
循環参照をしないことは、全体の処理の追いやすさにおいて重要な要素であると言えます。
循環参照とは
まずはダメな例から見てみましょう。
よくある循環参照だと、プレイヤーとプレイヤーマネージャーの関係性が挙げられるのではないでしょうか。
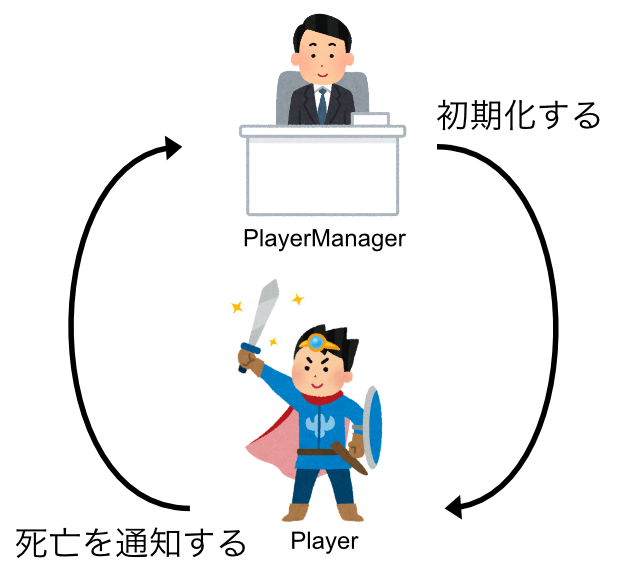
コードで書くと以下のようになります。
public class PlayerManager
{
private Player player;
public void SpawnPlayer()
{
//プレイヤーに依存している
player.Init();
}
public void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
}
}
public class Player
{
private PlayerManager playerManager;
public void Init()
{
//初期化処理
}
public void Death()
{
//プレイヤーマネージャーに依存している
playerManager.OnPlayerDeath();
}
}
上記の例だと、PlayerManagerはプレイヤーの初期化処理をするためにPlayerに依存しています。
PlayerはPlayerManagerに死んだことを伝えるためにPlayerManagerに依存しています。
これが循環参照である状態です。
循環参照がダメな理由
循環参照はなぜよくないのでしょうか?
それは、クラス同士の依存性が極端に増し、クラスを分ける意味がなくなるからです。
クラスを分ける意味
クラスを分ける意味とはなんでしょうか?
それは、クラスを再利用できるようにするということです。
循環参照ではクラスの再利用が難しい
もし上記のPlayerを別の場所で使いたいと思った時、PlayerManagerもセットで使う必要があります。
例えば、仕様変更で通常ステージとは別に、ボーナスステージを作る必要が出てきました。
今回の仕様変更では、本当はこのボーナスステージはPlayerManagerの処理は必要ありませんでした。
しかし、PlayerはPlayerManagerに依存しているため、セットでないとボーナスステージを作れません。
仕様としては使う必要のないクラスを、循環参照によって使う羽目になってしまいました。
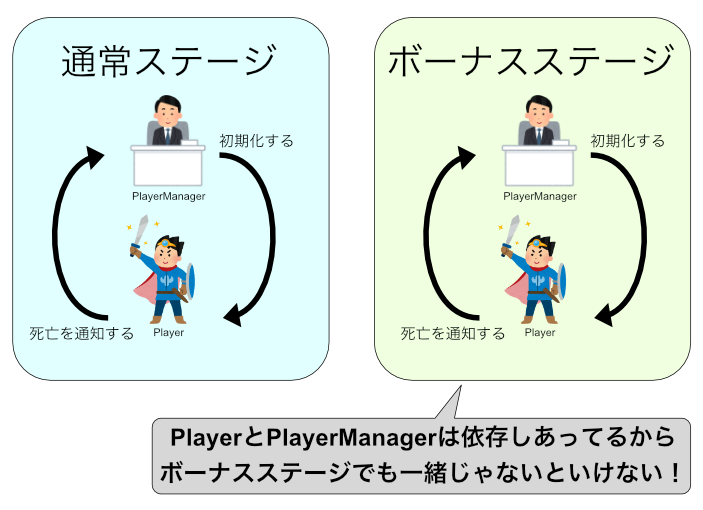
この状態は非常によくないです。クラスが2つ一緒に出ないといけない都合上、どこで使うにも2つセットである必要があります。
2つの循環参照ならまだいい方で、これが3つ4つ、もしくはプロジェクト全体に及ぶともうどうにもなりません。
これなら1000行クラスの方が、1つのクラスなのでまだマシまであります。(もちろん循環参照があれば同じです)
循環参照では拡張性がなくなる
再利用が難しくなると言うことは、容易に拡張ができないことを意味します。
循環参照では拡張が困難になる例を見てみます。
PlayerManagerの他に、ボーナスステージの特殊ルールを実装したSpecialPlayerManagerを組み込みたくなりました。
循環参照のままでは以下のような実装になるでしょう。
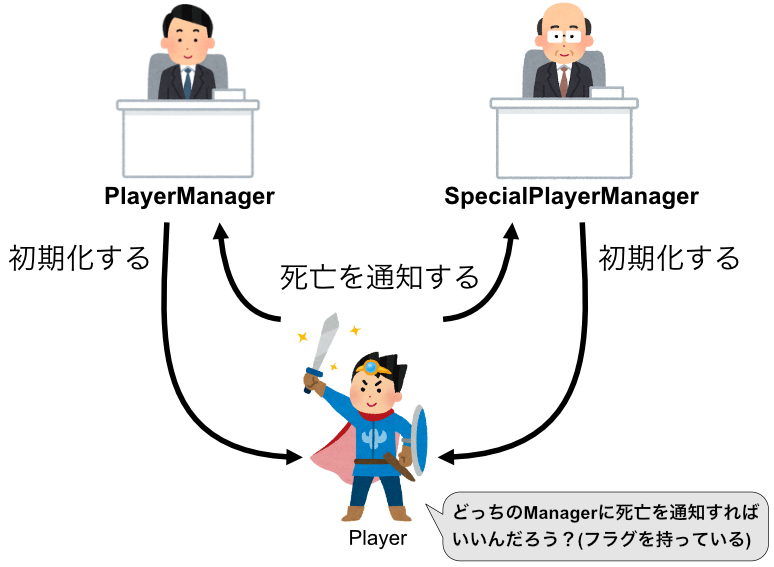
コードで書くと以下のようになります。
public class PlayerManager
{
private Player player;
public void SpawnPlayer()
{
//プレイヤーに依存している
player.Init();
}
public void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
}
}
public class SpecialPlayerManager
{
private Player player;
