Azure Machine Learning Studioとは
Microsoft Azure Machine Learning Studio は、データを活用した予測分析ソリューションの構築、テスト、デプロイをドラッグ アンド ドロップで行うことができるサービス
データセットを Machine Learning Studio にアップロードすることで、これらのデータセットをモデル作成プロセスで使用できるようになります。 Machine Learning Studio には数多くのサンプル データセットが既に含まれているため、これらを実験で試すことができます。引用
**まとめると、GUI操作でScratchと同じような感覚で、Machine Learningができるという優れものです。また、自分の持っているデータセットも使えると! **
Azure Machine Learning Studio のチュートリアル
この機械学習のチュートリアルでは、簡単なデータ サイエンスの実験手順を説明しています。 製造仕様と技術仕様などのさまざまな変数に基づいて自動車の価格を予測する線形回帰モデルを作成します。 これを行うには、Microsoft Azure Machine Learning Studio を使用して、簡単な予測分析の実験を開発し、繰り返します。引用
こちらの引用元のページのチュートリアルを実際に試してみたいと思います!
※注意基本的に作業画像を多めでやっていきますのでページが長いのはご了承ください!
AzureからAzure Machine Learning Studioの起動
まず、Azureのポータルを開き下記のようにMachine Learning ワークスペースを開きます
【新規】➡︎【Intelligence + analtics】➡︎【Machine Learning ワークスペース】
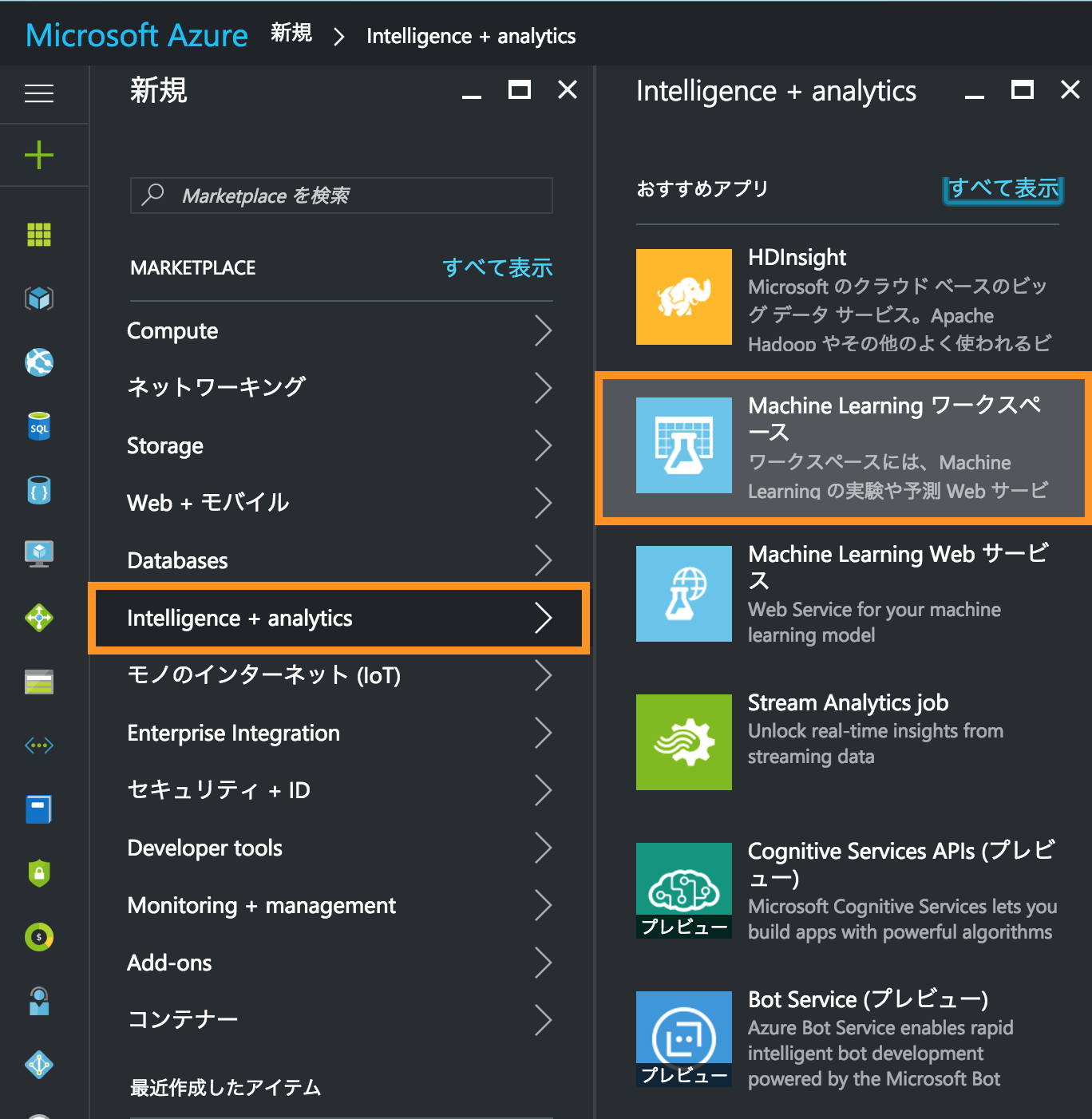
すると設定ができるので適当に設定します。ないものは新規で作ってください!
ストレージ アカウントはML(Machine Learning)で使うデータセットを保存するために使うので設定する必要があるようです
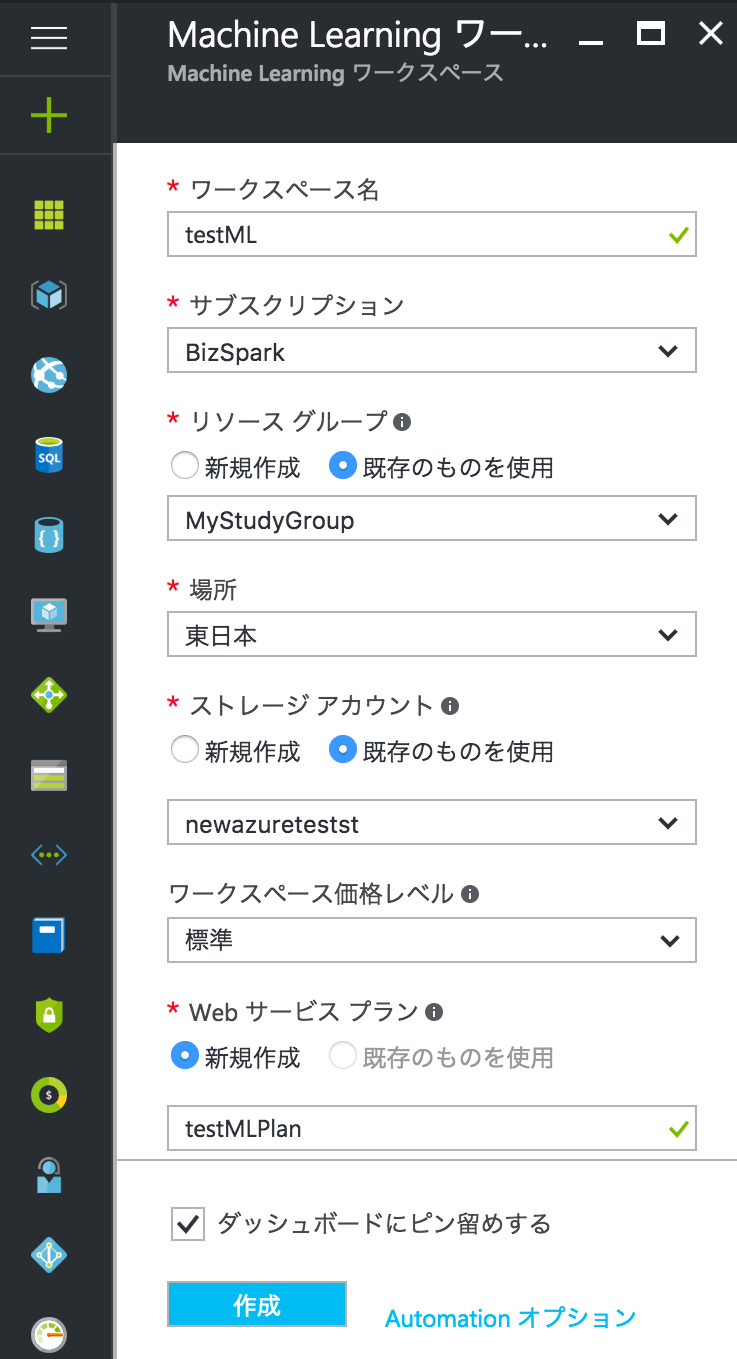
すると、MLワークスペースが開くので、その中にある Machine Learning Studioの起動を実行することで、Machine Learning専用のページに飛ばされます!
