はじめに
以下サイトでTwitterのソーシャルグラフが配布されている。
♯ 103万人分、2.8億エッジという驚愕の規模
http://d.hatena.ne.jp/code46/20110130/p1
今回、このデータを題材としたコミュニティ抽出のプログラムを書いたので、開発過程のいろいろをまとめておく。
一部、Amazon Elastic MapReduceでの分散処理などもやってみたので、MapReduceやCloudに興味を持つ人にも利益があるかもしれない。特に、実アプリ開発を題材とした事例紹介はWeb上でも少ないようなので、そういった位置づけでは価値があるのではないかと思う。
ソーシャルグラフ、コミュニティ抽出(≒クラスタリング?)の概要については以下が分かりやすい。
http://www.slideshare.net/komiyaatsushi/newman-6670300
実は、以前はてなブックマークを題材にコミュニティ抽出を行った経験がある。
その時のあれこれについては以下を参照。
http://www.slideshare.net/rawwell/sbm-presentation
開発の概要
(当初考えていた) 外部仕様
Twitterユーザを指定(1ユーザ)すると、その周囲に存在するコミュニティを抽出しグラフィカルに提示する。
利用時、プログラム使用者は抽出するユーザ数を指定する。
♯ 何らかの指標に基づき、自動で抽出ユーザ数を決定することもできるはずだが今回はそこまで頑張らない
開発環境
開発機(兼計算用マシン): AMD Phenom Ⅱ X4 945 Processor 3.00 GHz, 4GB Memory
開発言語: Java (1.60_24)
グラフ可視化
本レポートではクラスタリング処理の実装を中心に述べるが、結果の良し悪しを判断したり、それを人に提示するためには可視化が必要である。
そこで、今回はJUNG ( http://jung.sourceforge.net/ ) を利用して可視化を行う。JUNG は Java Universal Network/Graph framework の略記である。
以下に、JUNGによる可視化のデモが置いてある。
http://jung.sourceforge.net/applet/index.html
デモのソースコードは以下にある。
以降では、LensDemo.java に少し修正を加えたコードを用いて可視化を行った。
以下のような出力が得られる。
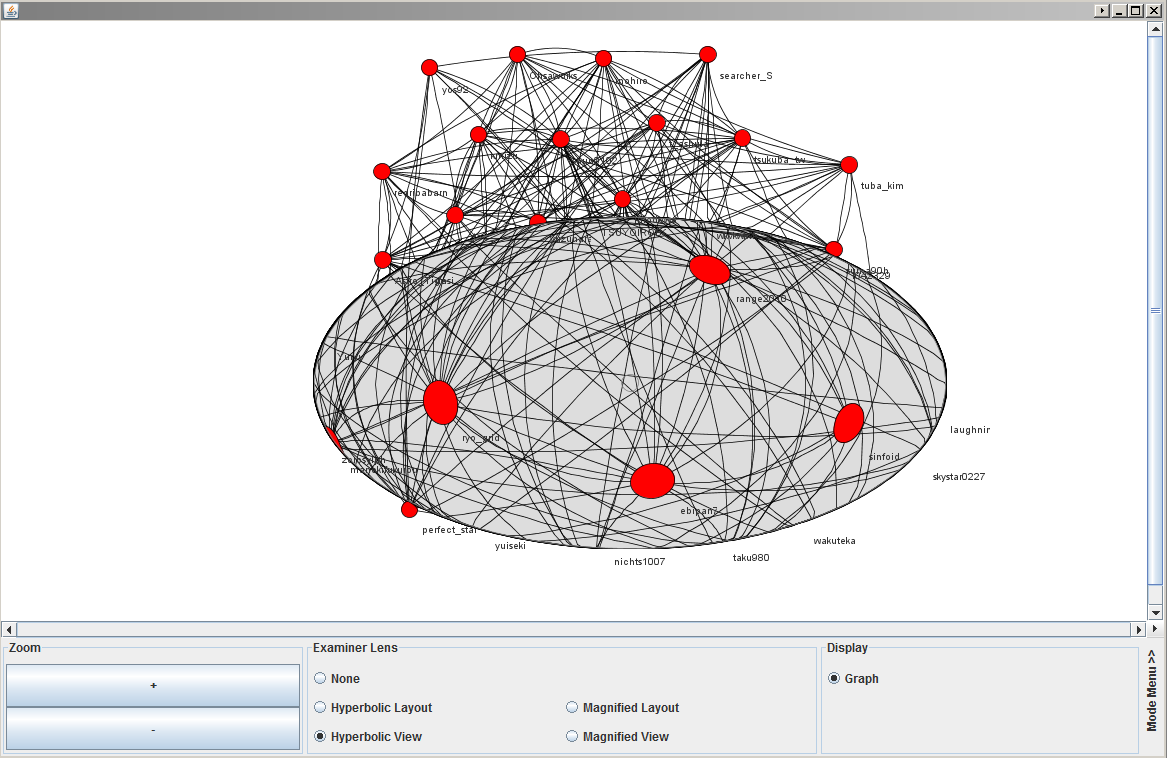
♯ 灰色の楕円はグラフの接続関係を拡大して見るためのレンズ(虫眼鏡)。これのおかげでびっしり詰まったグラフでも何とかなる。
♯ 上記の出力例では、レンズ内の一番左に私 ( ryo_grid ) がいる。
使用データ
配布データをMongoDBにロードし、下のスクリプトでCSV形式のデータを作成。
♯ 提供されているデータにはfollowing以外の情報も含まれるが、今回はコミュニティ抽出だけ出来れば良いため除外する。
http://ryogrid.net/~ryo/dist/tw_community/make_social_graph_csv.rb
http://ryogrid.net/~ryo/dist/tw_community/make_id_x_screen_name_table.rb
事前にRubyからMongoDBにアクセスするためのライブラリをインストールしておく。
gem install mongo
gem install bson_ext
適当なファイルに実行結果をリダイレクト。
$ ruby make_social_graph_csv.rb > follow_ids_table.csv
$ ruby make_id_x_screen_name_table.rb id_x_screen_name_table.csv
生成されるデータは以下の2つ。
■1.ユーザ間のフォローイングデータ( ユーザはinternal_idで表現 )
[ユーザID],[followしているユーザのID(1)],[followしているユーザのID(2)], ・・・・・・