public void SpawnPlayer()
{
//プレイヤーに依存している
player.Init();
}
public void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
//特殊ルールなので通常とは違う処理をする
}
}
public class Player
{
private PlayerManager playerManager;
private SpecialPlayerManager specialPlayerManager;
private bool isSpecial;
public void Init()
{
//初期化処理
}
public void Death()
{
//通常と特殊ルールの両方に依存している
if (isSpecial)
{
specialPlayerManager.OnPlayerDeath();
}
else
{
playerManager.OnPlayerDeath();
}
}
}
PlayerはPlayerManagerとSpecialPlayerManagerに依存している上に、isSpecialというフラグまで追加されてしまいました。非常にクソコードの匂いがします。
さらにここに別の特殊ルールのPlayerManagerができたらどうなるでしょうか、想像に難くありませんが、想像したくないでしょう。
このように、循環参照をするとどちらかの変更に対してもう一方も変更を強いられたり、クラスの再利用ができなくなってしまいます。
循環参照をしないために
循環参照をしないためには 「クラスの上下関係」 と 「下は上に依存しない」 ことを意識する必要があります。
この例で言うと、PlayerManagerはPlayerよりも上位の存在となります。
そのため、PlayerManagerはPlayerに依存して良いですが、PlayerはPlayerManagerやSpecialPlayerManagerに依存してはいけません。
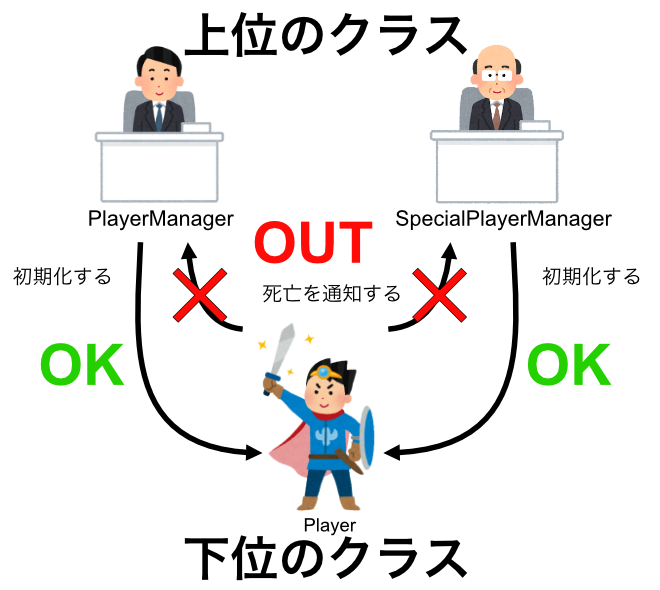
下位のメッセージから通知を送りたい
とはいえ、下位のクラスが何かを起こした時、それを上位のクラスに教える必要は出てきます。
そのような時は、コールバック関数という仕組みを使います。
コールバック関数はざっくりいうと関数を変数として扱い、別の場所で関数を実行できるようにする仕組みです。
いまいちよくわからないかと思いますが...詳細は別の解説にまかせて、これを使って最初の例の循環参照を回避した例をみてみましょう。
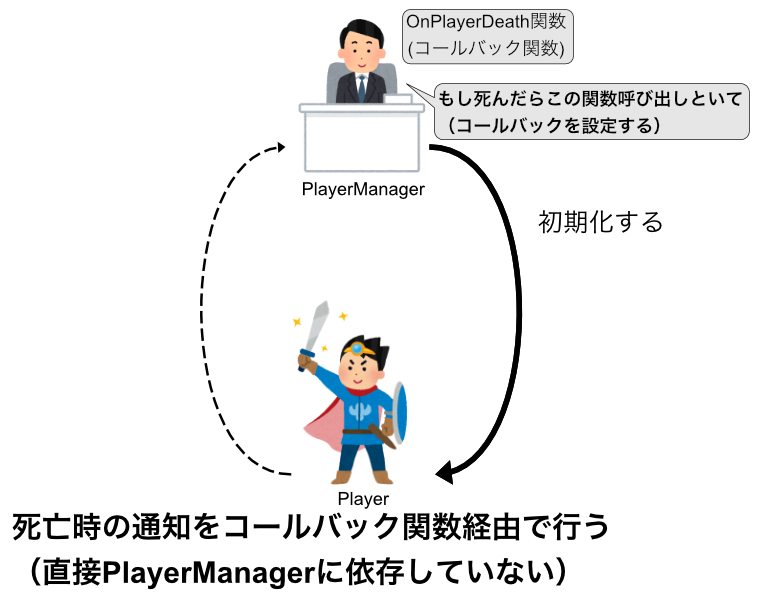
public class PlayerManager
{
private Player player;
public void SpawnPlayer()
{
//Initの引数として自分の関数を登録する
player.Init(OnPlayerDeath);
}
//直接呼び出される訳ではなく、コールバックによって呼び出されるため、privateでも問題ない
private void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
}
}
public class Player
{
//C#はdelegateという機能でコールバック関数の定義をします。
//詳細は未確認飛行Cなどで確認してください...
public delegate void PlayerDeath();
private PlayerDeath PlayerDeathCallBack;
public void Init(PlayerDeath onPlayerDeath)
{
//コールバック関数を設定
PlayerDeathCallBack = onPlayerDeath;
}
public void Death()
{