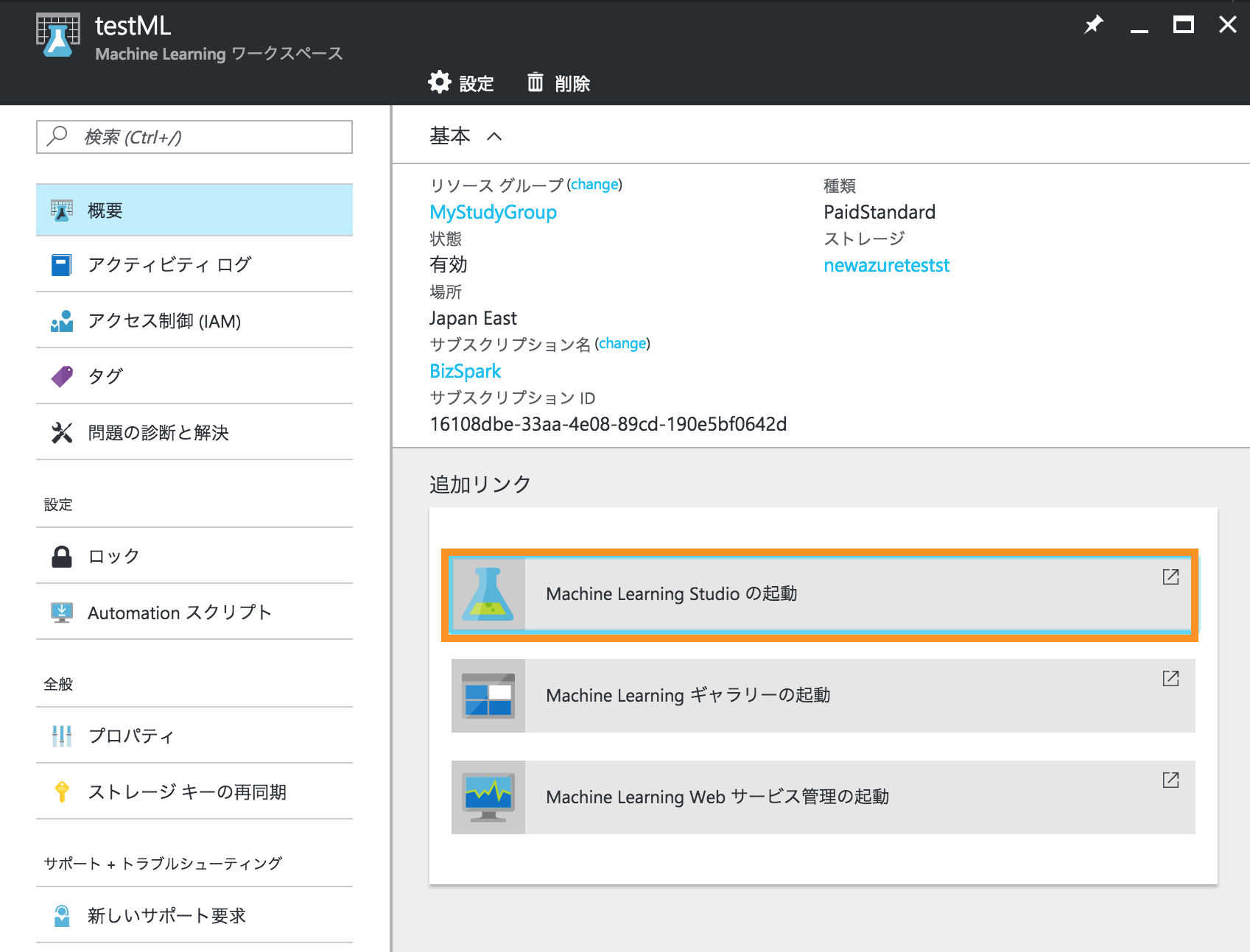
とりあえず、試しにやるだけなので、私はQuick Evaluationを選択し、Machine Learning Studioが立ち上がります
データを取得する
早速、チュートリアル通り進めていきます!
まず、Machine Learning Studioの左下にある**【新規】**から【空のファイル】を選択します。
【新規】➡︎【EXPERIMENT】➡︎【空のファイル】
今回のチュートリアルでは、もともとあるデータから**「自動車の価格を予測」というものです。
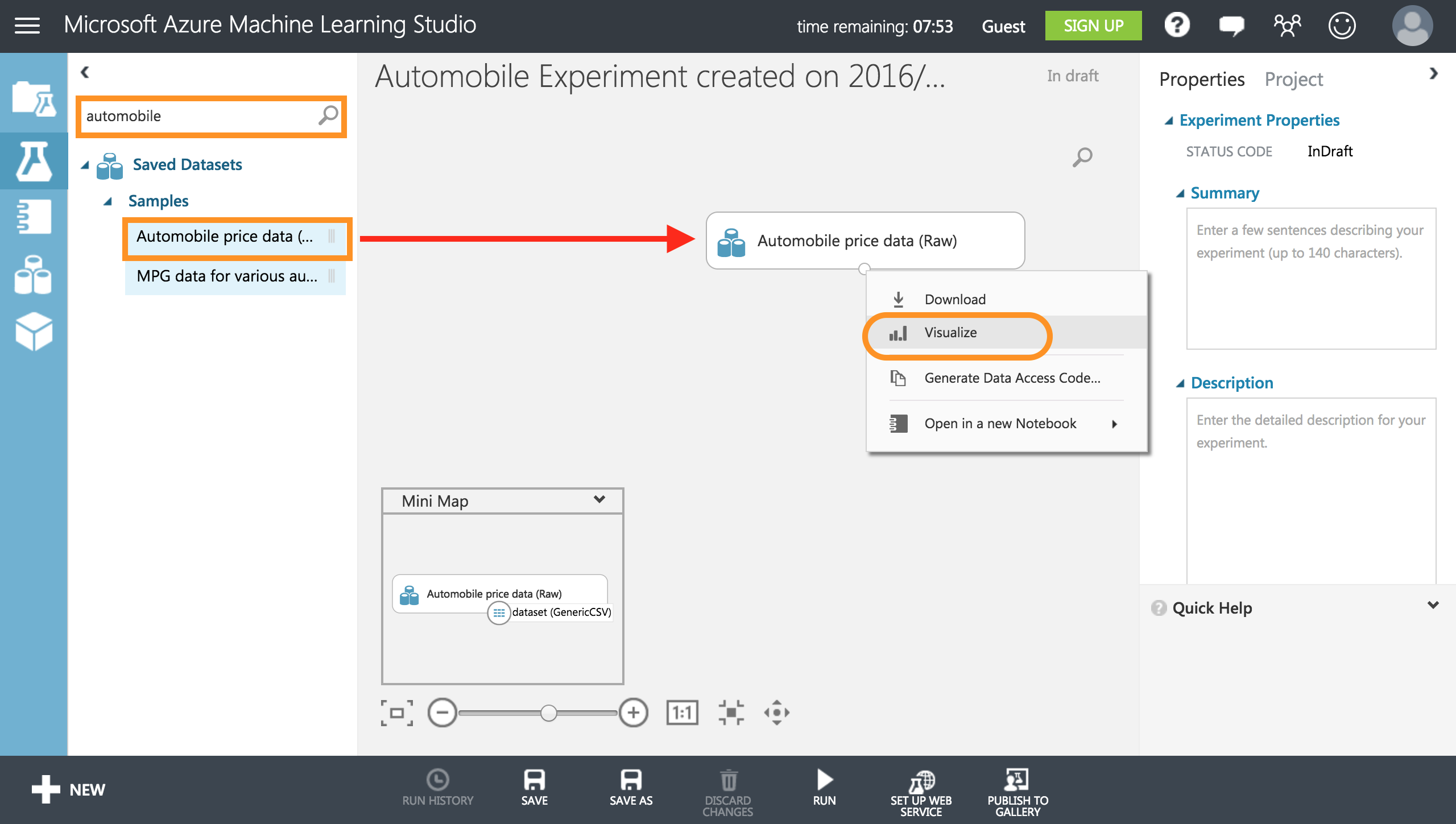
【空のファイル】を選択すると空のキャンバスができるので、左上の検索タブからautomobileと検索し、[Automobile price data]**をキャンバスにドラックします。
データセットを見たい場合はVisualizeを選択することでデータセットを見れます。
また、下の丸い点を右クリックすることで詳しくデータセットについて見れます!