・・・・・ 同じ形式のデータがユーザ数分だけ並ぶ ・・・・・・
■2.internal_id と screen_name の変換テーブル
[internal_id],[screen_name]
・・・・・ 同じ形式のデータがユーザ数分だけ並ぶ ・・・・・・
internal_idはユーザを識別するためのIDであり整数値で表現される。
マイニング処理中はこちらを使ってユーザの識別を行う。
screen_nameはTwitter上でのユーザ名。
私の場合、”ryo_grid”となる。
使用アルゴリズム
最初は下の論文のアルゴリズムを試していたが、Twitterのネットワークとは相性が良くないらしく、うまく抽出が行えなかった(ここらへんの話は以降のレポートでは省略)。
♯ 下のアルゴリズムは特定のコミュニティのみと接続を持つようなユーザを中心にコミュニティを抽出するため、
♯ あまり親交の無い人ともやたらとfollowし合うTwitterではうまく働かないということのようだ。
♯ 実装方法が誤っていた可能性も、もちろんある
http://www.cs.unm.edu/~moore/tr/05-02/local_communities.pdf
このため、今回もはてブまわりの人で考案した(?)オレオレアルゴリズムを使用することにした。
http://ryogrid.net/~ryo/dist/tw_community/oreore_algorithm.pdf
開発の足取り - コア処理 -
課題(1) : メモリにデータが収まらない
接続行列を空間効率良く格納するために、HashMapを入れ子にした簡単な疎行列クラスを作成。
各要素は内部的には以下のように取得される。
Integer val = (Integer) (((HashMap) root_map.get(i)).get(j))
これに、単純に全エッジ(2.8億エッジ)を読み込もうとしたが、開発機に搭載されている4GBメモリでは読み込むことができなかった。
♯ 圧縮表現で詰め込めば可能であったと思われる。
♯ colt (http://acs.lbl.gov/software/colt/) 等の疎行列を省メモリで扱える(?)ライブラリを使用する等
仕方がないので、疎行列クラスを拡張して、必要なデータだけをオンデマンドでファイルから読み込むようにした。アルゴリズムのロジックも実装して、”一応” 動く コミュニティ抽出プログラムが出来た。
しかし、実行結果を見る限り未だ正しく抽出が行えていなかった。少なくとも、自身の周りに存在する既知のコミュニティは抽出できていなかったので、うまくいっていないと判断した。
そこで、ユーザの選択過程や、抽出結果から問題点を明らかにし、続く改善を行った。
課題(2) : 最初に選択するユーザの問題
ユーザの選択過程を確認したところ、最終的に抽出されるユーザ群が初期ユーザのすぐ後に選択されたユーザ群(5人程度)による影響を大きく受けていることが分かった。
♯ 今回の使用アルゴリズムは選択済みユーザ集合との接続関係に基づき1ユーザずつ選択していく
そこで、初期指定ユーザを1ユーザのみでなく、任意の数指定できるようにした。 これにより、ある程度意図した抽出結果が得られるようになった。
♯ これはつまり、利用者がコミュニティ抽出の方向性を事前に行わなければうまくいかない(意図したコミュニティが抽出されない可能性が高い)ことを意味する。
♯ また、今回のアルゴリズムだけでは、指定されたユーザが複数コミュニティに所属した場合にうまく抽出が行えないということでもある。
♯ これは、最初に抽出されたコミュニティに属すユーザの声に、初期ユーザの声がかき消されてしまうために起きる。
課題(3): 片思いのエッジが邪魔をする
抽出結果を見ると、初期ユーザやその周囲のユーザと親交が深いとは思えない著名ユーザ(≒有名人)が抽出されていたが、この原因が入力するデータセットに含まれる一方的なfollow(=片思い)によるエッジであることはあきらかであった。使用アルゴリズムは抽出済のユーザ集合と一番多く接続を持つエッジを選択するため、著名なユーザがいれば真っ先に選択されてしまう。そして、そのようなユーザが抽出されると、本来は存在しない”声”により、抽出されるユーザがだんだんとズレていってしまう。
