システムエンジニア Advent Calendar 2015 - Qiita 20日目の記事です。
システム開発をしていると、他システムのマスタやトランザクションデータが必要となる場合がよくありますね。
システム間のデータ連携としては、
- リソース共有(データベース共有、ディスク共有)
- アプリケーション連携(RPC、Web API、MOM1)
- ファイル連携(CSV連携、etc)
などの方法がありますが、ここではデータベース共有を実現するためのデータベース連携方式について考えてみたいと思います。
データベース連携方式について
既存システムがレガシーであったり、違うベンダーが構築したサーバーであるなどの理由で、新機能や拡張機能を別のサーバー上で新システムとして構築する場合があります。もちろん、データベースも新たに用意する場合が多いのですが、その場合は既存システムには極力修正をいれない方針でデータベース連携を実現しないといけなかったりします。
他システムのデータベースに更新が必要な場合は、データ整合性を理由として新システムが直接更新するのは避けたほうが賢明です2。既存システムに修正をいれない方針自体を見直したほうがいいでしょう。ただし、データ参照のみであれば、データベース連携が選択候補として上がります。
データベース連携としては、
- 直接参照
- コピー(複製)作成
の大きく分けて2通りの方法があります。
それぞれの特徴について見ていきましょう。
なお、今回の方式は他システムのデータベースへ物理的にアクセスできる環境が前提です。
直接参照する
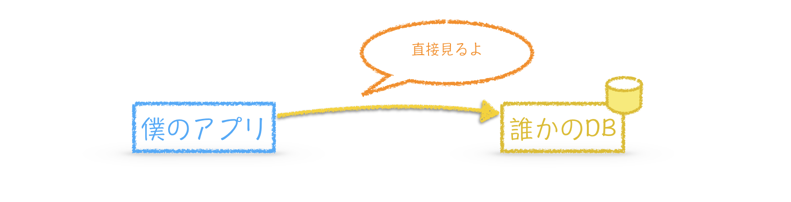
直接見ちゃいます。参照権限のみをもった接続ユーザを相手先に用意してもらいましょう。
直接参照するメリットとしては、
- 実装が容易
- リアルタイムかつ完全なデータ整合性
です。
一方でデメリットとして挙げられるのは、
- 他システムのデータベース変更の影響をもろにうける
- 接続条件により、実装上の面倒毎が増える場合がある
- 他システムの性能や稼働率に影響をうける
- 所有テーブルとテーブル結合ができない3
などがあります。
接続方法としてはJDBCなどで接続してもいいですし、同じデータベース製品であればデータベースリンクの機能が用意されていると思います。
コピーする
所有データベースにテーブルのコピー(複製)を作ります。
コピーを持つ事で、
- 他システムのデータベース変更をもろにうけない4
- 他システムデータベースの接続条件に対応しやすい
- 他システムの性能や稼働率に影響をうけない
- 所有テーブルとコピーテーブルをテーブル結合できる
と、直接参照していた場合のデメリットが解消されます。
一方で、
- リアルタイム性に乏しい。データ鮮度はコピーの間隔による
- 相手先テーブルのデータ件数が多い場合は工夫が必要
などのデメリットが出てきます。
データベース製品や他のミドルウェア製品でコピー機能が用意されていれば簡単に実現できますが5、そうでない場合は自分でコピーを実装する必要がでてきます。
全部コピーする
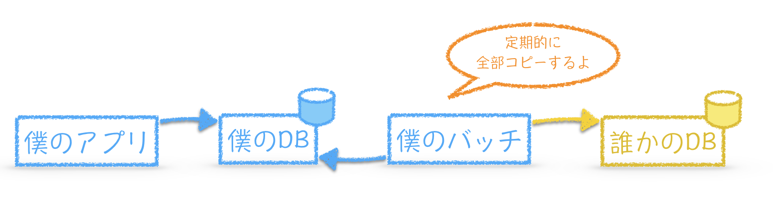
全部コピーしちゃいます。だいたい日次バッチなどでトランザクションの少ない夜間帯にコピーします。
全部コピーするメリットとしてはずばり、
- 実装が容易
です。
一方でデメリットとして挙げられるのは、
- リアルタイム性に乏しい。日次バッチの場合、データ内容は1日前のだったり。
- データ件数が多すぎる場合、性能上の理由で難しい。
です。
リアルタイム性には難がありますが、組織マスタや社員マスタ、コードマスタのような、そもそも頻繁に変わることがないようなデータであればこれで十分です。とはいえ、すぐに変更データを取り込みたい場合もあるので、日次バッチ以外でも必要に応じて任意実行できるようにしておけば運用上は問題ないでしょう。
差分をコピーする
全部コピーの場合は、リアルタイム性に問題がありました。また、コピー元テーブルのデータ件数が多すぎる場合は性能上の理由で難しい場合があります。上記課題の対応が必要な場合、差分コピーを検討しましょう。
差分コピーのメリットとしては、
- 準リアルタイム性の実現(数時間から数秒の遅れまで)。
- コピー元テーブルのデータ件数が多い場合も、差分のみコピーの為問題なし
です。一方でデメリットとしては、
- 実装が複雑になりやすい
- 実現方式により、相手先テーブルの更新性能が落ちる
- 運用上で気をつける点が増える
です。
では、よくある実現例を見ていきましょう。
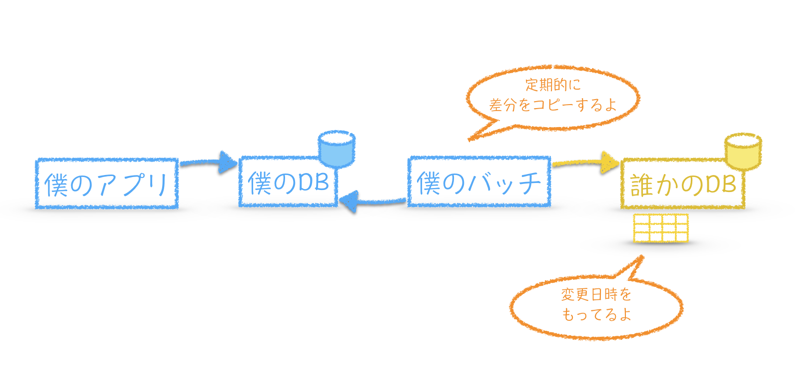
