HashiCorp tools を支える技術
このエントリは HashiCorp Advent Calendar の 16 日目の記事です。
HashiCorp
HashiCorp といえば、Vagrant から始まり、
Packer, Serf, Consul, Terraform, Vault, Nomad, Otto など、
運用面で有用なツールを数多く公開していることで有名です。
これらのそれぞれのツールは、
サービスを運用する立場の目線からの知見が大量に入っているのに加え、
堅牢性や様々な機能、現実的な処理速度を実現するために、
数多くの学術的な知見が組み込まれています。
本稿では、各ツールに使用されている技術の非常に簡単な概要と、
それぞれの論文へのリファレンスを示します。
HashiCorp tools
Serf
Serf では、SWIM という Gossip(epidemic) protocol の一種が、
クラスタのメンバ管理や、
クラスタメンバの故障検出に使用されています。
(SWIM: Scalable Weakly-consistent Infection-style process group Membership protocol)
SWIM / Gossip protocol
SWIM に関する論文は下記の URL にて閲覧できます。
Gossip protocol は、ノード間で情報共有を行う際に用いられるプロトコルの一種であり、
あるノードが、ネットワーク上の全てのノードにメッセージを送信するものではなく、
ネットワーク上の通信可能なノードに対して、
一定確率でメッセージを送信する事を繰り返すことで、
ノード間での情報共有を行うものです。
SWIM は、Gossip Protocol の一種であり、
具体的には次のようにしてノードの故障を検出します。
(論文の Figure 1. を抜粋)
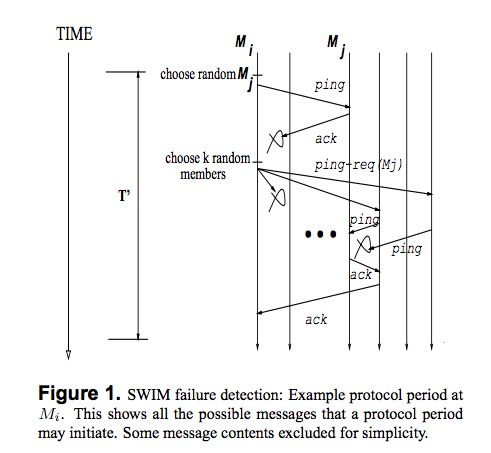
それぞれのノード $M$ はクラスタメンバのリストを保持しており、
次のような処理を行います。
- 決められた時間 $T$ 毎にメンバ内の他のランダムなノードの死活監視を行う(
ping)- 応答(
ack)があれば何もせずまた時間 $T$ が経過するのを待つ
- 応答(
上記の死活監視の際に応答が無かった場合は次のような処理が行われます。
例えば、ノード $M_i$ から ノード $M_j$ の応答が無かった場合には次のようになります。
- $M_i$ はランダムな $k$ 個のノードを選択する
- 選択したノードに $M_j$ の死活監視を行うように要請する(
ping-req)
- 選択したノードに $M_j$ の死活監視を行うように要請する(
- 選択されたノードは $M_j$ の死活監視を行う
- $M_j$ から応答があった場合その応答を要請元の $M_i$ へ転送する
このようにすることで、故障判断の偽陽性を下げたり、
ネットワーク内のメッセージによるトラフィックを下げたりしています。
実際に HashiCorp にて SWIM を Golang で実装したものが、
次のリポジトリとなります。
memberlist は、論文の SWIM に更なる修正を加えており、
クラスタの素早い収束や、高いデータ伝搬速度を得られるような機能が備わっているようです。
Consul
Consul では Raft Consensus Algorithm という合意分散アルゴリズムが、
Consul サーバのデータの一貫性を保持するために使用されています。
0.6 以降では Vivaldi という分散ネットワーク座標系をベースとしたアルゴリズムが、
ノード間の RTT の計算や最も近いノードを計算するなどの用途で使用されています。
また、Serf 同様、メンバ管理や故障検出には SWIM も使用されています。
Raft Consensus Algorithm
Raft に関する論文は下記の URL にて閲覧できます。
Raft Consensus Algorithm は、
Consul 以外にも、InfluxDBや、
CoreOS の提供している etcd でも使用されている、
分散合意アルゴリズムです。
Raft では、各ノードは次のいずれかのステータスを持ちます。
- Leader
- Leader になった瞬間にクラスタの全てのメンバに対して通知を行う
- クラスタの全てのメンバに対して一定時間毎に heartbeat を発行する
- Follower
- Leader の居るクラスタに所属している状態
- Leader からの heartbeat を一定の時間内のランダムな時間待つ
- 例えば 100ms 〜 500ms の間でランダムな時間待つ、など