データを前処理する
一言で言えばデータの整形をします。
このデータセットの行に値が不足している列があります。 そこで、モデルがデータを正しく分析するには、これらの不足値を削除する必要があります。 そこで、値が見つからない行をすべて削除する処理を加えます。また、見つからない値の大部分は、正規化された損失列にあります。
まず、 正規化された損失 列を削除してから、見つからないデータがある列をすべて削除します。
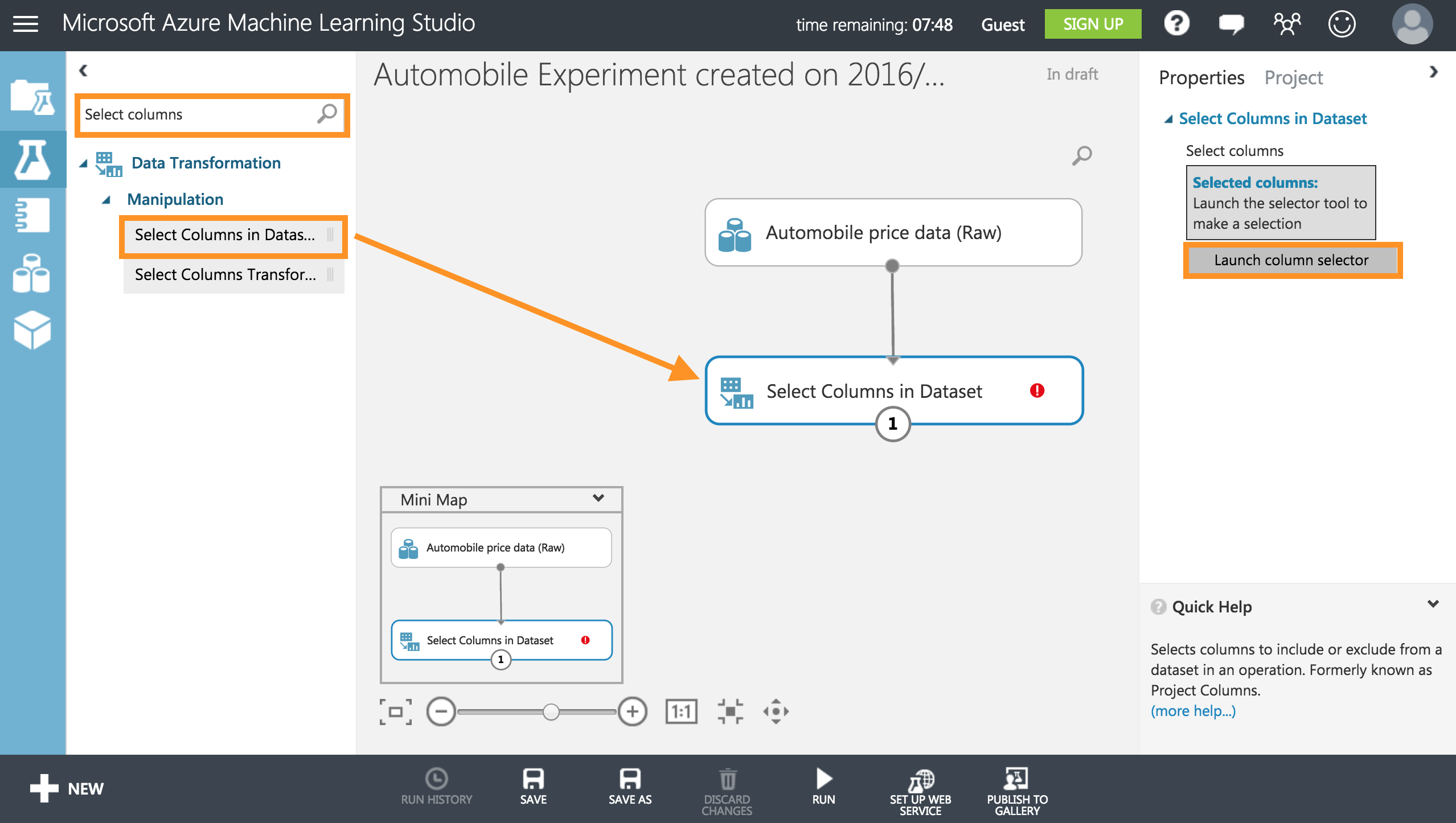
まず、左上の検索タブからSelect columnsと検索し、[Select Columns in Dataset]をキャンバスにドラッグします。その後、右のプロパティーからLaunch column selectorをクリックします。
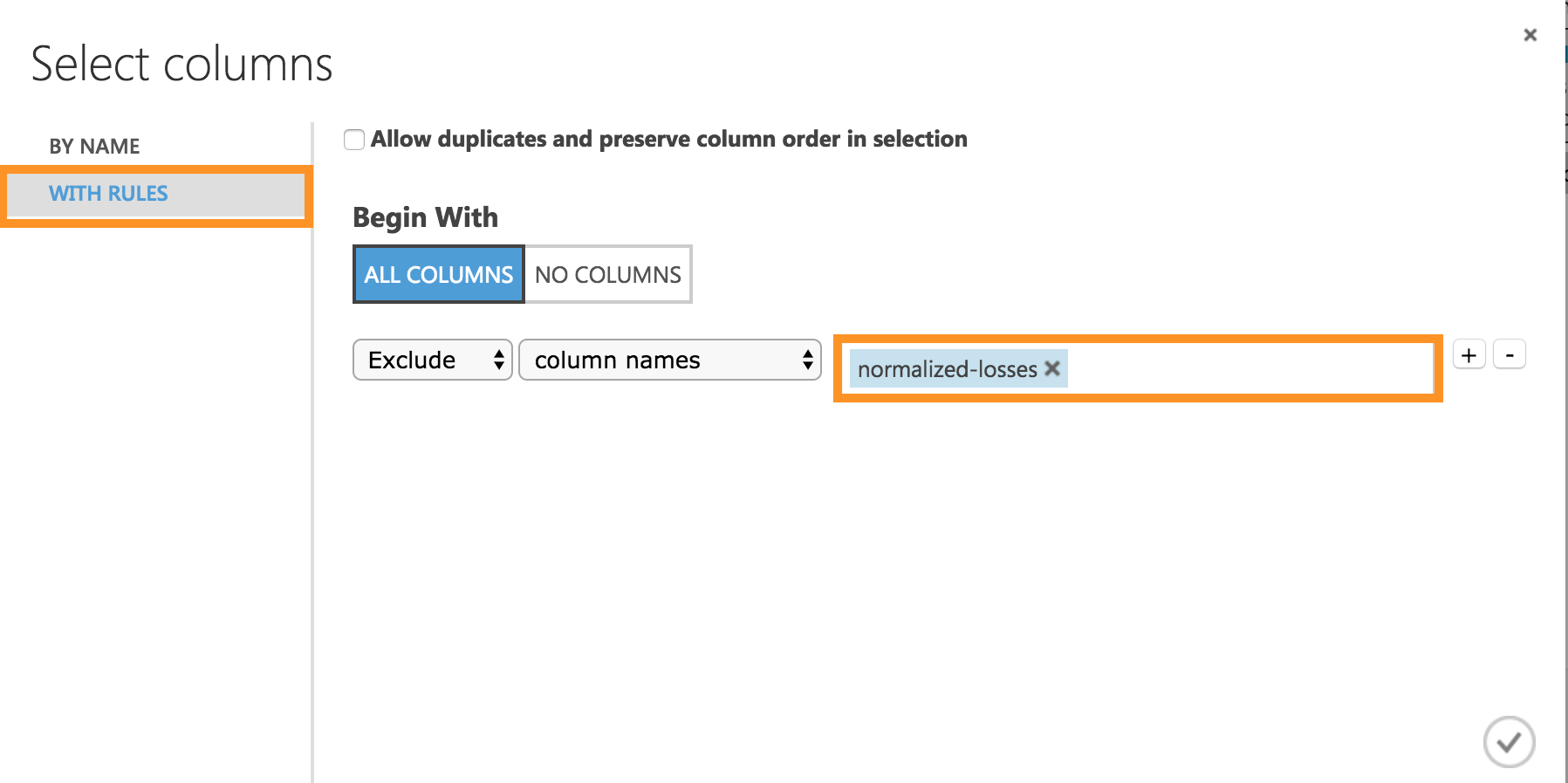
WITH RULESでALL COLUMNSにチェックを入れ、
[Exclude] [Column names] **[normalized-losses]**を記入し追加します。