// C#の場合はdelegate変数直後に丸括弧をつけることで、設定された処理を実行できます
PlayerDeathCallBack();
}
}
これでPlayerはPlayerManagerに依存しなくなり、循環参照を回避できました。
Playerの再利用性や拡張性が高まりました。
では、Playerを再利用してSpecialPlayerManagerを作ってみましょう!
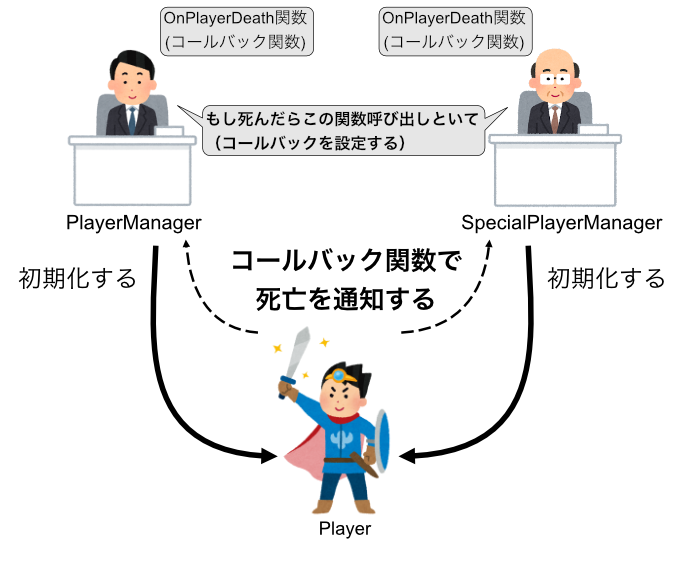
public class PlayerManager
{
private Player player;
public void SpawnPlayer()
{
//Initの引数として自分の関数を登録する
player.Init(OnPlayerDeath);
}
//直接呼び出される訳ではなく、コールバックによって呼び出されるため、privateでも問題ない
private void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
}
}
public class SpecialPlayerManager
{
private Player player;
public void SpawnPlayer()
{
player.Init(OnPlayerDeath);
}
private void OnPlayerDeath()
{
//プレイヤーが死んだ時の処理
//特殊ルールなので通常とは違う処理をする
}
}
public class Player
{
//PlayerはPlayerManagerたちに依存していないので、コードを変える必要はない
public delegate void PlayerDeath();
private PlayerDeath PlayerDeathCallBack;
public void Init(PlayerDeath onPlayerDeath)
{
//Playerはコールバック関数がPlayerManagerから設定されたのか、SpecialPlayerManagerから設定されたのか知らない
PlayerDeathCallBack = onPlayerDeath;
}
public void Death()
{
//そのため、知らぬ間にどちらかのOnPlayerDeathを実行することになる
PlayerDeathCallBack();
}
}
やりました!Playerクラスを変更することなくSpecialPlayerManagerを追加することができました。
これならどんなに特殊ルールが増えても、Playerに新しいフラグを作る必要がありません。
これが、クラスの再利用です。
循環参照の回避は、クラス同士の複雑度や依存性を低減させ、再利用性を高めることができます。
ちなみに、C#の場合はコールバックと似たような機能でeventという仕組みあります。
気になる方は調べてみてください。
継承はしない
継承は最初このように教えられるかと思います。
「継承を使うことで共通部分をまとめ、効率的にコーディングすることができる」と
これは嘘ではありません。
短期的に見れば効率的にコーディングできるでしょう。
しかし、長期的に見ると多大な技術的負債を生み出していしまいます。
解決したい課題
- 継承をすると親クラスに処理が集中する
- 子クラス用の処理やバグ回避処理が親クラスにでき親クラスの複雑度が増す
課題の原因
継承は強力な機能でありながら、適切に使える人は少ないのではないかと思います。
それは、継承は「処理を共通化して効率的にしよう」という考えのもと使っているからだと思います。
継承を使うためには適切なクラス設計の時のみ(is-a関係やリスコフ置換原則が守られているなど)使うことができますが、そのように継承を使える人は多くはありません。(私もその一人です)
であれば、いっそ禁止してしまった方が良いでしょう。継承をしなくてもある程度継承と同じようなことはできます。
継承はなぜダメ?
