どうも、オリィ研究所(https://orylab.com) の ryo_grid こと神林です。
今回は顔文字をベクトル表現で扱うというテーマに取り組んでみました。
いきさつ
知人がSNSで顔文字の足し算引き算というネタ(今の気持ちはこれ足すこれ、みたいな話)を書いていて、これ、word2vecならぬkaomoji2vecしたら、実際できるんじゃないか?と思ったのがきっかけ。
ちなみに
検索して分かったことですが、絵文字だと天下のプリンストン、ロンドン大学の研究者の人たちが既に論文を出しています。
今回のテーマですが、ネタと思うことなかれ、真面目な話なのです。
emoji2vec: Learning Emoji Representations from their Description
https://arxiv.org/pdf/1609.08359.pdf
実装も公開されています。
https://github.com/uclmr/emoji2vec
コーパスをどうするか
兎にも角にも、顔文字がふんだんに使われたコーパスがなければ始まりません。
そこで、Twitterの日本語コーパスとかないかなと思って探しましたがありませんでした。
うーん、困った、と思った時に見つけたのが天下の国立情報学研究所がオープンデータの取り組みとして公開しているニコ動のコメントコーパス。
コメントのデータは展開すると約200GBという圧巻のサイズ!
これならいける(情報量的に)!
というわけで、このコーパスをごにょごにょして進めることにしました。
実装を考える
まあ、ぶっちゃけ、巷に転がっている情報による手順でword2vecかければいけるんじゃないかと思ったわけです。
顔文字が単語として認識されない
しかし、そう簡単にはいきません。word2vecするためには顔文字が単語として認識されなければいけませんが、mecabなどで分かち書きする時の辞書が普通の辞書だと、顔文字がそれを構成する記号に分解されてしまいます。
形態素解析ウェブアプリUniDic-MeCab
http://www4414uj.sakura.ne.jp/Yasanichi1/unicheck/
試しに上のサイトなどで形態素解析してみると、「(^_^)」は下のようになります・・・
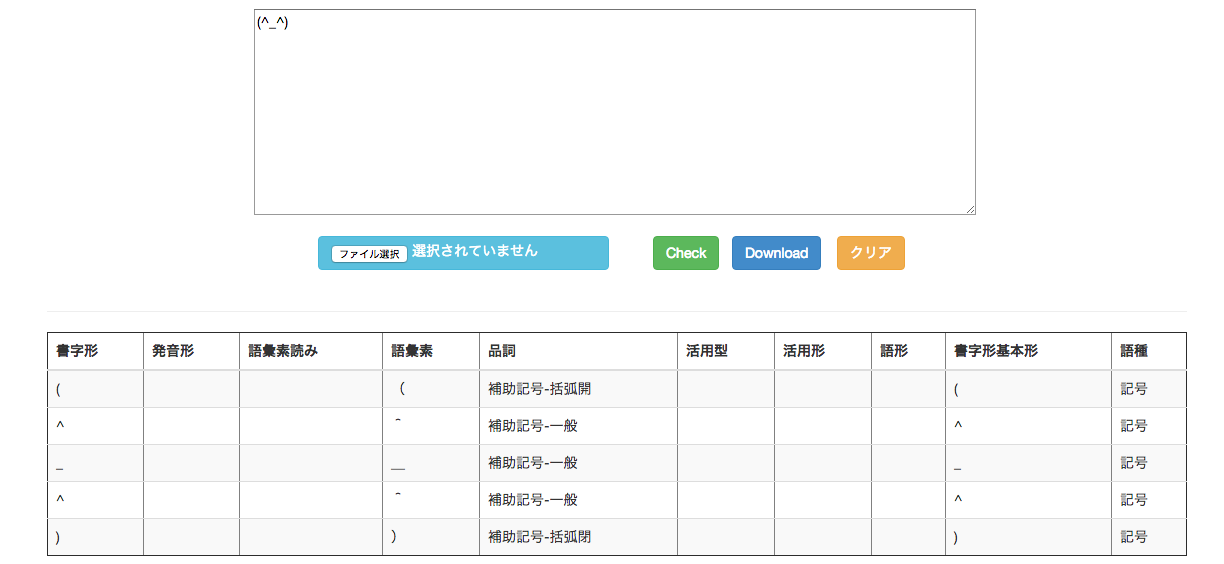
なので、顔文字が単語として登録された辞書が必要になります。
で、ipadicとかをいじって、自分でそういう辞書を作らないかな・・・と思っていた時に見つけたのがコレ。
mecab-ipadic-NEologd : Neologism dictionary for MeCab
https://github.com/neologd/mecab-ipadic-neologd
The entry data of Kaomoji strings
という記述があります!