そこで、入力するデータセットから片思いのエッジを除去することにしたが、この作業が大変だったのである・・・・・。
開発の足取り - 片思いのエッジ除去 (シングルノード編) -
失敗(0): アプリ内で相互Followをチェックする
上では、データセットから取り除くことにしたと書いたが、その前にあらかじめ取り除いておかないとどうなるか書く。
片思いエッジが含まれていても、それらをプログラム中で使用しないようにすれば、結果的には事前に取り除いた場合と同様の マイニング結果が得られる。具体的には、エッジを参照する度に両想いであるかをチェックすれば良く、 例えば、”ユーザA ⇔ ユーザB” を確認する場合は、”ユーザA ⇒ ユーザB” と “ユーザB ⇒ ユーザA” が 成立するかを確認すれば良い。 しかし、これを実際に実装してみると、チェック無しの場合 (=片思いエッジを除外しない場合) に数秒で完了していた 抽出処理に数十分を要するようになってしまった。
なぜ、これほどの大きな性能劣化が起きるかを理解するためには、接続行列アクセス時に背後で行われるファイルアクセスの理解が必要となる。今回のプログラムでは、”課題(1): メモリにデータが収まらない” のところで説明したように、 接続行列は必要になった契機でファイルからメモリ上にロードされる。 ロード処理はエッジの始点となるユーザ毎にまとめて行われ、 “ユーザA → ユーザB” の接続へのアクセスが契機の場合でも、ユーザAが フォローする他のエッジ ( “ユーザA → ユーザ[?]” ) もまとめてロード (メモリ上にキャッシュ) する。
♯ 今回のアルゴリズムによるアクセスパターンを意識した作り
♯ “ユーザ[?]” は “ユーザA” がフォローしているユーザの一人に置き換えられる。
一方、今回のアルゴリズムで主要なエッジの参照パターンは、あるユーザがフォローしているユーザを舐めるというものである。例えば、ユーザA を起点とした場合では、 (“ユーザA → ユーザ[?]”) のエッジを順に処理していく。 この処理に対応するファイルアクセスを考えると、 両思いチェック無しの場合では、一回のロード処理 ( 上記で説明したひとまとめ ) で済む。この時、”ユーザ間のフォローイングデータ”のファイルは、起点となるユーザでまとまっている ( 起点ユーザが同一のエッジは 連続に並んでいる ) ため、ファイルアクセスは連続の領域をシーケンシャルに一回読み込むだけになる。対して両思いチェックを行う場合では、各 ( “ユーザA” → ユーザ[?]” ) について、逆方向の ( “ユーザ[?] → ユーザA”) の エッジが存在するかチェックを行う必要があるので、ロード処理は “ユーザ[?]” の数だけ余分に行われることになり、 “ユーザ[?]“の数とほぼ同じ (キャッシュされていたものは不要) だけのファイルアクセスが発生する。当然の帰結として、ファイルアクセスの増加分だけ性能が劣化する。 また、今回のケースでは、ファイル中のデータ領域が異なる起点ユーザでは分散しており、アクセスパターンが完全ランダム ( 一方向に進んでいくとかでもない ) となるため、性能へのインパクトはさらに大きくなっていたようであった。
ここで考えた。 ファイルから読み込むデータ量はたかが知れており、仮にシーケンシャルに読み込めたとしたらこれほど大きな性能劣化は起きないはず。 読み込みのコードでもさほど複雑な処理は行なっておらず、ここのオーバヘッドが効いているとも思えない (起動時にファイルの先頭から全てメモリ上に載せようとした時はそこまで時間はかかっていなかったし)。 とすると、ファイルへのランダムアクセスが悪いはず ( 今回、ファイルはHDD上に配置。HDDだとヘッドの移動コストのためにランダムアクセス遅い)。 であれば、ファイルを高速にランダムアクセス可能な媒体の上に配置すれば性能劣化を抑えられるはず。
ということで、以下を用いて作成したRAMDISK ( メモリ上に仮想的なディスクを作成 ) 上に、データを配置するようにしてみた。
”BUFFALO RAMDISK ユーティリティー”