継承がなぜダメなのか、ビジュアル的にわかりやすい動画を貼っておきます。ぜひこちらもみてみてください。
継承を使うことには複数の問題がありますが、ここではメソッドをまとめた親クラスの神化について見てみます。
親クラスの神化
前回ではプレイヤーについて考えたので、今回は敵の実装について考えて見ましょう。
まずは継承を使って敵を実装してみます。
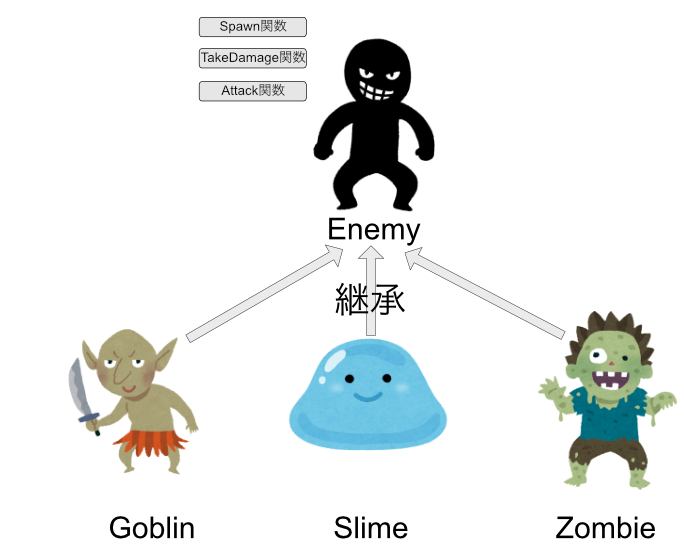
まず基本となるEnemyクラスを作ります。
敵はSpawn、TakeDamage、Attackの処理を持っています。
public class Enemy
{
public void Spawn()
{
//スポーン時の処理
}
public void TakeDamage(int damage)
{
//ダメージを食らった時の処理
}
public void Attack(Player target)
{
//攻撃時の処理
}
}
では、このEnemyクラスを継承してZombie、Goblin、Slimeクラスを作成します。
public class Zombie : Enemy
{
}
public class Goblin : Enemy
{
}
public class Slime : Enemy
{
}
よさそうですね。
効率的に敵をコーディングできました。
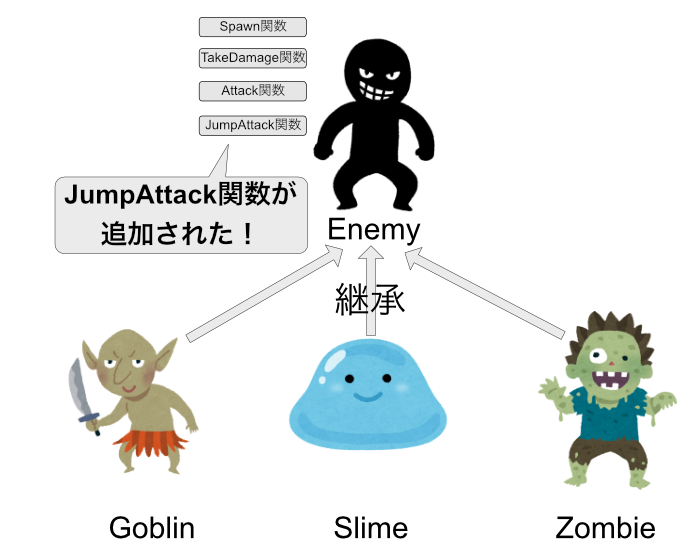
ここで、ゴブリンとスライムはジャンプ攻撃をするという仕様変更が加わりました。