相手先テーブルに変更日時がある場合です。
良し悪しは別にして、変更日時を持った既存テーブルは多い6ので、これをもとに変更差分をコピーします。
前回コピーの実施時間を用いて、それ以降に変更のあったデータを差分としてコピーします。
相手先テーブル.変更日時 >= 前回コピー実施時間 - α
α時間を前回コピー実施時間からマイナスするのは、コピーの実行タイミングにより差分取得もれが発生しないようにする為です。
注意点としては、
- 物理削除の変更差分が認識できない7。
- 検索性能を考慮し、相手先テーブルへインデックス作成などの考慮が必要
- 変更日時が正しく設定される前提なので、その前提が崩れた変更レコードはコピーされない
もう一方は、ジャーナルテーブルを用いた方式です。
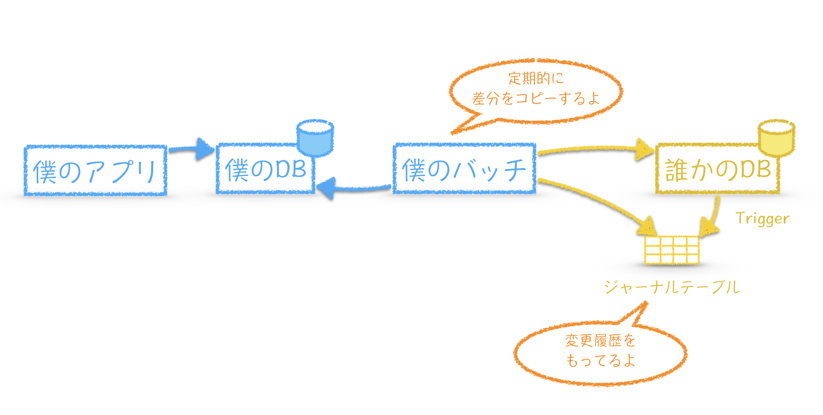
ジャーナルテーブルにコピー元テーブルの変更履歴を書き込みます。ここでは既存システムに極力修正をいれない方針として、Triggerを持ちいた方式としています。
相手先テーブルにTriggerを作成し、変更差分をジャーナルテーブルに格納します。差分コピーはそのジャーナルテーブルの内容をもとに実施します。
メリットとしては、
- 相手先テーブルに変更日時などの変更差分を把握する情報がなくてもOK
- 物理削除にも対応できる
- 変更日時の設定もれなどによる差分抽出もれが発生しない
です。
注意点としては、
- Triggerの処理により、相手先テーブルの更新性能がおちる。
- 1つのUpdate文で数百万のレコードがジャーナルテーブルに作成される可能性がある。運用や設計上で注意が必要。
です。
メリット・デメリット比較
というわけで、上記内容をもとに僕の主観でメリット・デメリット表を作成しました。
ただし、システム要件によりこの内容は変化するのでご了承ください。
| 直接参照 | 全コピー | 差分コピー | |
|---|---|---|---|
| 実現容易性 | ◯(容易) | △(普通) | X(やや高い) |
| 表の結合 | X(できない) | ◯(できる) | ◯(できる) |
| 他システム依存8 | X(高い) | ◯(低い) | ◯(低い) |
| 他システムへの影響 | ◯(低い) | ◯(低い) | △(更新性能に影響あり) |
| 大量データ | ◯(向き) | X(不向き) | ◯(向き) |
| リアルタイム性 | ◯(高い) | X(低い) | △(方式による) |
| 運用容易性 | △(普通) | ◯(簡単) | X(面倒) |
実装例
論理的な話ばかりでは面白くないので、ジャーナルテーブルを用いた差分コピーを簡単に実装してみます。
例として、他システムのデータベース(Oracle Database Express Edition)にあるユーザマスタを別データベース(JavaDB)のユーザマスタにコピーします。
コピー元テーブルの定義は次のとおりです。
create table ユーザ(
ユーザID number(20) primary key
, ユーザ名 varchar2(100)
)
ユーザテーブルのジャーナルテーブルの定義は次のとおりです。
create table ユーザ_JNL(
ID number(20)
, OPERATION char(1)
, OLD_ユーザID number(20)
, NEW_ユーザID number(20)
, CREATED date
)
OPERATIONには、
| 操作 | コード |
|---|---|
| 作成 | I |
| 更新 | U |
| 削除 | D |
のコード値が設定されます。
OLD_ユーザIDには削除や変更前のキー、NEW_ユーザIDには変更後のキーや作成したキーが設定されます。
ジャーナルテーブルのIDを生成するシーケンスの定義は次のとおりです。
create sequence ユーザ_JNL_SEQ
start with 1 increment by 1 nomaxvalue nocycle nocache
ユーザテーブルに作成するTriggerの定義は次のとおりです。
create or replace trigger ユーザ_TRGR
after delete or insert or update on ユーザ
for each row
begin
if inserting then
insert into ユーザ_JNL values(
ユーザ_JNL_SEQ.nextval
, 'I', null, :new."ユーザID", sysdate);
elsif updating then