これにより、正規化された損失列が除去されます
同様に左上の検索タブからClean Missing Dataと検索し、[Clean Missing Data]をキャンバスにドラッグし、右のプロパティーからCleaning ModeからRemove entire rowを選択します。
これで、値が見つからない列を削除してデータを整理します。
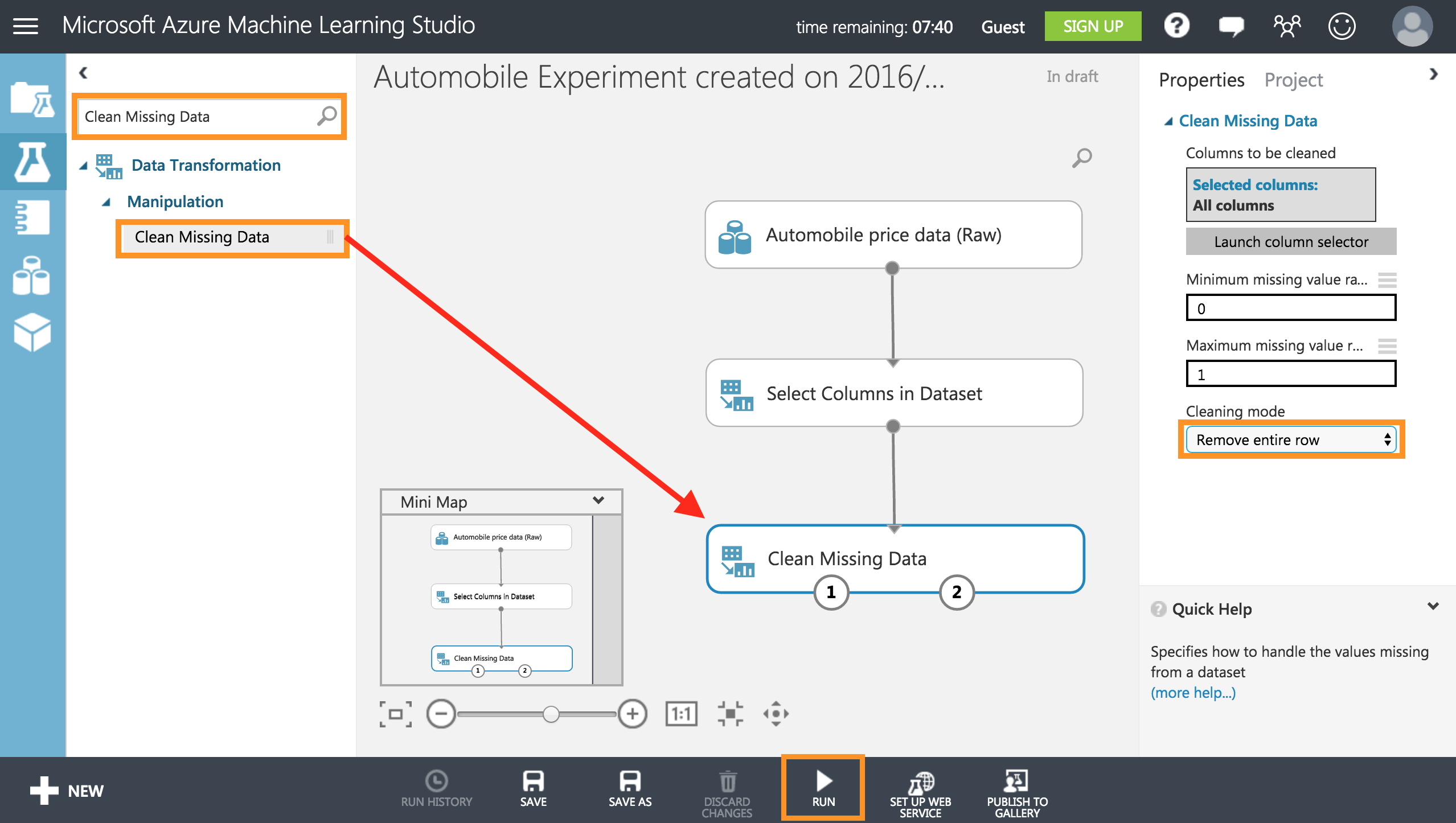
キャンバスの一番下のRUNを実行し完了すると緑のチェックマークができると上手く実行されたことが確認できます。ここまでの流れは、自動車の価格に関するデータセットから損失列を削除し、値が不十分な列を削除したところです。
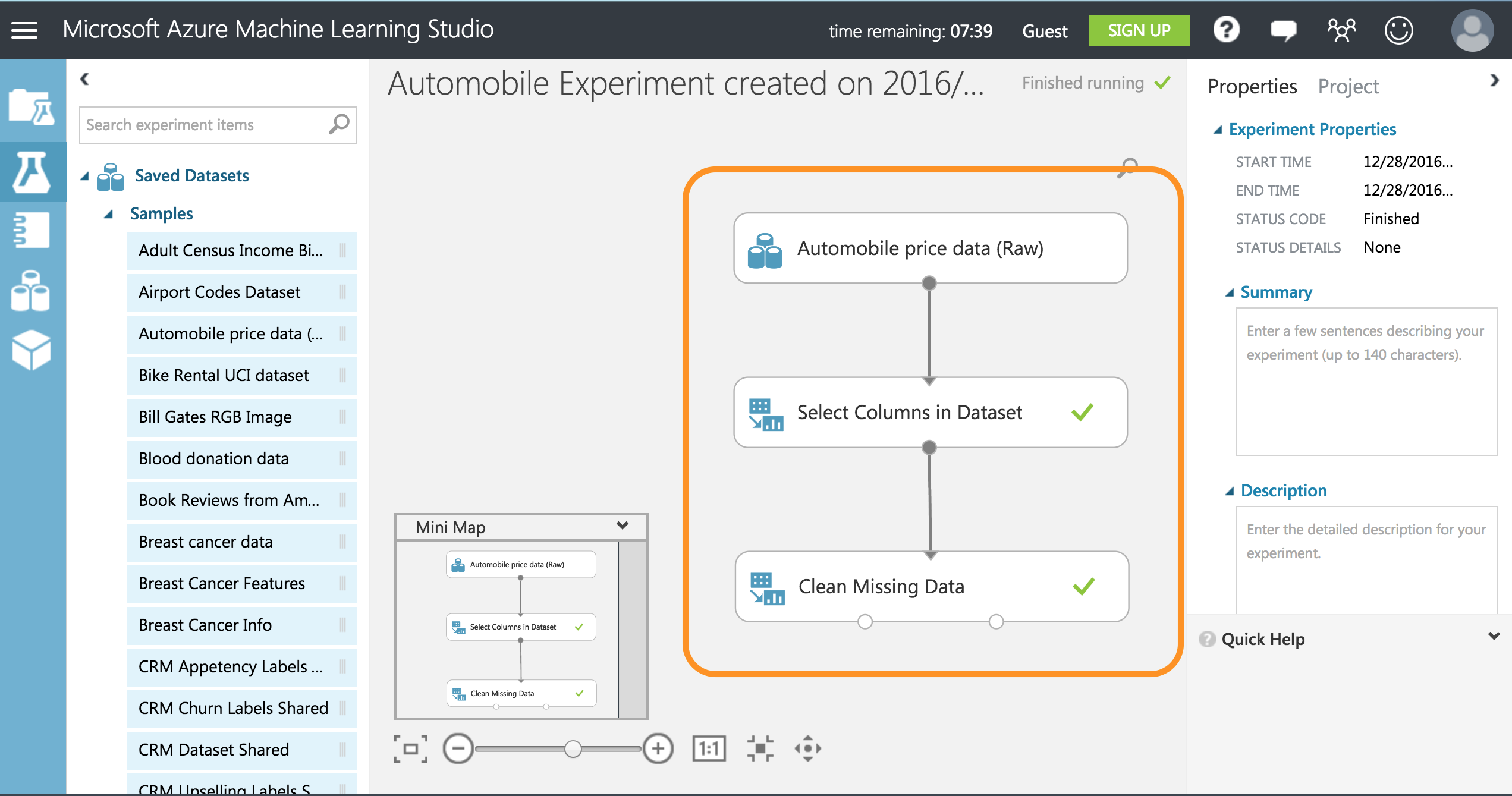
特徴を定義する
データセット内の特徴のサブセットを使用するモデルを構築します。ここで特徴を変えることでデータ全体の精度が変わったりするので、模索が必要が部分です。
