この記事は 漢直 Advent Calendar 2015 の12日目の記事です。
本記事の目的
Let's type with tut-code というサイトには、TUT-Codeという入力方式において、「何文字の漢字のストロークを覚えると日常で使う漢字のうち何割を変換無しで打てるか」という情報が載っています。
では、TUT-Code以外の入力方式ではどうなのでしょう。本記事は、漢直の入力方式ごとに、変換せずに打てる文字の割合を調べることを目的とします。
調査対象の入力方式
以下の4つの入力方式について調べます。()内はその入力方法で打てる文字数です(ひらがな・かたかな・記号を含む)。
- T-Code (1356文字)
- TUT-Code (2611文字)
- G-Code (2070文字)
- phoenix (3645文字)
コード
調査に使ったコードは github に置いてあります。
調査に利用するデータ
日本語版Wikipediaの記事全文のダンプデータを利用します。ダンプした日にちは2015年12月2日です。
先述のサイトとはデータの種類が違うため、文字の出現率が異なっていると思います。これは失敗でした。
流れ
- ダンプデータのダウンロード
- XMLタグの除去
- 文字のカウント
- それぞれの文字が変換なしで打てる文字かどうかを漢直の入力方式ごとに判定
- グラフを描画
"Qiitaは、プログラマのための技術情報共有サービスです。 プログラミングに関するTips、ノウハウ、メモを簡単に記録 & 公開することができます。"とあるので、ここからは少しプログラミングに関する話をしていきます。
ダンプデータのダウンロード
wgetで取ってきます。
wget -O data/jawiki-20151202-pages-articles.xml.bz2 https://dumps.wikimedia.org/jawiki/20151202/jawiki-20151202-pages-articles.xml.bz2
これで、日本語版Wikipediaのデータがdata/jawiki-20151202-pages-articles.xml.bz2に保存されます。拡張子を見れば分かるように、XMLをbz2で圧縮したファイルです。大きさは2.1Gでした。
XMLタグの除去
wp2txt というツールを利用しました。ruby 1.9.3p484では動き、ruby 2.1.6p336ではうまく動きませんでした。これは私の環境のせいかもしれません。
wp2txt -i data/jawiki-20151202-pages-articles.xml.bz2 -o wikipedia_text/
これで、Wikipediaのテキスト部分がwikipedia_text/内に適当な大きさで分割されて保存されます。Wikipedia記法が完璧には取り除けていませんが、大きな影響はないと思います。
文字のカウント
for f in wikipedia_text/*; do
cat $f | nkf -Z | tr -d '[a-z]' | tr -d '[A-Z]' | tr -d '[0-9]' | grep -o . | LC_ALL=C sort | uniq -c > wikipedia_chars/`basename $f`
done
grep -oで1文字ごとに切った後、sort | uniq -cでカウントします。ここには載せていませんが、別の部分で [亜-腕]|[弌-熙] という正規表現を利用してJIS第一・第二水準の漢字のみを抽出しています。
それぞれの文字が変換なしで打てる文字かどうかを漢直の入力方式ごとに判定
Pythonでコードを書きました。ストロークと漢字の対応を辞書で保存し、順にチェックしてます。
出力はこんな感じです。左から、文字の出現頻度、割合、文字、変換なしで打てるか(T/F)、何ストロークで打てるか、累積密度(ちょっと言葉が違うかも)
17297200 0.0357498071 年 T 2 0.0357498
10388297 0.0214705047 日 T 2 0.0572203
8350979 0.0172597813 月 T 2 0.0744801
5813246 0.0120148014 大 T 2 0.0864949
5140580 0.0106245371 本 T 2 0.0971194
4961634 0.0102546920 学 T 2 0.107374
4466213 0.0092307572 人 T 2 0.116605
グラフを描画
これはプログラムではなくOpenOfficeを利用しました。
結果
X軸は「覚えた文字数」、Y軸は「何割の文字を変換せずに打てるか」です。ここでは簡単のため、出現頻度の高い文字から順にストロークを覚えたと仮定しています。
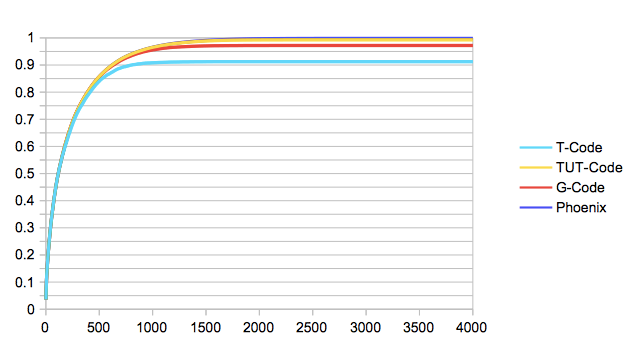
T-Codeが9割でで頭打ちになっている点が目立ちますね。
部分的に拡大すると、以下のようになります。(視覚的にひっかける意図はありません)
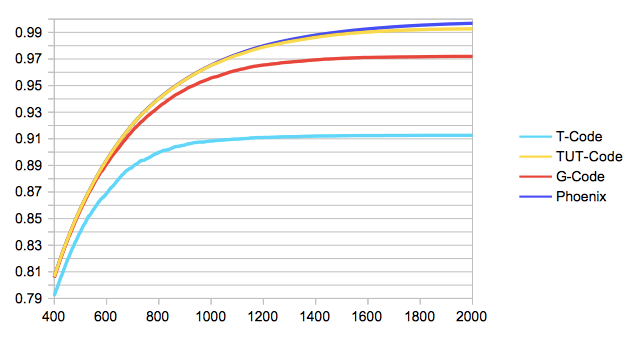
その入力方式で打てる文字数に依存しているので、下からT-Code, G-Code, TUT-Code, phoenixの順に並ぶのは順当ですね。ただ、phoenixとTUT-Codeで1000文字以上収録文字数が違うのに、グラフ上では大きな変化はありません。増えた分の1000文字は出現率の低い漢字ということですね。