insert into ユーザ_JNL values(
ユーザ_JNL_SEQ.nextval
, 'U', :old."ユーザID", :new."ユーザID", sysdate);
elsif deleting then
insert into ユーザ_JNL values(
ユーザ_JNL_SEQ.nextval
, 'D', :old."ユーザID", null, sysdate);
end if;
end;
ジャーナルテーブルには操作、および変更前のキーと変更後のキーしか保存しません。
同一キーに対して変更後に削除された場合などの考慮については、バッチ側で実装することにします。
ある同一キーへの操作にともなうコピー先テーブルへの操作の状態遷移は次のとおりです。
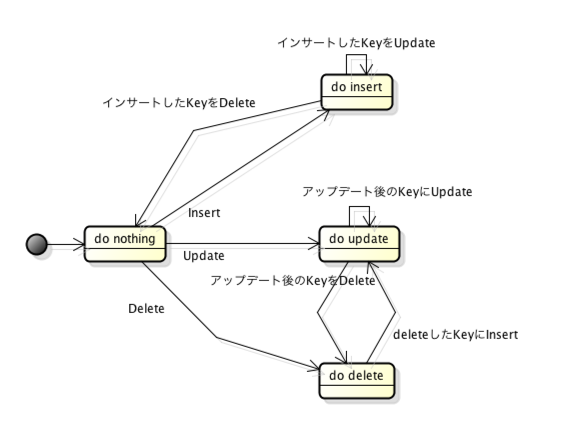
ジャーナルテーブルを読み取って、コピーを作成する機能をGradleのタスクで実装しました。タスクのスケジュール実行はJenkinsなどを用いて容易に実現できますね!
import groovy.sql.Sql
configurations {
driver
}
dependencies {
driver fileTree(
dir: 'libs'
, include: ['ojdbc6.jar', 'orai18n.jar']
)
driver fileTree(
dir: 'C:\\Program Files\\Java\\jdk1.8.0_25\\db\\lib'
, include: ['derby.jar']
)
}
configurations.driver.each {
GroovyObject.class.classLoader.addURL(it.toURL())
}
def connectFrom() {
Sql.newInstance(
'jdbc:oracle:thin:@127.0.0.1:1521:xe'
, 'hoge'
, 'hoge'
, 'oracle.jdbc.driver.OracleDriver')
}
def connectTo() {
Sql.newInstance(
'jdbc:derby:C:\\javadb\\db\\;create=true'
, 'hoge'
, 'hoge'
, 'org.apache.derby.jdbc.EmbeddedDriver')
}
task makedb << {
def sqlTo = connectTo()
sqlTo.execute """
create table ユーザ(
ユーザID bigint primary key,
ユーザ名 varchar(100)
)
"""
}
task selectdb << {
def sqlTo = connectTo()
sqlTo.rows("select * from ユーザ").each {
println it
}
}
task dbcopy << {
def sqlFrom = connectFrom()
def sqlTo = connectTo()
def jnls = sqlFrom.rows(
'SELECT * FROM ユーザ_JNL order by ID')
if (jnls.size == 0) {
return
}
sqlTo.withTransaction {
collect(jnls).each {
if (it.operation == "D" || it.operation == "U") {
sqlTo.execute(
'DELETE FROM ユーザ WHERE ユーザID=?',
[it.OLD_ユーザID]
)
}
if (it.operation == "I" || it.operation == "U") {
def user = sqlFrom.firstRow(
'SELECT * FROM ユーザ WHERE ユーザID=?',
[it.NEW_ユーザID])
if (user != null) {
sqlTo.execute(
'INSERT INTO ユーザ VALUES(?, ?)',
[user.ユーザID, user.ユーザ名])
}
}
}
sqlTo.commit()
}
sqlFrom.execute(
'DELETE FROM ユーザ_JNL WHERE ID <= ?',
[jnls.last().ID])
}
def collect(jnls) {
jnls.inject([]) { ac, jnl ->
def findJnl = ac.find {
def targetKey = jnl.OPERATION == "I" ?