二つの敵はジャンプ攻撃を仕掛けるそうです。この処理は共通しているので、Enemyに加えましょう。
public class Enemy
{
public void Spawn()
{
//スポーン時の処理
}
public void TakeDamage(int damage)
{
//ダメージを食らった時の処理
}
public void Attack(Player target)
{
//攻撃時の処理
}
public void JumpAttack(Player target)
{
//新しいジャンプ時の攻撃時の処理
}
}
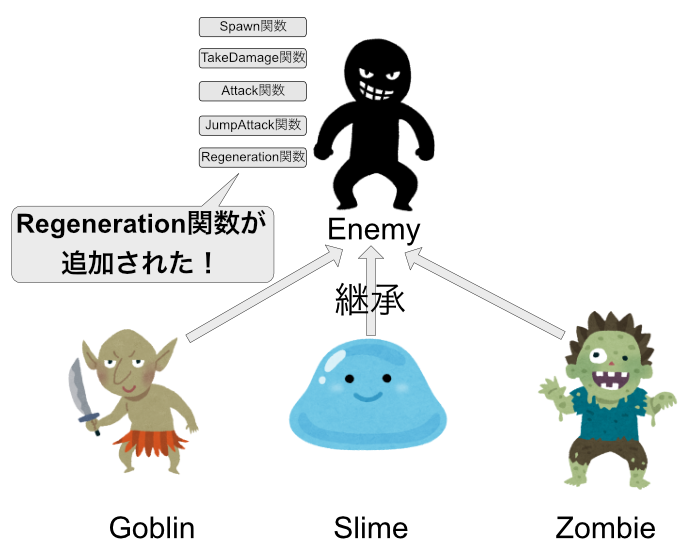
さらに別の仕様変更が加わりました。
ゴブリンとゾンビは自分で回復ができるそうです。
この処理も共通しているので、Enemyに加えましょう。
public class Enemy
{
public void Spawn()
{
//スポーン時の処理
}
public void TakeDamage(int damage)
{
//ダメージを食らった時の処理
}
public void Attack(Player target)
{
//攻撃時の処理
}
public void JumpAttack(Player target)
{
//新しいジャンプ時の攻撃時の処理
}
public void Regeneration(int health)
{
//回復時の処理
}
}
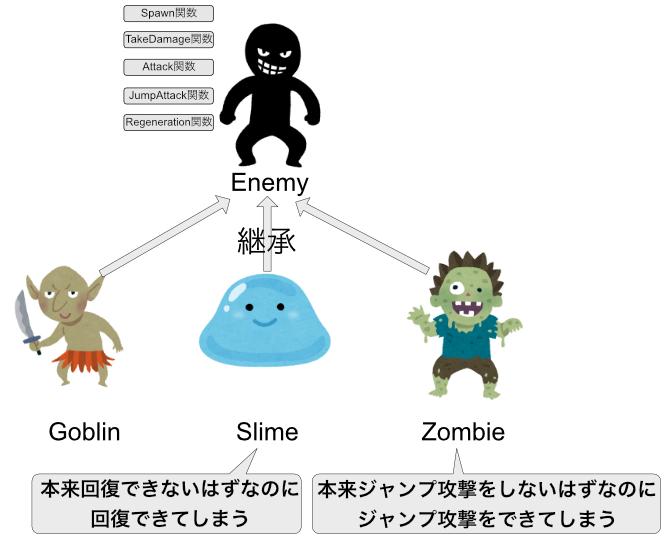
さて、次の仕様変更は....