同様に左上の検索タブからSelect Columns in Datasetと検索し、[Select Columns in Dataset]をキャンバスにドラッグし、右のプロパティーからLaunch column selectorをクリックします。
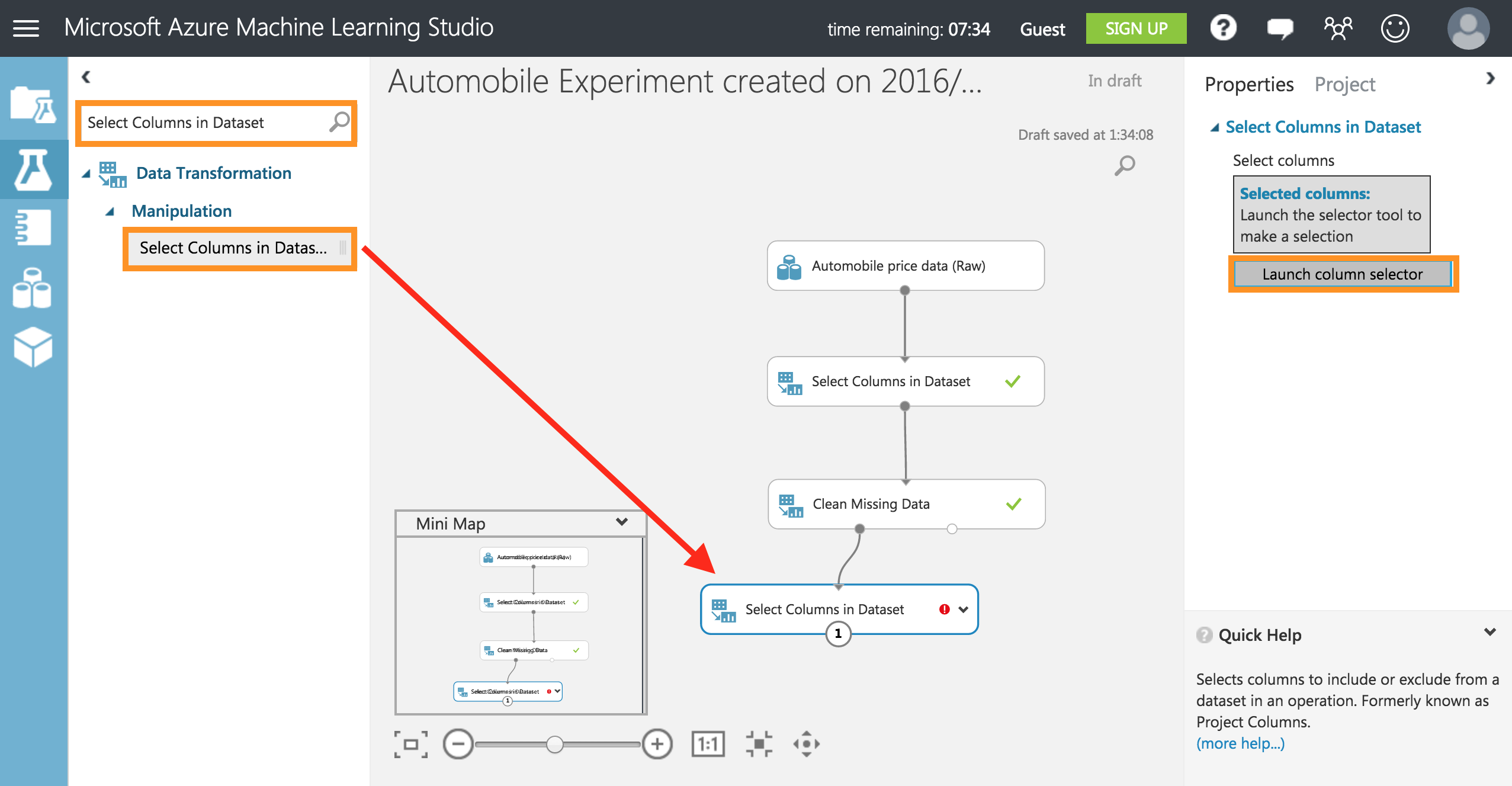
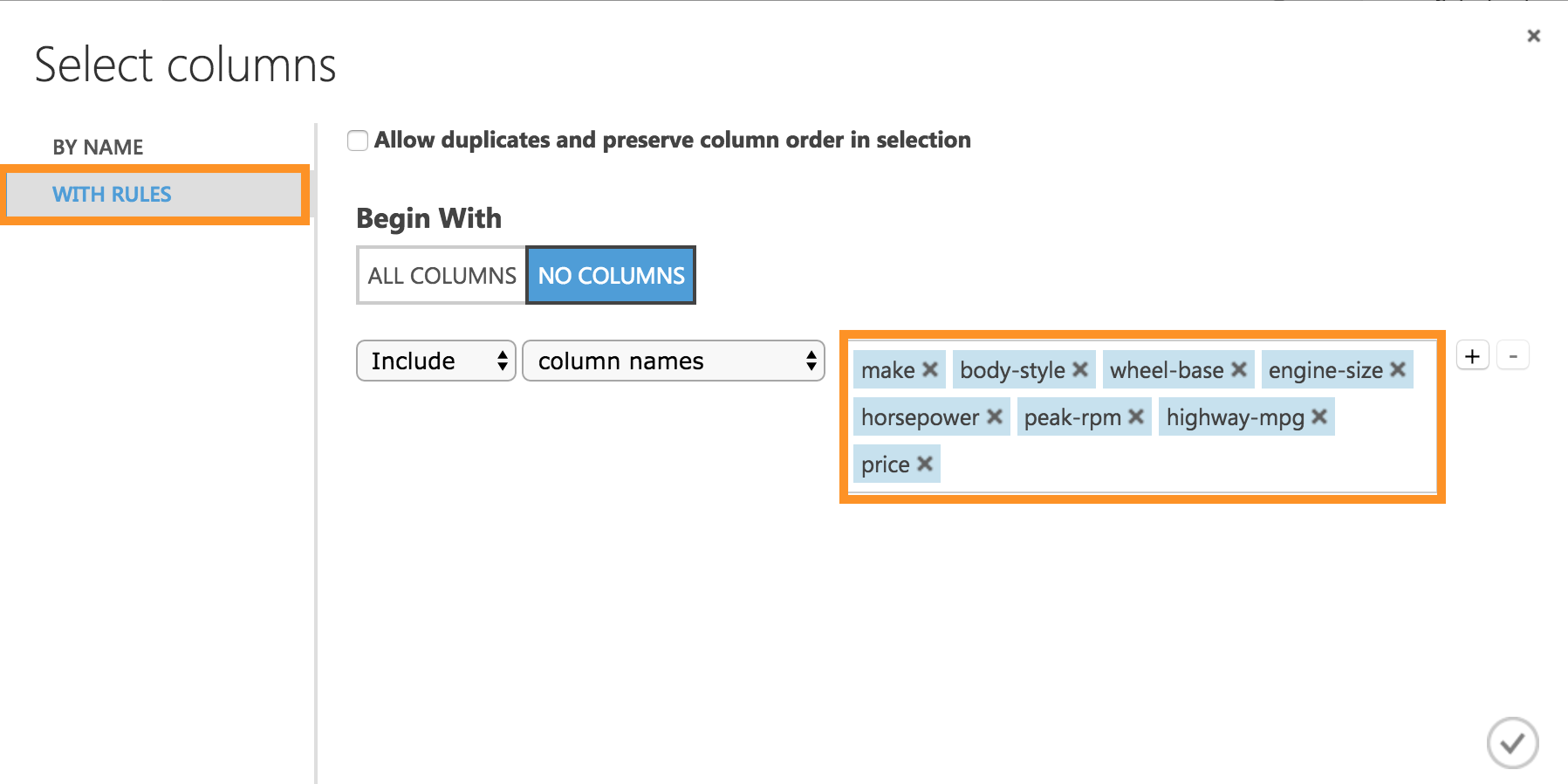
WITH RULESでNO COLUMNSにチェックを入れ、
[Include] [Column names] **[make,body-style,wheel-base,engine-size,horsepower,peak-rpm,highway-mpg,price]**を記入し追加します。
これらの特徴を例として使ってみます。ここで、特徴の抽出をしてくれます。
学習アルゴリズムを選択して、適用する
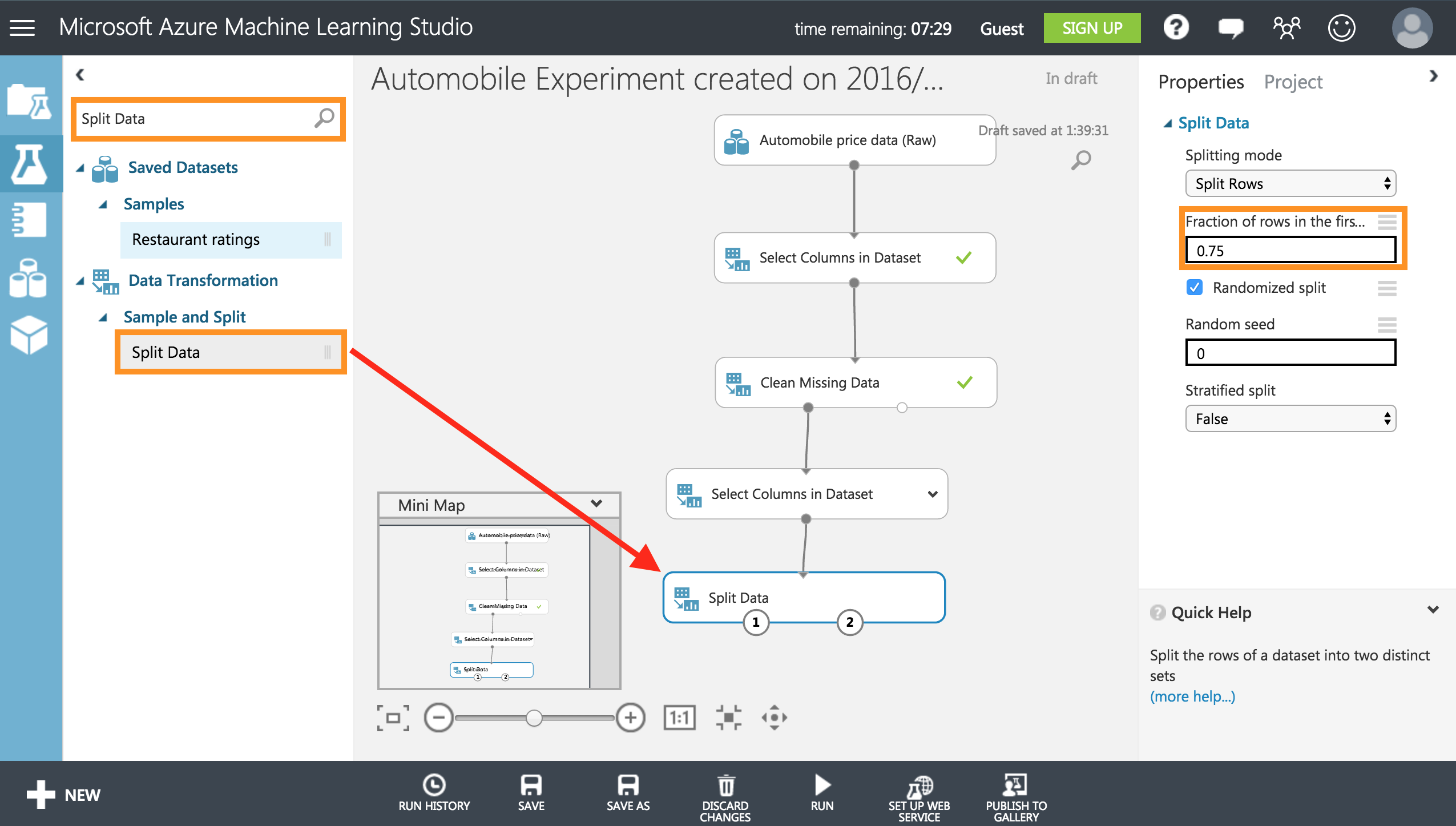
