前回分はこちら↓↓
http://qiita.com/ru_pe129/items/146d26d77c4cf1c792dc
2.3.7 Ensemble Classifiers
訓練データから複数の分類器を作成してラベルを予測することを考えてみよう。各分類器はすべて独立であるという前提条件を置くと、分類結果は個々の分類器の結果で最悪のもの以下にはなりえない。つまり、分類結果は向上するかしないかの二択になるというわけである。 分類器を組み合わせる方法の中でも二つの一般的な方法としてBaggingとBoostingが挙げられる(よくわからなかったので説明は省略…)
2.3.8 Evaluating Classifiers
RSにおいて使われているもっとも一般的な評価指標は平均誤差や平均二乗誤差である。これらの指標は意図や仮定を持たない評価指標、つまり誤差を数値的にそのまま計算しているにすぎない。
推薦を分類問題ととらえた場合には Precision や Recall などの有名な評価指標を用いることができる。これからこれらの評価指標のRSへの応用について説明していくが、ここで注意しておかなければならないことがある。 推薦システムの評価では多面的な基準が存在する ということである。正確さだけでなく、計算や分類の複雑さ、ノイズに対する強さ、スケーラビリティなど、RSの目的に応じて重視すべき評価基準は異なるのである。しかし、今回はRSのパフォーマンス(精度)のみを評価することにする。
モデルを評価するために以下の4つの言葉を使う。
・ TP: True Positive 本来あるクラスAに所属すべきものがクラスAに分類された場合
・ TN: True Negative 本来あるクラスAに所属すべきでないものがクラスAに分類されなかった場合
・ FP: False Positive 本来あるクラスAに所属すべきでないものがクラスAに分類された場合
・ FN: False Negative 本来あるクラスAに所属すべきものがクラスAに分類されなかった場合
精度は一般的に以下の式で表すことができる。
Accuracy = \frac{TP+TN}{TP+TN+FP+FN}
しかし、この表現は誤解を招く場合が多い。たとえば、2クラス分類でクラスAとクラスBのサンプルがそれぞれ99900個と100個であったとする。もしすべてのサンプルについてクラスAであると判断した場合はAccuracyは99.9%となる。しかし、クラスBのサンプルを1つも認識できていないため、精度が良いとは決して言えない。
一つの改善方法として、誤った場合のコストを考慮する方法がある(分類を誤った場合にどれだけ大変なことになるか考える)。飛行機の部品で良品が99900個、不良品が100個ある場合を考えてみよう。この場合、良品を不良品として間違った場合は全体に与える影響は無視できるが、不良品を良品と誤って判断した場合は大変なことになる。
他の方法としては、特に情報検索の分野で用いられているPrecisionとRecallがある。それぞれの定義は以下のとおりである。
Precision = \frac{TP}{TP+FP}
Recall = \frac{TP}{TP+FN}
PrecisionはあるクラスAに分類したサンプルのうち、正しくクラスAに分類されたサンプルの割合を示す。RecallはあるクラスAに分類されるべきサンプルのうち、クラスAにきちんと分類されたサンプルの割合を示している。ここで気を付けなければならないのが、いずれの指標も分類方法によってはうまく精度を表せないことがあるということである。Precisionの場合、クラスAに属するサンプルをサンプリングできていなかった場合は適切に評価することができない。Recallについても同様である。実際にはPrecisionとRecallを組み合わせた指標としてF値が存在し、以下の式で定義される
F_{1} = \frac{2RP}{R+P}=\frac{2TP}{2TP+FN+FP}
時に分類器のパフォーマンスを推定するよりもそれぞれを比較したい場合がある。このような場合、ノイズ信号の分析のために開発されたReceiver Operating Characteristic(ROC) Curveという手法を用いることができる。ROC曲線の例を以下に示す。ROC曲線は正解と誤りの関係を示すものである。
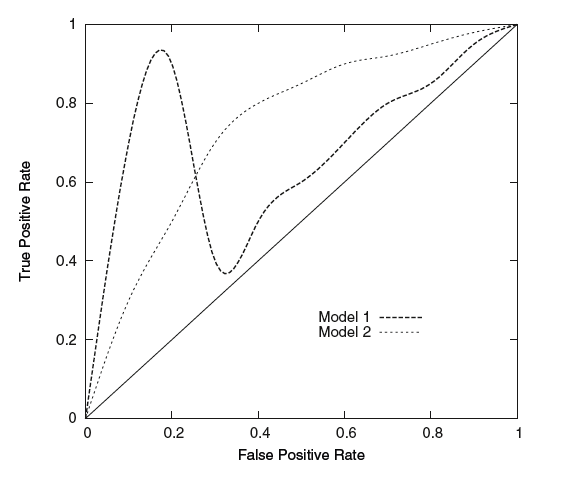
ROC曲線はRSの評価にも用いられている。
評価指標の選び方は現在も議論されているテーマである。8章では本節で取り扱った評価指標のいくつかをさらに詳しく述べている。
少し短いですが、ちょうど2.3が終わったのでこれで終わりにします。
次回はk-meansについて取り扱う予定です。
ちょっと図が大きすぎますかね…次回以降気を付けます。