このように、親クラスにはどんどん処理が追加され、Enemyが肥大化してします。
また、この状態だと、ジャンプ攻撃をしないはずのゾンビでもジャンプ攻撃をできてしまいますし、回復をしないはずのスライムでも回復ができてしまいます。
これらの不具合を解決する処理もEnemyに加えないといけなくなりますね。
2つの要素を掛け合わせたような処理を記述できない
継承を使ってコーディングをすると、二つの要素を掛け合わせたようなクラスを実装できなくなるという問題があります。
その例を見てみましょう。
まず、味方を処理するクラスを作ります。
この味方はプレイヤーについていく性質があります。

public class Allies
{
public void Spawn()
{
//スポーン時の処理
}
public void TakeDamage(int damage)
{
//ダメージを食らった時の処理
}
public void Attack(Enemy target)
{
//攻撃時の処理
}
public void Follow(Player target)
{
//プレイヤーについていく処理
}
}
ここで、普段は味方だけど、攻撃されたら敵になる中立的なキャラクターを作るという仕様が追加されました。
なので、以下のよう実装したくなります。
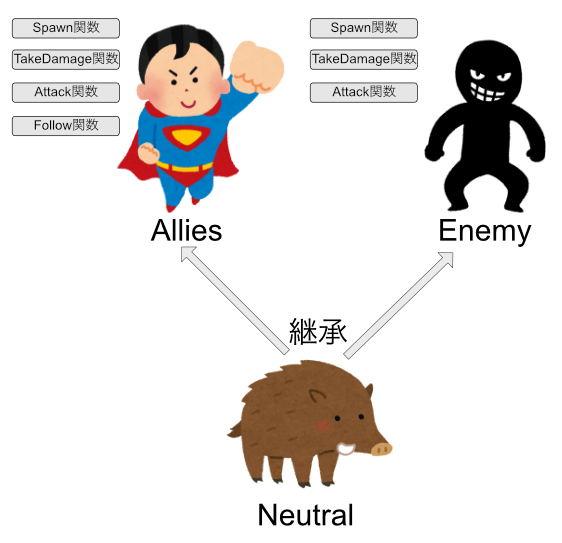
public class Neutral : Enemy,Allies
{
}
しかし、C#の場合はコンパイルエラーとなり、このように実装することはできません。
複数のクラスを継承することを多重継承と呼び、言語によっては禁止されています。
※詳しくはこちらを参照
継承を使わない方法
このように、継承には複数の問題があり、あまり気軽に使って良いものではありません。
継承を回避するには、Interfaceと委譲という、2つの手法を使います。
Interfaceの使い方
Interfaceは関数だけを定義し、実装はInterfaceを継承(正確には実装と言う)したクラスに任せるという機能です。
先ほどのEnemyをInterfaceにして見ましょう。
public interface IEnemy
{
public void Spawn();
public void TakeDamage(int damage);
public void Attack(Player target);
}
このように、「どの関数を使えるか」だけを定義し、実際にどのようなことをするかは書きません。
では、Interfaceを継承してみましょう。
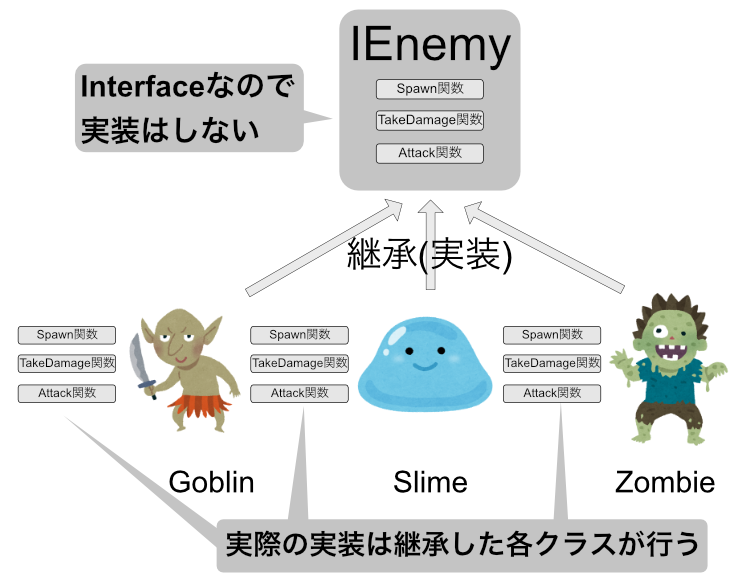
public class Goblin : IEnemy
{
public void Spawn()
{
//実際の処理を書く
}
public void TakeDamage(int damage)
{
//実際の処理を書く
}
public void Attack(Player target)
{
//実際の処理を書く
}
}
GoblinはInterfaceを継承したことによって、実際の処理を実装する必要があります。
これにより、継承のようなポリモーフィズムを維持することができました。
同じように、SlimeやZombieも作成しましょう。
以下のようになります
public class Slime : IEnemy
{
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
public class Zombie : IEnemy
{
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
そして、先ほどと同じように、スライムとゴブリンはジャンプ攻撃を仕掛けるという仕様変更について取り掛かりたいと思います。
ここで、IEnemyにJumpAttackを追加してはいけません。(Interface分離の原則)先ほどの継承と同じような問題が発生してしまいます。
なので、新しいInterfaceを定義します。
public interface IJumpAttackEnemy
{
public void JumpAttack(Player target);
}
そして、これをスライムとゴブリンに継承させます。
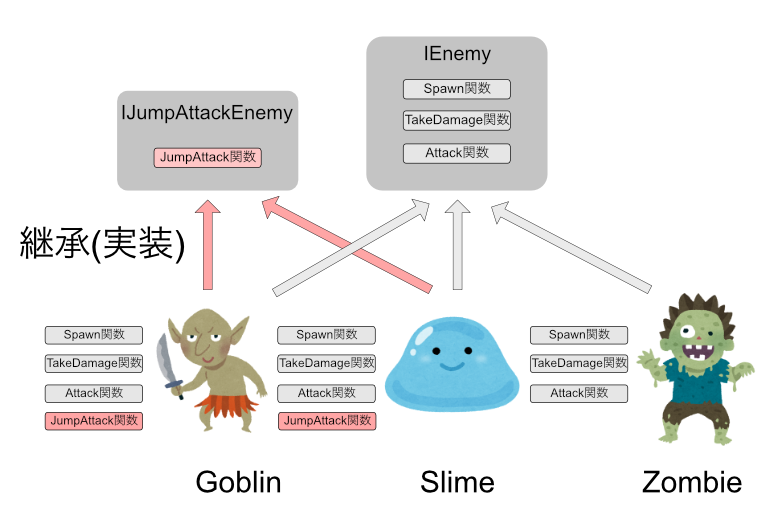
public class Slime : IEnemy,IJumpAttackEnemy
{
public void JumpAttack(Player target)
{