同様に左上の検索タブからSplite Dataと検索し、[Splite Data]をキャンバスにドラッグし、右のプロパティーからFraction of rows in the firstを0.75に設定します。
これはデータの75%をモデルのトレーニングに使用し、25% をテスト用に保持という意味になります。
もう一度、RUNをして、データがしっかり整形され動作するかを確認します。
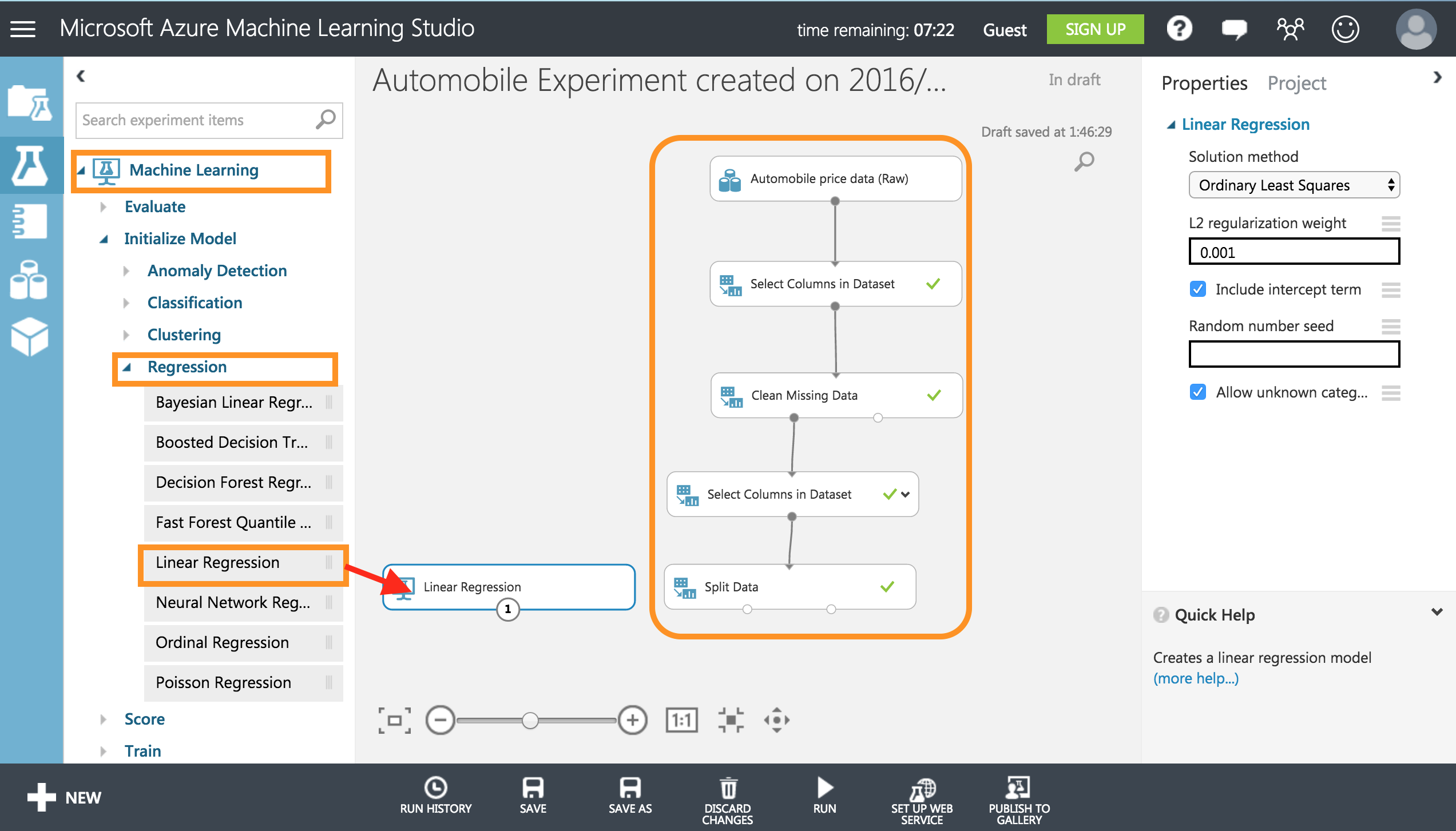
次にRUNすると左の枠に項目が表示されるので下記のように線形回帰を選択します。
どういう方式で分けるのかを選択できます。
【Machine Learning】➡︎【Regression】➡︎【Linear Regression(線形回帰)】
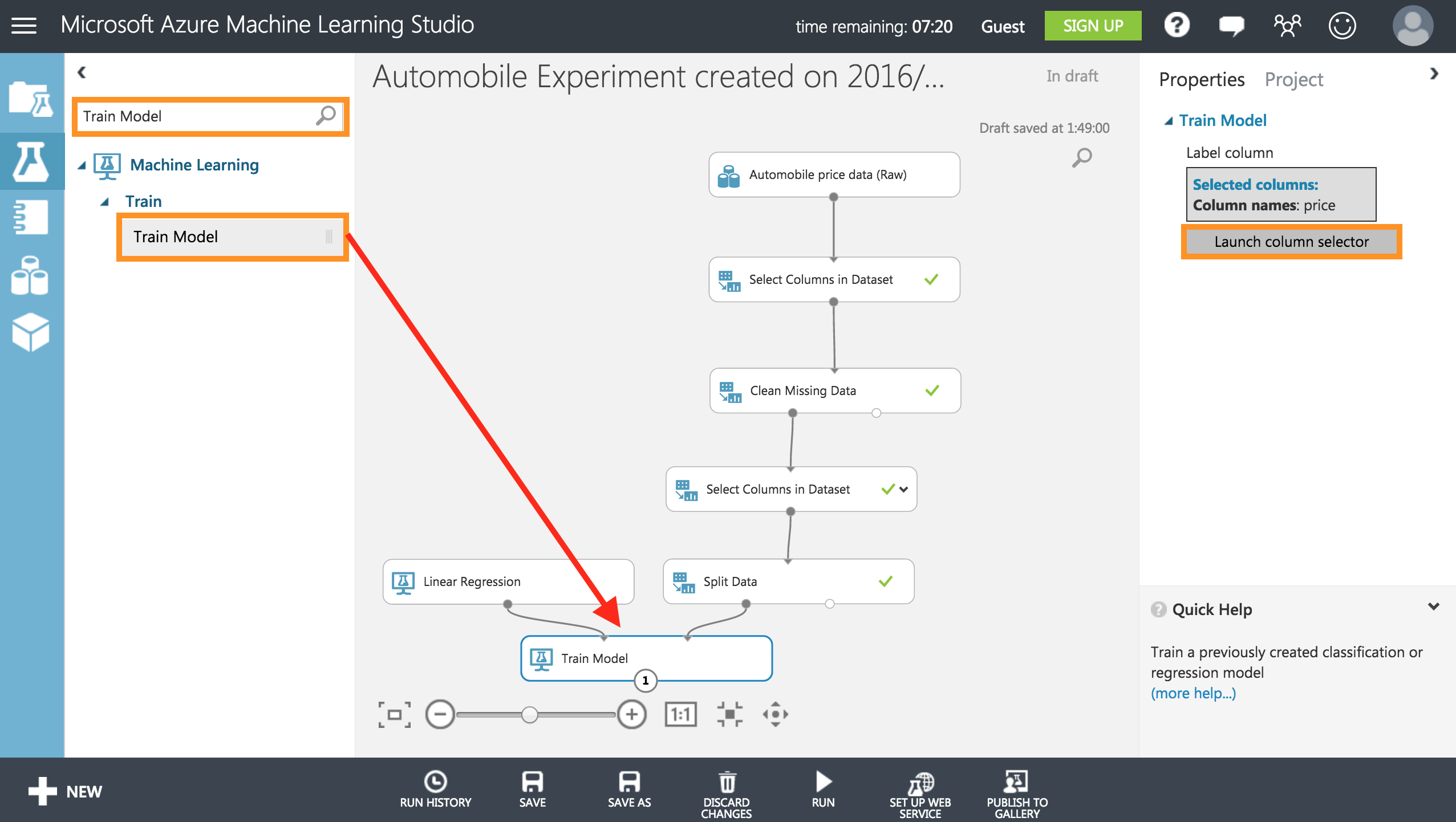
同様に左上の検索タブからTrain Modelと検索し、[Train Model]をキャンバスにドラッグし、右のプロパティーからLaunch column selectorをクリックします。
