SORACOM Advent Calendarの17日目の記事になります。
embulk-input-soracom_harvestというEmbulkのプラグインを書いたというお話です。
何か要望あればGitHubにIssue立てるかTwitterでメンション貰えればと思います。
もちろんpull-requestも歓迎します。
sakama/embulk-input-soracom_harvest - Github
先月2016年11月末にSORACOMからSORACOM Harvestというサービスが発表されました(2016年12月現在Public Beta)。
IoTデバイス等からデータを収集・蓄積できるサービスです。
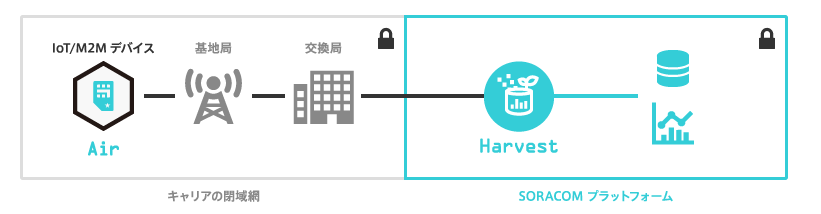
https://soracom.jp/services/harvest/
今までSORACOM Funnelという特定のクラウドサービス向けにストリームにデータを送信できるサービスはありましたが、こちらはHarvest内にデータを保存することができるようになっており、またユーザコンソール内でデータを可視化することもできます。
このHarvestですが、現時点ではいくつか制約事項があります。
まず40日間のデータ保持期限があり、それを過ぎたデータは削除されることになっています。
また、SORACOMのユーザコンソール内のグラフでの可視化はBIツールと比較すると簡易的なものです。SORACOM外で収集したデータとのクロス集計を行うことなどもできません。
あくまで簡易的にデータの傾向を可視化するツールといったところでしょうか。
そこでembulk-input-soracom_harvestというEmbulkのプラグインを書きました。
これを利用することでSORACOM Harvestから外部のRDBMSはもちろんTreasure DataやBigQuery、Redshift等のデータストアにもデータをバルクロードし、データ解析やデータの無期限アーカイブを行うことができるようになります。
Embulkとは?
Embulkは一言で言うとFluentdのバッチ版となります。
組み込み系のエンジニアの方にはFluentdも馴染みがないかもしれません。FluentdはOSSのストリーミングデータインポートツールでGoogleの基盤などでも使用されている実績のあるソフトウェアです。
Google、FluentdをKubernetesとCompute Engineの標準ログコレクタに採用 - Qiita
プラグイン構造となっており、数々のプラグインを使用することでS3/等のサービス・ミドルウェアに対してほぼリアルタイムにデータをロードすることができます。
Fluentdと同じようなプラグイン機構を持ちつつバルク(一括)データロードを行うのがEmbulkになります。
こちらもOSSとなっており、既に以下のような150以上のプラグインが既に存在し、大規模な利用事例も多くなっています。
- PostgreSQL、MySQL、SQL Server、OracleのようなRDBMS
- S3、GCS(Google)、Azure Blob Storageのようなクラウドサービス上のオブジェクトストレージ
- Treasure Data、BigQuery、Redshift等のビッグデータ向けデータストア

Embulk, an open-source plugin-based parallel bulk data loader
自前のスクリプトでバルクロードを行おうとすると、in(M個)/out(N個)の数に応じてM×N個のスクリプトが必要になります。
プラグイン機構を持つEmbulkを使うことでM+N個のプラグインがあれば事足りますし、既にプラグインが公開されている場合にはそれを利用することもできます。

『Embulk』に見るモダンJAVAの実践的テクニック 〜並列分散処理システムの実装手法
今回書いたembulk-input-soracom_harvestと既存のプラグインを組み合わせると、Harvestから任意のRDBMSやデータストアにデータをロードすることができます。
使い方
Embulkの動作にはJava7以上が必要です。事前にインストールしておいて下さい。
インストール
# 本体のインストール
$ curl --create-dirs -o ~/.embulk/bin/embulk -L "http://dl.embulk.org/embulk-latest.jar"
$ chmod +x ~/.embulk/bin/embulk
$ echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
$ source ~/.bashrc
# SORACOM Harvest向けのプラグインのインストール
$ embulk gem install embulk-input-soracom_harvest
config.ymlの作成
Embulkの設定ファイルはYAMLで記述します。
事前にユーザコンソールで AuthKey ID と AuthKey Secret を生成しメモしておいてください。
$ vim seed.yml
in:
type: soracom_harvest
auth_key_id: <生成したAuthKey ID>
auth_key: <生成したAuthKey Secret>
target: harvest
out: {type: stdout}
Embulkにはguessというデータからそのスキーマを推測する機能があるので実行してみます。
SIMが登録されていない、またはHarvestに有効なデータが存在しない場合には推測ができないためエラーとなります。
$ embulk guess seed.yml -o config.yml
in:
type: soracom_harvest
auth_key_id: <生成したAuthKey ID>
auth_key: <生成したAuthKey Secret>
target: harvest
columns:
- {name: content, type: json}
- {name: contentType, type: string}