word2vecする
というわけで、上記の辞書を使ってword2vecしていきます。
手順は以下の記事を参考にさせていただきました。ありがとうございます。
word2vec 〜 日本語wikipediaによる学習 〜
http://seiya-kumada.blogspot.jp/2016/12/word2vec-wikipedia.html
作業にあたっては、使っているマシンのディスクスペースが足りないせいで、大量のファイルに分割して圧縮されているコーパスを一つずつ展開して処理しては消したりするプログラムを書いたり、200GB近くのデータにword2vecするにはマシンスペック(メモリが足りなすぎてそもそも固まる)が足りないので、AWSで12コアとかの高性能インスタンスを使って処理をしたり(半日ぐらいで処理できたはず。確か)といろいろ苦労はありましたが、とにかくベクトルデータを作ることができました。
ニコ動コメントコーパスをコーパスとするword2vec用(?)ベクトルデータ
生成したword2vec用(?)のベクトルデータ(200次元) を以下に置いておきます。
2つに分割してあるので結合した上でご利用下さい。
結合後で約3.3GBになります。
また、このデータはニコニコデータセットの派生物になりますので、利用して得られた成果をWebや、論文に掲載する際などは、ニコニコデータセットを用いた成果である旨の記述をお願いいたします。
https://1drv.ms/u/s!AnKEofsstkSggr5r_vY-CJgzQRgeiw
https://1drv.ms/u/s!AnKEofsstkSggr5qUpP12FWv5Hh1wg
ベクトルとして扱ってみよう
やってみます。
と、その前に、word2vec的な基本的な動作がちゃんと行われるか、「厨房」というワードの類似語を検索してみます。
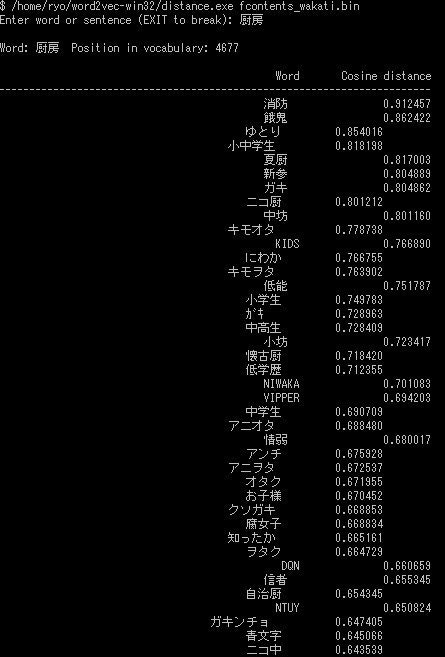