//ジャンプ攻撃の処理
}
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
public class Goblin: IEnemy,IJumpAttackEnemy
{
public void JumpAttack(Player target)
{
//ジャンプ攻撃の処理
}
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
これで、ゴブリンとスライムにはジャンプ攻撃を実装できますが、ゾンビにジャンプ攻撃ができてしまう不具合は無くなります。
このように、別の処理は別のInterfaceを定義することで、不必要な関数の実装を防ぐことができます。
Intefaceはいくつでも継承できるというルールがあるためこのような実装が可能となります。
継承で同じことをしようとすると多重継承となり、言語によってできない可能性があります。
委譲のやり方
委譲は、他のクラスに処理を任せると言うことです。(正確には転送と言います)
ジャンプ攻撃を他のクラスに委譲してみますが、その前に、通常のジャンプ攻撃を見て見ましょう。
public class Slime : IEnemy,IJumpAttackEnemy
{
public void JumpAttack(Player target)
{
//プレイヤーにダメージを与える
target.TakeDamage(damage);
//ジャンプ攻撃のアニメーションを再生
slimeAnimation.PlayJumpAttack();
//エフェクトとか音とかその他いろんな処理....
}
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
ごちゃごちゃしていますね。
それをSlimeクラスに書いておくのは気が引けます。
それでは、委譲先のクラスを作成しましょう。
public class JumpAttackImplementation
{
public void Attack(Player target, Animation enemyAnimation ...その他いろんな引数)
{
//プレイヤーにダメージを与える
target.TakeDamage(damage);
//ジャンプ攻撃のアニメーションを再生
enemyAnimation.PlayJumpAttack();
//エフェクトとか音とかその他いろんな処理....
}
}
このJumpAttackImplementationは、ターゲットにダメージを与え、アニメーションを再生し、音を鳴らします。
その情報は引数で渡します。
では、このクラスをSlimeやGoblineで使うようにしましょう。
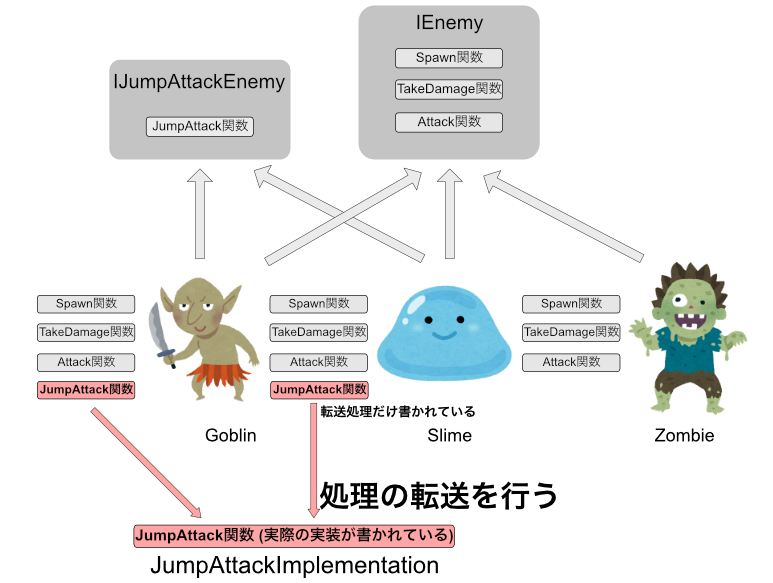
public class Slime : IEnemy,IJumpAttackEnemy
{
private JumpAttackImplementation jumpAttack;
public void JumpAttack(Player target)
{
//JumpAttackImplementationに実装
jumpAttack.Attack(target,slimeAnimation,その他の引数);
}
//省略 実際はSpawn,TakeDamage,Attackが記述されている
}
ごちゃごちゃしていたJumpAttackがスッキリしました。
また、Goblinクラス同様に書くことで、継承をせずに処理を共通化できました。
継承しても大丈夫なもの
ここでは継承の禁止を主張し、その根拠として継承のデメリットを説明しました。
ですが、例外として継承してもいいものがあります。
それはライブラリやフレームワークで必要な継承です。
私がよく使っているゲームエンジンのUnityでは、Unityの世界でC#を実行するために「MonoBehaviour」というクラスを継承しなければなりません。
using UnityEngine;
//Unityユーザーなら親のScriptより見たScript
public class HogeHoge : MonoBehaviour
{
private void Start()
{
}
private void Update()
{
}
}
ライブラリやフレームワークで求められている継承は、基本的に自分が触ることがないため、上記のようなデメリットはほとんど発生しません。
そのため、この継承については問題ありません。
最後に
ここまで読んでくださった方、本当にありがとうございます。