- {name: time, type: timestamp}
out: {type: stdout}
今回HarvestにはJSON型のデータを登録しており、contentTypeも'application/json'となっているため、contentカラムの型は'json'として推測されました。
それ以外のcontentTypeの場合にはstringとなります。
生成されたconfig.ymlでロードができるかpreviewしてみます。
後述のtargetオプションにsimsを指定していてカラム数が多い場合は、-Gオプションを付けると見やすい形で表示されます。
Harvest上の各種時刻は1443866271291のようなミリ秒まで含むUNIX timestamp形式ですが、2016-12-09 13:23:25.329000 UTCの形式で表示します。
UNIX Timestamp形式がよい場合、timestamp型となっているカラムの定義をlongに手動で変更してください。
ただし、後続のEmbulk outputプラグインで時刻として処理したい場合はtimestamp型の方が処理しやすいと思います。
$ embulk preview config.yml
+---------------------+--------------------+-----------------------------+
| content:json | contentType:string | time:timestamp |
+---------------------+--------------------+-----------------------------+
| {"temperature":20} | application/json | 2016-12-21 08:59:59.748 UTC |
| {"temperature":100} | application/json | 2016-12-21 09:00:07.699 UTC |
| {"temperature":11} | application/json | 2016-12-21 09:00:14.042 UTC |
+---------------------+--------------------+-----------------------------+
実行
preview結果に問題がなければrunコマンドでロードを実行します。
$ embulk run config.yml
2016-12-22 13:09:05.324 +0900: Embulk v0.8.15
2016-12-22 13:09:05.965 +0900 [INFO] (0001:transaction): Loaded plugin embulk/input/soracom_harvest from a load path
2016-12-22 13:09:06.014 +0900 [INFO] (0001:transaction): Using local thread executor with max_threads=8 / output tasks 4 = input tasks 1 * 4
2016-12-22 13:09:06.040 +0900 [INFO] (0001:transaction): {done: 0 / 1, running: 0}
2016-12-22 13:09:07.470 +0900 [INFO] (0015:task-0000): 2 SIMs found
2016-12-22 13:09:08.747 +0900 [INFO] (0015:task-0000): 1213 records found at Soracom Harvest for SIM: 4412345667890123
2016-12-22 13:09:08.901 +0900 [INFO] (0015:task-0000): 2457 records found at Soracom Harvest for SIM: 4412345667890124
{"temperature":20},application/json,2016-12-21 08:59:59.748000 +0000
{"temperature":100},application/json,2016-12-21 09:00:07.699000 +0000
{"temperature":11},application/json,2016-12-21 09:00:14.042000 +0000
...
2016-12-22 13:09:08.906 +0900 [INFO] (0001:transaction): {done: 1 / 1, running: 0}
2016-12-22 13:09:08.926 +0900 [INFO] (main): Committed.
2016-12-22 13:09:08.927 +0900 [INFO] (main): Next config diff: {"in":{},"out":{}}
今回Output先をstdout(標準出力)としたため、画面上にデータがずらずらと表示されたと思います。
便利なオプション、プラグインについて
targetオプション
このプラグインではHarvestに格納されているデータ以外にSIMの一覧も取得することができます。
上のconfigでtarget: harvestとなっていた部分をtarget: simsとすると動作します。
in:
type: soracom_harvest
target: sims # または"harvest"
...
filterオプション
filterオプションでは以下のように特定条件に一致したSIMのデータを取得するためのフィルターを設定可能です。
ただし異なるfilterの同時指定(SQLで言うAND、OR等)はできません。
これ以上の複雑なフィルタリングを行いたい場合は後述のfilterプラグインを検討して下さい。
- 特定のSIMのデータのみ取得
in:
type: soracom_harvest
target: harvest
filter: imsi:4412345667890123
...