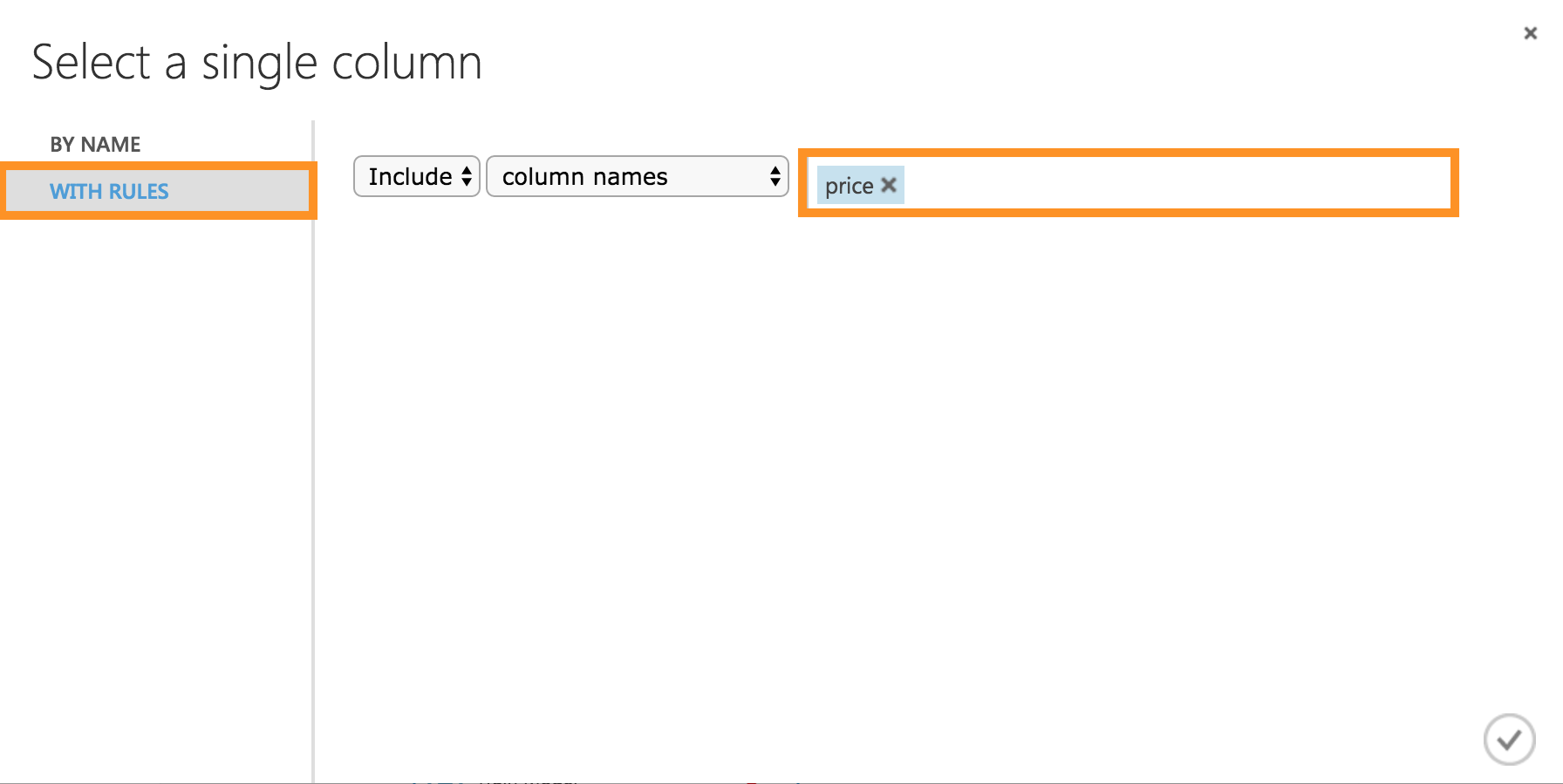
WITH RULESで[Include] [Column names] [price]を記入し追加します。
ここで行なっているのは、このモデルで予測するものになります。ここではPrice(価格)になります。
もう一度RUNすると結果として、トレーニングされた回帰モデルが作成され、新しいサンプルにスコアを付けて予測するのに使用できるようになります。
新しい自動車の価格を予測する
これまでにデータの 75% を使用してモデルをトレーニングしました。ここからは残りの 25% のデータにスコアを付け、モデルの機能の効果を確認します。
同様に左上の検索タブからScore Modelと検索し、**[Score Model]**をキャンバスにドラッグします。
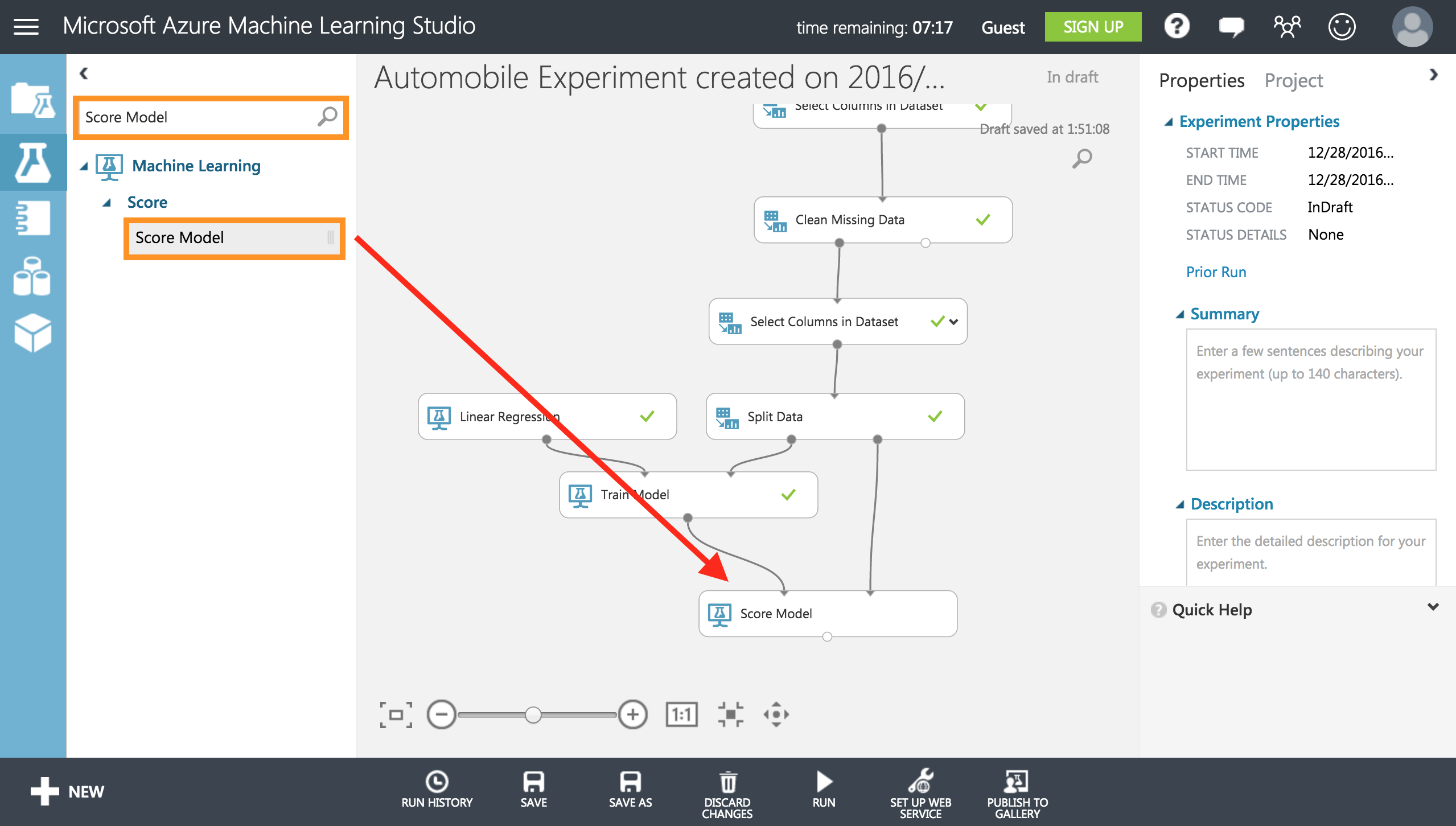
同様に左上の検索タブからEvaluate Modelと検索し、**[Evaluate Model]**をキャンバスにドラッグします。
