OSSとしてのEmbulkにTreasure Dataはどのように関わっているのか
Embulk Advent Calendar 2015の1日目の投稿になります。
今年の9月にSoftware EngineerとしてTreasure Data(以下TD)に入社していた赤間(@oreradio)です。
最近はData Connector(後述)などの開発でJava/Rubyを書いています。
さて、OSSのバルクロードツールであるEmbulkが公開されて約1年が経ちました。
- 並列・分散処理、リトライ、リジューム等をサポートする
- プラガブルな構造
- guessによる設定ファイル生成支援
- OSSとして公開されている
などが特徴的な訳ですが、プラグインも90個近くが公開されOSSとして順調なスタートではないかと思います。
一方で本体やプラグインを含めた巨大なエコシステムをバルクロードという信頼性が求められる分野で全てOSSとして公開・メンテされる仕組みは果たして上手く回るのか、信頼性が担保されるのかという疑問を持っている方もいらっしゃると思います。
OSSとしてEmbulkが成功するためには
- コアコミッタの存在
- ユーザコミュニティが活発であること
等が求められると思います。
そして開発元であるTDがEmbulkにどのように関わっている(いく)のかはEmbulkがOSSとして成功する上で重要なポイントになると思います。
そこで1日目の今日はそこについてご紹介したいと思います。
そもそもEmbulkって何だ?という方は「並列データ転送ツール『Embulk』リリース! - Blog by Sadayuki Furuhashi」辺りをご覧ください。
おさらい
まずおさらいでTDのOSSに対するスタンスについて既に公開されているインタビュー記事をさらってみます。
まずはCTOの太田へのインタビュー記事です。
「いわゆるオープンソースソフトウェアの中で基本機能は無償で公開してコミュニティに任せる、でも機能を追加したソフトを有償で提供するというモデルは実際にはそんなに上手く行ってないのではないかと感じています。」-「「Fluentdをきっかけにビジネスが回る仕掛けがとっても気持ちイイです。」 | Think IT(シンクイット)」
続いてEmbulkを開発した古橋へのインタビュー。
「オープンソースソフトウェアといってもいろいろな開発スタイルがあると思うんですが、fluentdの場合、僕が所属するトレジャーデータが全面的にバックアップしています。現在は、この開発スタイル「企業がバックについているけど、開発はオープンに行う」という手法が一番合っていると思います。」- OSや言語ではなくデータベースを極めたい:グリー技術者が聞いた、fluentdの新機能とTreasure Data古橋氏の野心 (2/3) - @IT
fluentdを念頭に置いた回答が多いのですが、EmbulkについてもTDがバックに付いてコア部分等重い部分の開発は引っ張っていくが、開発は全てオープンに行うという形になっています。
Embulkへの関わり
TDでのEmbulkの利用
実はEmbulkはサービスとしてのTreasure Data Serviceで既にHosted Embulkという形でData Connector(import側)、Result Output(export側)としてサービスに投入されています。恐らく現時点では最大のユーザではないかと思います。
細かい説明は省略しますが
- TD APIがコンソールやコマンドラインからのユーザの要求を受け付けPerfect Queue(PQ)にenqueue
- TD WorkerがPQからdequeueし、バルクインポートジョブとしてEmbulkに渡す
- Embulk(Hadoopクラスタ上のMapReduce ExecutorまたはLocal Executor)でバルクインポートジョブを実行、ジョブが失敗した場合は必要であれば再実行
という形になっています。
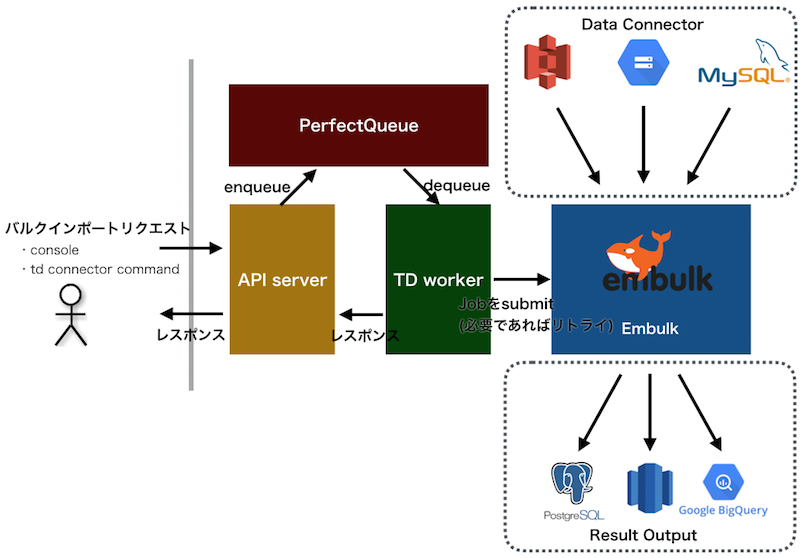
12/1現在では
- Data ConnectorがAWS S3、MySQL、Google Cloud Storage
- Result OutputではPostgreSQL、MySQL、Redshift、BigQuery
等が存在し今後も増える予定です。
※Embulkがサービスに投入される前からあるので、Data Connector/Result Outputの全てがEmbulkのプラグインという訳ではないです。
Embulk本体の開発
そしてここがポイントなのですが、サービスに投入するにあたって本体/プラグイン共にforkして独自のカスタマイズを加えることは行っていません。OSS版そのままです。ここで何らかのカスタマイズを加えてしまうとEmbulk本体/プラグインの変更に追従できなくなりサービス展開のスピード感が失われてしまいます。
