はじめに
python tensorflowの初学者です。
QiitaにTitanicのデータにskitlearnを適用した記事に触発され、tensorflowを適用するとどうなるのかを試しましたので投稿します。
環境
OS : Windows10
Python : 3.5(Pandas,Numpyもインストール済み)
tesorflow : 1.0
データの整理
データはKaggleからダウンロードしてください。(http://www.kaggle.com/c/titanic)
簡単にデータの仕様を説明します。
PassengerId : kaggleが割り振った個人に割り振ったID
Survived : 生存・非生存(予測対象)
Pclass : 客室のクラスを表すコード1は1等、2は2等、3は3等
Name : 名前
Sex : 性別
Age : 年齢
SibSp : 同行した兄弟または配偶者の人数
Parch : 同行した親または子どもの人数
Ticket : チケット番号
Fare : 料金
Cabin : キャビン番号
Embarked : 乗船した港
Survivedを軸に集計を行い、影響のありそうなものを選定した結果、Pclass,Sex,Age,SibSp,Parch,Fareを特徴量としました。年齢は子どもと高齢者の生存の割合が高いので、カテゴリー化しました。Embarkedも影響があるようですが、Pclassと相関が高かったので除外しました。
以下にコードを示します。
# データを読み込み、必要なものだけを取り出す
row_data = pd.read_csv('train.csv')
data= row_data[['Survived','Pclass','Sex','Age','SibSp','Parch','Fare']].dropna()
#カテゴリーデータをダミー変数に変換し、使用するものだけにする
Pclass = pd.get_dummies(data['Pclass'])
Pclass.columns=['1st','2nd','3rd']
Pclass = Pclass.drop('1st',axis=1)
Sex = pd.get_dummies(data['Sex'])
Sex = Sex.drop('male',axis=1)
# Ageをカテゴリーデータに変換
def adult_kids(age):
if age > 15:
if age > 60:
return 'older'
else :
return 'adult'
else :
if age < 16:
return 'kids'
else :
return np.nan
data['adult_kids'] = data['Age'].apply(adult_kids)
Age_cat = pd.get_dummies(data['adult_kids']).drop('adult',axis=1)
Data_tmp = data[['Survived','SibSp','Parch','Fare']]
Merge_data = pd.merge(Data_tmp,Pclass,right_index=True,left_index=True)
Merge_data = pd.merge(Merge_data,Sex,right_index=True,left_index=True)
Merge_data = pd.merge(Merge_data,Age_cat,right_index=True,left_index=True)
y = Merge_data['Survived'].as_matrix()
x = Merge_data.drop('Survived',axis=1).as_matrix()
カテゴリーデータはダミー変数に置き換えています。また、欠損値があるものは除外しました。
モデルの作成
最初に作成したモデルは、特徴量8個に対してラベル1個(0または1)を全結合するものから始めます。隠れ層はこの後のチューニングで手を付けることにします。
tensorflowのコードは、大別すると、「モデル定義」、「学習準備」、「学習」の3つのブロックに分かれます。最初にモデルの定義です。
# 変数の定義
feature = tf.placeholder(tf.float32, [None, 8])
label = tf.placeholder(tf.float32, [None, 1])
w0 = tf.Variable(tf.zeros([8, 1]))
b0 = tf.Variable(tf.zeros([1]))
# モデルの定義
f0 = tf.matmul(feature, w0) + b0
p0 = tf.sigmoid(f0)
モデルの定義は、変数の定義とモデル本体の定義で構成されます。tensorflowのアーキテクチャーは一種の関数を定義して学習のブロックでまとめて実行というイメージなので、このモデルに必要な関数をいろいろと定義する必要があります。placeholderは、学習実行のブロックで外から与える変数の定義です。ここでは8個の特徴量と1個のラベルが相当します。いずれもtensorなので、行と列の定義が必要となります。