この評価モジュール(Evaluate Model)は、2 つのモデルの比較に使用できるため、2つの入力ポートがあります。(上の二つの丸ぽち)
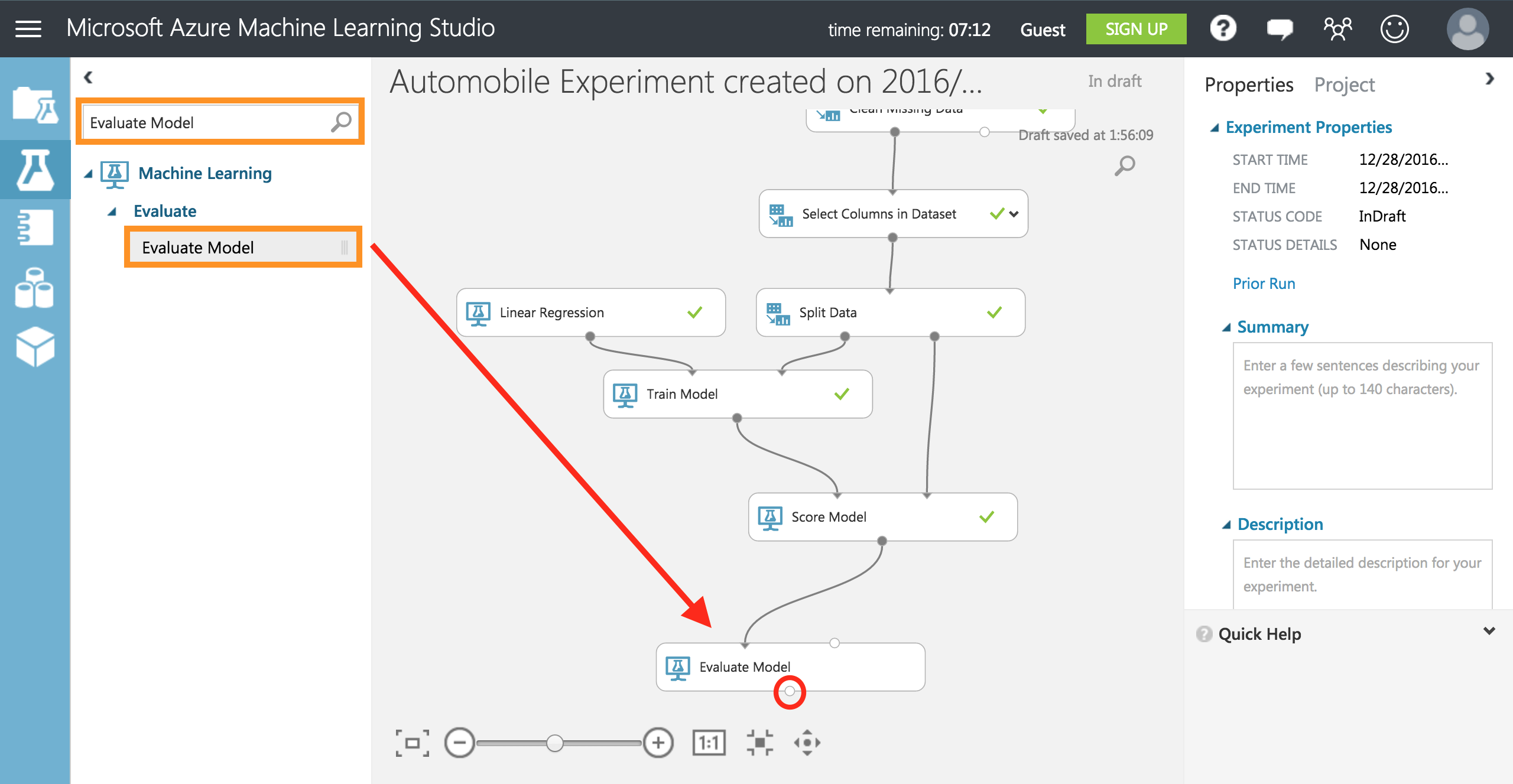
最後にRUNすると新しい自動車の価格を予測精度を確認することができます。
評価の結果は、Evaluate Modelの下の赤い丸ぽち(出力ポート)を右クリックすることで確認できます。
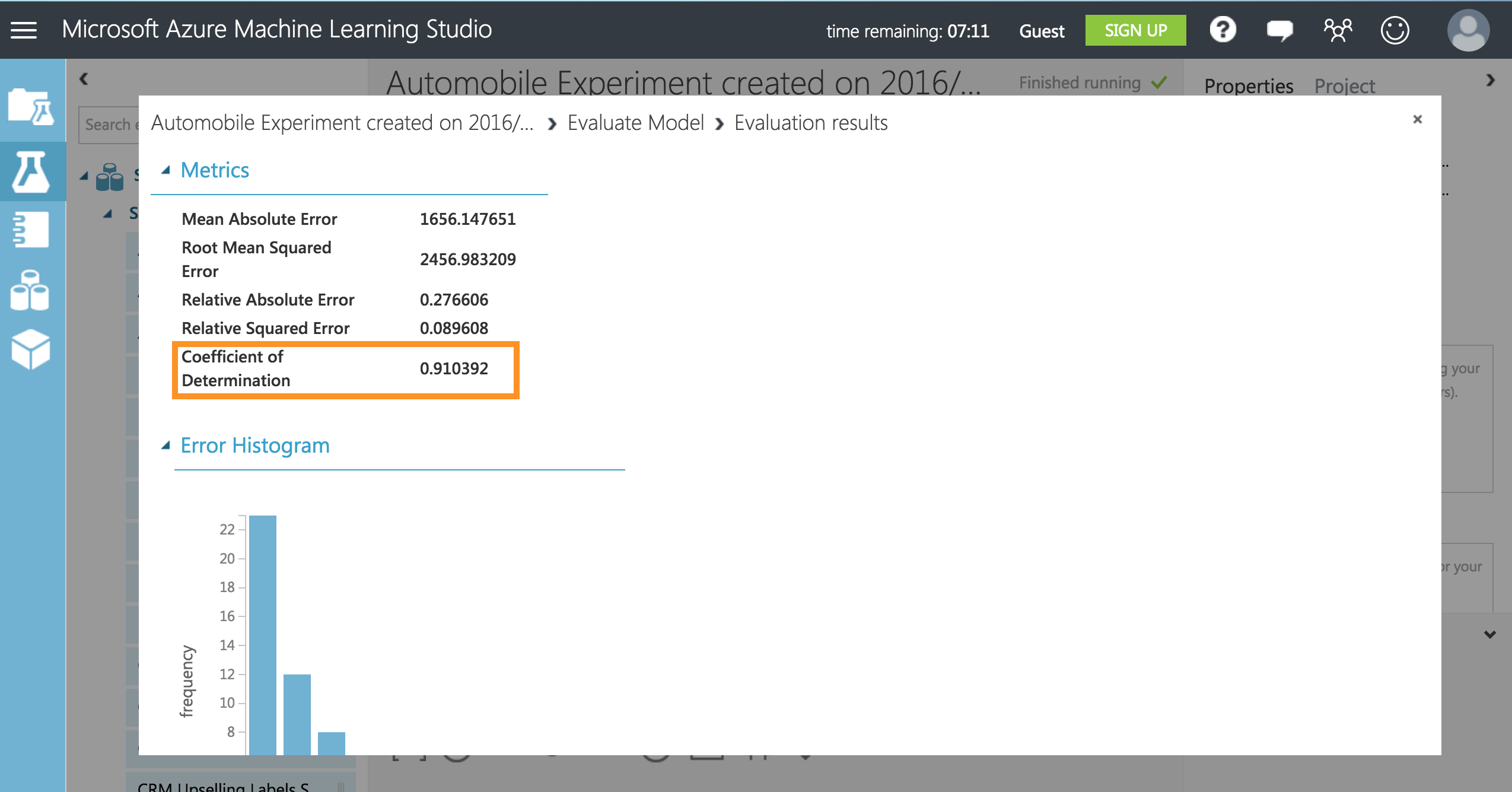
すると、Coefficient of Determinationが0.910と1.0に近い値になっているので予測が実際の値をより厳密に照合することを示します。
これが全体のチュートリアルの内容になります。
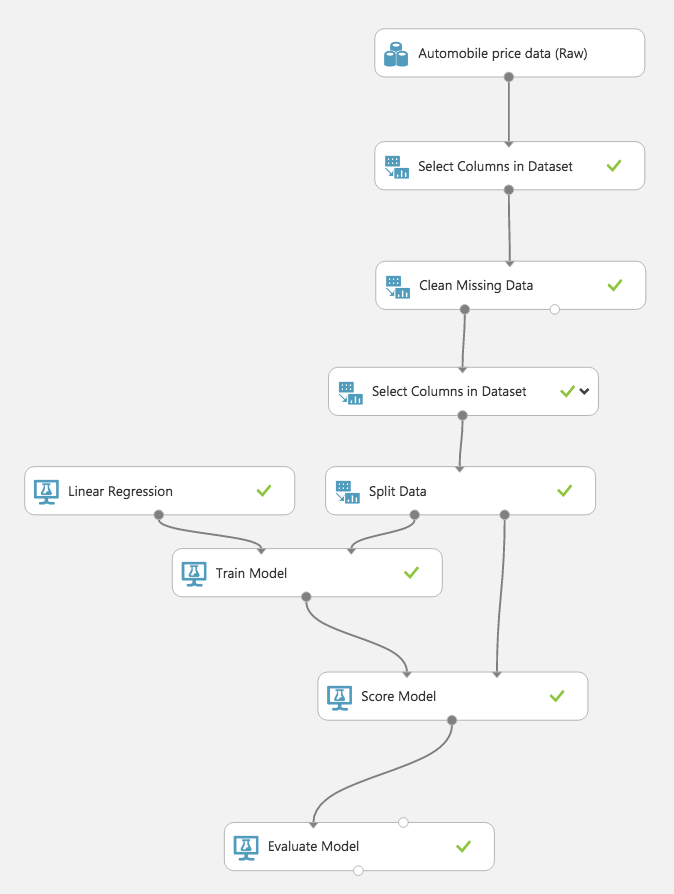
全体のキャンバス
終わりに
まずはチュートリアルをやってみたが、すごく分かりやすくて良かったです。
しかし、使いこなすのはまだまだ難しいと感じます。もう少し触って応用的なことができれば紹介したいと思います。