http://www.forest.impress.co.jp/lib/sys/hardcust/virtualdrv/buffaloramd.html
しかし、性能劣化はほとんど軽減されなかった。
ランダムアクセスが性能劣化の主たる要因であるとという予想が誤っていたか、 BUFFALO RAMDISK ユーティリティーの実装がイマイチだったのかのどちらかなのだろうが、本当のところは現状不明。検証してみたかったが、今回は続く作業に進んだ。
失敗(1): MongoDBで頑張る(1)
%MongoDBへのクエリを駆使して相互Followをチェック
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
失敗(2): MongoDBで頑張る(2)
%グラフをバラバラに分解したテーブルを作って集計 with MongoDB
%1つのNodeを探しにいくのは一回で良い
%結局うまくいかず(遅すぎた)。データがメモリ上にのりきらなかったのが原因?
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
成功(1): パイプによるなんちゃってMapReduce
% noradaiko氏からMapReduceすればとの鶴の声
% MapReduceでの処理方法を考えた。で、考えた処理はパイプを使った簡単な枠組みでも実現できることに気付いたのでやってみた。
cat エッジ群のデータ.txt | sort -n | 2つ同じのが並んでたら残す.rb > result.txt
ノードのデータは A->B という接続関係が並んだデータ。左項は右項より大きくなるように処理しておく。
するとペアの片思いエッジが元々2つあった場合、sortによって同じ行が2つ並ぶことになる。
あとは重複を排除すれば出来上がり。
Linuxのパイプは良くできていて、データが巨大でメモリに乗らなくてもファイルに書き出して処理してくれる。
(sortコマンドは巨大なデータを扱うが問題なく動く)
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
開発の足取り - 片思いのエッジ除去 (Amazon Elastic Mapreduceで分散処理編) -
成功(1): Webコンソールで投げてみる
% やった。
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
準備: バッチ処理用AWS CUIツールの導入
% やった。
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
成功(2): CUIツールでバッチ自動化 - 無理やりやってみる -
%やった。
%が、クラスタ外とのムダな転送あり。
%中間データの作成をHadoopクラスタ内で完結できるよう改善したい。
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
成功(3): CUIツールでバッチ自動化 - もっとエレガントに -
%まだやれてない(爆)
%nokuno氏に教えてもらった記述方法を使ってデータ転送を効率化してやってみる
% - https://twitter.com/ryo_grid/status/74710797430960128
% - https://twitter.com/nokuno/status/74710955757547520
%(要)書いたコードの説明
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
EMR分散処理の評価
%(要) ラップトップでの実行時間
%(要) EMRでの実行時間
%(要) Hadoopクラスタの起動時間
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
Future Work
% 特に何も考えていない
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ
ああああああああああああああああああああああああああああああ