ふーむ・・・。まあ、うまくはいっているようですね。
なお、少なくともword2vecのリファレンス実装に付属しているdistanceなどのツールは、ベクトルデータを全てメモリに載せてから動作開始するようなので、メモリは3.3GBより大分多めに搭載しているマシンで実行して下さい。また、ディスクからデータを読み出すだけでも時間がかかるので、ベクトルデータはSSDなどに置いておくのが望ましいでしょう。
続いて、顔文字の類似語(類似顔文字?)を検索してみます。
まずは「(^_^)」。
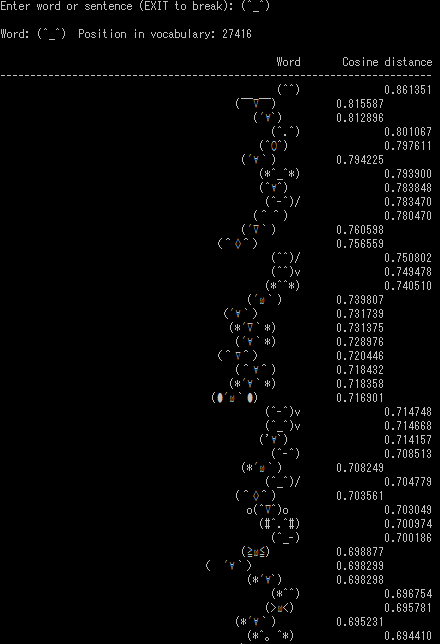
いい感じですね。
続いて「orz」。
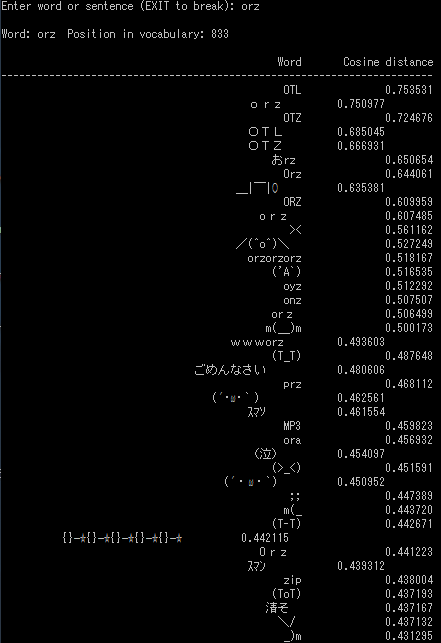
こちらもよいでしょう。
今度は難易度があがって、Bに対するAの関係と同じように、Cに対するXを探す例 (フランスに対するパリと同じ関係となるような、日本に対するXは何かというやつ)。
A=「orz」、B=「(--)」、C=「(^^)」。

うーん、これは解釈次第ですが、感情の振れ幅が大きくなっているという風に見ると期待通りの結果かな、という感じです。
最後に2つの顔文字の中間に位置するものを出してみます。
「(^_^)」と「orz」の中間を検索してみます。
これについては、word2vecにツールが附属していないので、gensimを使って簡単なコードを書いてみました。
結果はこちら。
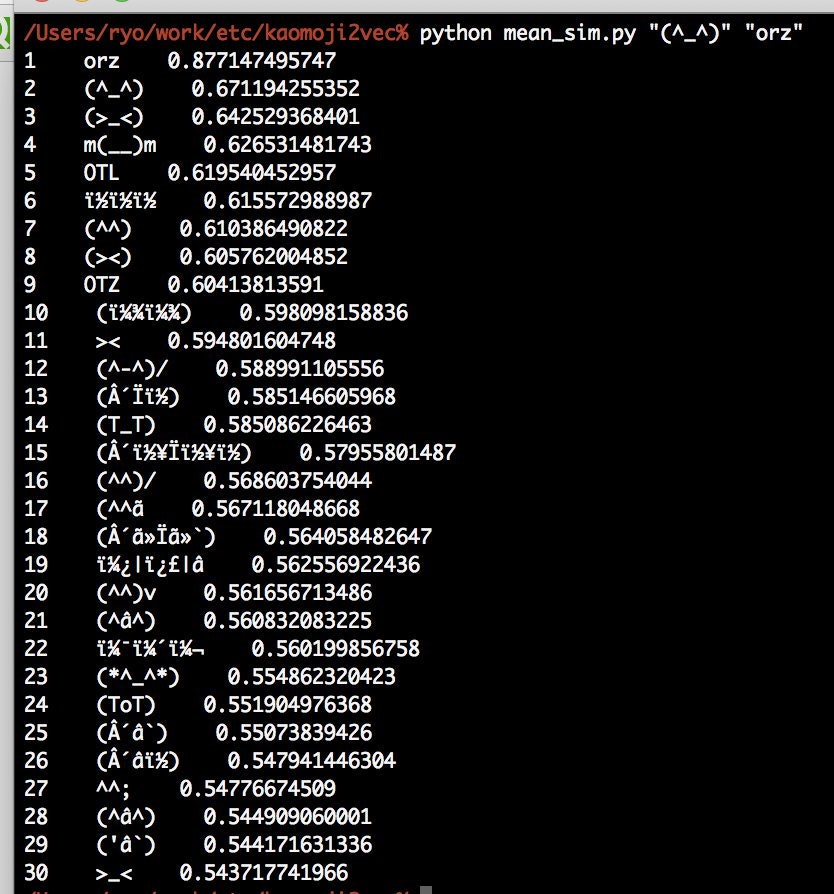
うーん。「(T_T)」あたりは期待通りの結果でしょうか。
最後に
今回試したkaomoji2vecですが、LINEなどのチャットツールで文章を打っているとその文章の表現する感情に合わせた顔文字がサジェストされる、といった応用も可能ではないかと思います。というか顔文字の入力面倒なので普通に自分が欲しいw
というような感じで、以上です。