この記事では、私がコーディングをする上で意識している3つを紹介しました。
この章では、この3つを使う上で意識してほしいことと、私がこの記事を書いた理由について説明していきます。
「意識したい」ということを意識する
そもそも、この記事に書いてあることを絶対に守るべきかと言えば、そんなことはありません。
例えば、150行以内でも単一責任の原則を破ったコードは書けますし、単一責任の原則を守っても150行以上になることもあります。
そうです。コードの行数は本質ではありません。
循環参照の場合も、コールバック関数は使わずに、循環参照したほうが直感的に書けるケースはあります。
適宜皆さんの判断で、守ったり破ったりしてくれて構いません。
設計手法として有名なクリーンアーキテクチャやドメイン駆動設計ですら、むしろ使わない方が直感的になる場面もあるでしょう。
あくまでここで紹介したことは「意識したいこと」であって、これをこのままチームのコーディングルールとして適応したり、常に守り続けることはむしろよくないことだと思います。
これらは 「意識したいこと」であることを意識していただける と幸いです。
なぜこの記事を書いたのか
であれば、なぜこれら手法を紹介したのでしょうか?
それは、この記事の理念は、 「初心者でも簡単に実践できる、将来新しいことを学んだ時のために、リファクタリングの余地を残しておけるルールを紹介する」 ことだからです。
「適切な名前をつけよう」や「一つのクラスの責任は一つまで」などのアドバイスはよく見かけます。
ですが、それらは曖昧で、どこまで適切でどこからがアウトか初心者は一概にはわからないですし、よく議論される対象でもあります。
もちろん、それらは悪いことではなく、むしろそうあって然るべきだと思います。
ですが、だからと言ってそれをそのままにしておくのは良くありません。
これは知り合いの話 なのですが、「単一責任の原則なんだから、プレイヤーを管理するのが責任なんだな!」的な考えで破滅的なクソコードを書いてしまうケースもあるそうです。 知り合いの話ですけど。
そのために、明確でわかりやすく実践できる方法論を紹介しました。
これら3つのルールを守ってコードを書けば、そんなに破滅的なクソコードになることはないかと思います。
そして、破滅的なクソコードではないコードを書くと同時並行で、クリーンアーキテクチャやSOLID原則、ドメイン駆動設計などを学んでいただき、その都度コードに反映していってください。
この記事を最後まで読まれているということは、あなたはおそらく自分のコードに対して一定の問題意識はあるのではないでしょうか。
もちろん設計手法を学ぶとは重要ですが、コードを書くとはそれ以上に大事なことだと考えています。
その上で、とりあえず現状はこの3つのルールを守ってそこそこのコードを書いておけば、将来新しく設計手法を学んだ時のために、リファクタリングの余地を残しておけるのではないでしょうか。
この記事が、みなさんが設計を学習し、リファクタリングするまでお時間稼ぎになれば、私としては本望です。
皆様のよきプログラミングライフを祈っております。
最後に、参考文献や役立つ書籍など、設計について学べる本やリンクを紹介しておきます。
この本を読んでいる間は、とりあえずこのルールを守りながらコードを書いておいて、新しいことを学んだらリファクタリングしてみてください。
謝辞
この記事を書くにあたって、レビューしていただいたUnityゲーム開発者ギルドのやまださん、のたぐすさん、いもさん、nさん、Fooさん、とりすーぷさん、また、私の友人の皆様、本当にありがとうございました。お礼申し上げます。
参考文献
一つのクラスは150行以内に収める
- プログラマが知るべき97のこと 単一責任原則
- 単一責任原則で無責任な多目的クラスを爆殺する
- 単一責任の原則(Single responsibility principle)について、もう一度考える
- プログラミング中級者に読んでほしい良いコードを書くための20箇条
循環参照はしない
継承はしない
- Item 18: 継承よりコンポジションを選ぶ
- 【C#】インターフェイスの利点が理解できない人は「インターフェイスには3つのタイプがある」ことを理解しよう
- クラスの「継承」より「合成」がよい理由とは?ゲーム開発におけるコードのフレキシビリティと可読性の向上
- 君の継承の使い方は間違っている
- 継承やめろマジやめろ。 なぜイケないのか 解説する
その他
役立つ書籍
リーダブルコード
アダプティブコード
クリーンアーキテクチャ
ドメイン駆動設計入門
現場で役立つシステム設計の原則
アジャイルソフトウェア開発の奥義
Java言語で学ぶデザインパターン入門