jnl.NEW_ユーザID : jnl.OLD_ユーザID
(it.NEW_ユーザID ?: it.OLD_ユーザID) == targetKey
}
if (findJnl != null) {
if (findJnl.OPERATION == "I") {
if (jnl.OPERATION == "U") {
jnl.OPERATION = "I"
jnl.OLD_ユーザID = null
} else if (jnl.OPERATION == "D") {
ac.remove(findJnl)
return
}
} else if (findJnl.OPERATION == "U") {
if (jnl.OPERATION == "U") {
jnl.OLD_ユーザID = findJnl.OLD_ユーザID
} else if (jnl.OPERATION == "D") {
jnl.OPERATION = "D"
jnl.OLD_ユーザID = findJnl.OLD_ユーザID
}
} else if (findJnl.OPERATION == "D") {
if (jnl.OPERATION == "I") {
jnl.OPERATION = "U"
jnl.OLD_ユーザID = findJnl.OLD_ユーザID
}
}
ac.remove(findJnl)
}
ac.add(jnl)
ac
}
}
dbcopyタスクでジャーナルテーブルを読み取って差分をコピーします。同一キーに対する操作の状態遷移に対する"おまとめ処理"は、collect関数で実現しています。
まだまだ業務レベルの品質9ではありませんが、そこそこ動くものができました。
まとめ
今回のジャーナルテーブルを用いた連携方式では、1分くらい間隔でタスク実行する前提を考えて作成しました。それ以上のデータ鮮度が必要な場合は、コピー元に変更が入った直後に変更を通知する仕組みが必要ですね。
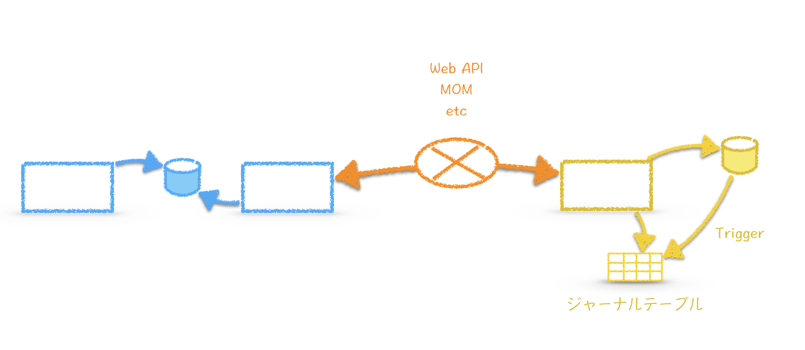
このようなケースでは、かわしまさんの以下の記事を参考に実装すればいいかと思います10!
また、システム連携はステークホルダとの連携がなによりも重要です。人間がきちんと連携できないとシステムも連携出来なくなりますのでw
日頃からみなさんも、適切なコミュニケーション連携を心がけましょう〜11
-
Message Oriented Middleware) ↩
-
その場合はアプリケーション連携やファイル連携が候補としてあがります。 ↩
-
データベースリンク機能を用いれば可能ですが、性能面での注意が必要です ↩
-
バッチ実行が失敗するのみ ↩
-
例えばOracleの場合だと、マテリアライズド・ビューなどを用いて実現できます。 ↩
-
イミュータブルデータモデルのdisでは断じてありませんのでw!! ↩
-
論理削除の場合は問題ない
です。 ↩ -
性能や可用性など ↩
-
性能面、複数データベースにまたがったトランザクションにおける障害対応などが考慮不足 ↩
-
丸投げではない、コラボだ! ↩
-
え、おまえがいうな?あー、あー、聞こえないw! ↩