ですので、もし何かしらの不具合が見つかった場合には修正は全てOSSとしてのEmbulkに反映されます。
本体の開発についてはGithub上でEmbulkをwatchしている方はうちの古橋がコードをコミットしているのを見ているかと思いますが今後も積極的に関わっている(いく)方針です。JSON型のサポート辺りは近いうちに実装する必要がありそうです。
私もData Connector/Result Outputが落ち着いたらそちらに回ると思います。。
プラグインの開発へのコミット
前述のような形でEmbulkを利用していますので、自社のサービスに投入したい機能を持つプラグインには積極的に開発に参加する必要があります。
既に公開されている場合はそれを利用できるのでこの辺がTDがEmbulkをOSSとして公開する「動機」になります。
公開されていない場合は当然0から開発する必要があります。
fluentdの場合はfluentdのコアな部分の開発にTDのメンバーが積極的に参加し、プラグインについてはOSSとしてコミュニティに委ねる(可能であれば参加する)という形でしたが、Embulkの場合はここが少し異なる点です。
開発に関わるのは機能追加に限りません。TDの社内のルールとして本番環境に投入するプロダクトはユニットテストのカバレッジが原則として80%に達していること、達していない場合はできるだけ早期に達成すること、というものがあります。これによりコードのクオリティを担保しています。
これはEmbulk本体/プラグインも例外ではなく、外部の方が書かれたEmbulkプラグインをData Connector/Result Outputとして採用することになったがユニットテストのカバレッジが足りないとなった場合は、ユニットテストを追加するpull requestをお送りしてマージをお願いした上でTDのサービスに取り込むことになります。(とはいえ本体は間に合っていない。。)
またこれは公開されていませんがTDの各システムとの接続を確認するインテグレーションテストもプラグイン毎に存在し、ここでも問題なく動作するかがCIで日々チェックされています。
Treasure Data Serviceのテストに特化している部分もあるのですが、そうでないOSS版に生かせる部分もあります。
これらのプロセスを経てプラグインがTDのサービスに投入された際には、皆さんがOSSとしてこのプラグインを使う際にもこの恩恵(バルクロードツールとして堅いこと)が受けられることとなります。
こういったWin-Winな関係をOSS版Embulkのコミュニティと築くのがTDとしての理想の形です。
皆さんへのお願い
ここまでOSSとしてのEmbulkへのTDの関わりを書きましたが、OSSとしてEmbulkが成功するためにはやはりユーザコミュニティが活発であることも必要です。
ここ1年の動きを見ているとEmbulkユーザはエンタープライズ分野の方も多いようで、実は使っているけどオープンにしていないという例が多いのではないかと思います。
私も前職はエンタープライズな開発でしたが、OSSの場合はプロプライエタリなプロダクトは異なり、開発元の営業やマーケティング、ユーザサポート側からヒアリングしてくれてプロダクトが強化される訳ではありません。
オープンになっていない要望などを各開発者がエスパーしていつの間にか欲しい機能が実装されるにも限度があります(労力に限界があるので要望がないものはニーズがないとして後回し)。
ですので...
- こういう形で使っている、ここが分からない等をブログなどで書く
- バグや要望等をIssueで上げる
- 可能であればpull requestを送る
- Twitterで呟いてみる
等ユーザの皆さんに具体的なアクションを起こしてもらうことも必要かなと思います。
というわけでEmbulk Advent Calendar 2015後半がまだ空いていますのでこんな形で実は本番投入している、ここが悩んでいる、試してみた等あれば是非Open&Shareをお願いします。
ちなみにFluentd Advent Calendar 2015 - QiitaもあるのでOpen&Shareを(ry
告知
2週間後の12/15(火)にEmbulk Meetup Tokyo #2をやります。
Embulk開発者の古橋によるEmbulkのコア部分の話以外にDeNAさんやGMOインターネットさんでのEmbulk活用事例なども聞くことができます。
古橋や私含めTDのエンジニアも参加するので色々ご相談等あればそれも。是非ご参加下さい。
またその前日の12/14(月)にはWorkflow Hacks! #1というイベントの開催も予定しています。こちらもご参加をお待ちしています。
最後に
2日目の明日は2日連続になりますが、私がバルクローダーとして必要なリトライやresumeの実装について書きたいと思います。