- 特定のタグが付けられたSIMのデータのみ取得
in:
type: soracom_harvest
target: harvest
filter: tag_name: tag_value
tag_value_match_mode: exact # or 'prefix'
- ステータスが任意のSIMのデータのみ取得
in:
type: soracom_harvest
target: harvest
filter: status: ready
値を'|'で区切ることで複数ステータスのSIMのデータ取得も可能です。
in:
type: soracom_harvest
target: harvest
filter: status: active|ready
- 特定の速度クラスのSIMのデータのみ取得
in:
type: soracom_harvest
target: harvest
filter: speed_class: s1.minimum|s1.slow
こちらも複数の速度クラスのSIMのデータ取得も可能です。
start_datetime, end_datetimeオプション
任意のタイムスタンプ以降(以前)のデータのみ取得します。
in:
type: soracom_harvest
target: harvest
start_datetime: '2016-11-13 08:13:12.042 +0000'
end_datetime: '2016-12-21 09:00:14.042 +0000'
よくありそうな質問
Q. 全てのカラムをロードする必要はなく、dropしたいカラムがある。
A. embulk-filter-columnで行けます。
Q. HarvestにJSONでデータを格納しているがこれを展開したい。
A. embulk-filter_expand_json で。
Q. Embulkで処理したタイムスタンプを付与したい
A. embulk-filter_add_time で。
Q. SQLのWHERE句の様に格納されている値に応じて取得するデータを選択したい
A. embulk-filter-row で。
ただし、HarvestにJSONデータを格納している場合、上記のembulk-filter_expand_jsonを使って一旦JSONを展開する必要があります。
in:
type: soracom_harvest
...
filters:
- type: expand_json
...
- type: row
...
Q. 格納されているデータに対して複雑な前処理を行いたい
embulk-filter-ruby_procで。
参考:EmbulkでMySQLからBigQueryに入れ子になったJSONファイルを直接インポートする方法 - Qiita
ただし一般論としてEmbulkのfilterはJavaベースのプラグインの方が高速です。
参考:embulk で pure java と jruby でプラグインを作ったときの速度比較
Q. GZIP圧縮してリモート上にファイルとして保存したい
A. Embulk標準のGZIPエンコーダープラグインを使ってください。
Q. 望む処理をやってくれるプラグインが見当たらない...
プラグインを書くんだ!
SORACOM Funnelとどっちがいいのか?
SORACOMにはFunnelというサービスがあります。
どちらが良い悪いではなくユースケースに合わせて選択すべきと思います。
バルクロードの場合リアルタイムでデータを外部のRDBMSやデータストアで可視化することはできないので、SORACOMのSIMを差した機器から送られたデータの異常をリアルタイムで検知したい用途等の場合には、ストリーム処理が可能なFunnelを使う方が良さそうです。
もちろん、自前でSIMを差した機器からFluentd等を使ってどこかに送信する処理を書くこともできると思いますが、その場合アクセスキー/シークレットキー等の機密情報を機器内で保持する必要がでてきたりするので、あまり積極的に使いたい手段ではないと思います。
一方でFunnelはAWS Kinesis等のクラウドサービスとの接続を行うサービスであるため、オンプレ環境内のRDBMSにデータをインポートしたい場合はバルクロードが現状唯一の選択肢となると思います。また機器から送信されたデータや外部の何かしらのデータが大量にあり、これらを用いた大規模データ解析を行いたい場合にもバルクの方が適していそうです。
実装について
SORACOMからRuby SDKが出ているので、これを使って実装しています。
ただしHarvestについてはまだSDKではサポートされていないようなので、今回APIに向けて直接HTTPリクエストを送信しています。
と言ってもRubyなのでそんなにコードが膨れることもなく、サクッと書けました。
あとSORACOMのAPIリファレンスは実際にリクエストを送ってレスポンスを確認できるので開発時に便利。
GCP(Google Cloud Platform)のAPIリファレンス等最近多くなった形式ですが開発者フレンドリーで良いなと思いました。
Ruby SDKのドキュメントには書かれていないのですが、Ruby SDKのソースコードを読むとSIM一覧を取得する場合にfilter機能が使えるようです。
embulk-input-soracom_harvestプラグインのfilterオプションはこの機能を使って実装しています。
^うまく動作しなかったので自前でAPI叩きました。
まとめ
なんとか年内にリリースできた。。。