重み(w0)とバイアス(b0)はtensorflow内で更新されるデータとしてVariableで定義します。重みとバイアスは初期値がないと処理できないのでzerosで定義しました。
モデルの本体は、ニューラルネットワークの基本の計算式をそのままあてています。一応、入力層から出力層に信号が伝達される部分(f0 = tf.matmul(feature, w0) + b0)と出力層からのアウトプット部分(p0 = tf.sigmoid(f0))を分けて記述しました。
続いて学習の準備です。
loss = -tf.reduce_sum(label*tf.log(p0) + (1-label)*tf.log(1-p0)) # 損失関数
train_step = tf.train.AdamOptimizer().minimize(loss) # 最適化手法
# 初期設定
sess = tf.Session()
sess.run(tf.global_variables_initializer())
学習とは、モデルのアウトプットとラベルの相違を損失関数を使って評価し、損失関数が最小になるように重みとバイアスを調整することを示します。そこで、最初に損失関数を定義します。2クラス分類の関数をそのまま使用しています。クロスエントロピー誤差の応用です。応用というのは、2クラス分類固有のテクニックが含まれているという意味です。モデルの出力結果は0~1の数値であり、0.5を基準にそれより大きければ1、小さければ0と判定することになります。一方、ラベルは0または1なので、0の場合は0と出力結果の比較となり、1の場合は1との比較になります。仮にモデルのアウトプットが0.8でラベルが1の場合は、1との比較なので0.2ですが、ラベルが0なら0.8ということになります。このあたりを1つの関数で表現するとlabel*tf.log(p0) + (1-label)*tf.log(1-p0)というものになっています。
次に最適化手法を定義します。いくつかの方法がありますが、Adamを使うことにしました。最後に初期設定をします。初期設定は先のモデルの定義において設定した初期値を実際に設定する処理です。初めにtf.session()でモデルの定義のブロックで定義した一連のモデル式をsessという名称で実行することを宣言します。その後にメソッドを定義して処理を行います。初期化はtf.global_variable_initializerによって行います。旧バージョンと関数が異なっているので注意してください。
いよいよ学習です。
result_data = np.zeros([500,3])
i = 0
for _ in range(5000):
i += 1
sess.run(train_step, feed_dict={feature : x, label:y}) # 学習処理
if i % 10 == 0:
loss_val = sess.run(loss, feed_dict={feature:x, label:y})
predict = sess.run(p0 , feed_dict={feature:x , label : y})
pre_label = [0 if x<0.5 else 1 for x in predict]
acc_val = metrics.accuracy_score(pre_label,data['Survived']) # 予測結果の評価
result_data[(i/10)-1]=[i*10,loss_val,acc_val]
print ('Step: %d, Loss: %f, Accuracy: %f'
% (i, loss_val, acc_val))
学習だけなら、sess.run(train_step,feed_dict{feature : x , label :y})だけで問題ありません。他のコードをデバックの意味もあって追加したものです。本来であればtensorboardで行うべきことかもしれません。
モデルの評価
損失関数が収束していることを示すグラフです。
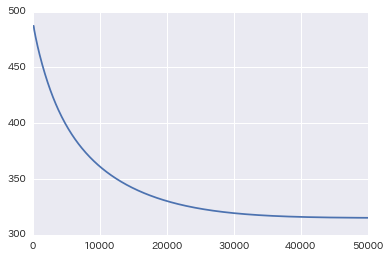
再現率が学習を重ねるごとに上がっています。
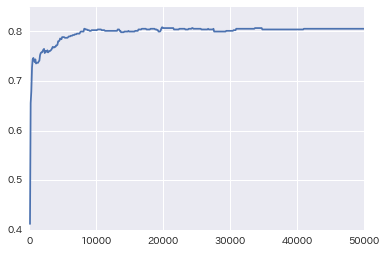
うまく学習が進んだようです。再現率からすると、10000回くらいで上限に達しています。再現率は80.5%でした。社会科学系なら結構高いものです。できれば、85%~90%を目指したいところです。比較のためにskit-learnのロジスティック回帰で同じことを行いました。
log_model = LogisticRegression()
# モデル作成
log_model.fit(x,y)
# 予測
predict=log_model.predict(x)
再現率を算出したところ、80.7%とほぼ同じです。念のため、両者の予測結果同士を比較したところ99.6%が一致しました。データ件数が714件なので不一致は4~5件というところでしょうか。
とりあえず、今回はここまでとします。
続いてモデルのチューニングを行います。果たして隠れ層を追加して再現率はどこまであがるのでしょうか?