- heartbeat が時間内に来なかった場合 Candidate のステータスに移行する
- Candidate
- クラスタ内の他のノードに投票を要請する
- Candidate は Candidate 自身に投票を行う
- クラスタ内の定足数以上の投票を受け取った場合 Leader のステータスに移行する
- 他の Leader が選出された通知を受け取った場合には Follower のステータスに移行する
- クラスタ内の他のノードに投票を要請する
例えば、初期状態からの最も簡単なクラスタ形成は次のようなフローで行われます。
- 全てのノードは Follower 状態からスタートする
- 最初 Leader はクラスタ内に存在しない
- ノード毎にランダムな時間待つ
- タイムアウトになったノードが Candidate となる
- クラスタ内の他のノードに投票を要請する
- 投票要請を受け取ったノードは当該の Candidate に投票を行う
- 定足数を超えた投票を受け取った Candidate ノードは Leader のステータスへ移行する
次の gif が最も分かりやすいと思います。
gif の例ではノード S4 が最初にタイムアウトを迎え、
Candidate を経て Leader となっています。

( http://raft.github.io/ より抜粋)
また、上記のステータス以外にも term という、
リーダの世代によって管理・インクリメントされる値を持ち、
これにより、1 つのクラスタが分割・統合された際にも、
クラスタ形成を行えるようになっています。
実際に HashiCorp にて Raft を Golang で実装したものが、
次のリポジトリとなります。
InfluxDB も 2015/12/17 現在では、上記の hashicorp/raft を使用しているようです。
etcd は、etcd 側で実装したものを使用しているようです。
先ほど紹介した http://raft.github.io/ のサイトで、
様々なシミュレーションを行うと理解が深まるかと思います。
各ノードは右クリックで stop/resume を行う事が出来ます。
例えば最初から 2 つのノードだけでクラスタを形成しようとすると、
一向に Leader が選出されないことが分かるかと思います。
Consul server が 3 台以上必要な理由や、
bootstrap-expect 等のオプションが存在する理由も、
この辺りにあるでしょう。
Vivaldi
Vivaldi に関する論文は下記の URL にて閲覧できます。
Vivaldi に関しては、実装が最近だったこともあり、
現在論文を読んでいる最中です。
ざっくりとした事は分かったのですが、ちょっと怪しいので、
読者の皆さんで読んで、ぜひどこかで発表して貰えればと思います。
実装としては恐らくこの辺りになるでしょうか?
Vault
Vault ではマスターキーの管理に Shamir's Secret Sharing という、
秘密データの分散管理法が使用されています。
Shamir's Secret Sharing
- Shamir's Secret Sharing に関する論文は下記の URL にて閲覧できます。
シャミアの秘密分散法は、その名の通り秘密データを複数に分割して保存する方法です。
秘密データをいくつに分散するか、
そのうちのいくつが存在していたら復元可能にするか、などを選択することが出来ます。
大変わかり易い日本語の説明が下記にあるので、こちらを参照すると良いと思います。
中学・高校レベルの多項式の知識があれば全貌が理解できるかと思います。
Nomad
Nomad では、クラスタのスケジューリングに、
Google の発表している Borg/Omega や、
バークレー大学の発表している Sparrow をベースとしたものを使用しているそうです。
それぞれ、論文は次の URL にて閲覧できます。
Borg
Omega
Sparrow
それぞれ、Nomad の Scheduler Types に対応しており、
Service のスケジューラタイプでは Borg ベースのものが使用され、
Batch のスケジューラタイプでは Sparrow ベースのものが使用されるようです。
Borg/Omega/Sparrow に関しては、
私自身がそんなに論文を読み込めていない上に理解も怪しいので、
読者の皆さんで読んで、ぜひどこかで発表して貰えればと思います。
まとめ
Hasihcorp の便利なツール群の内部では、
様々な学術的な研究の知見が使われていることについて書き、
一部の知見については、概要についても書きました。
改めて眺めてみると、Paxos や PIC ではなく、
Raft や Vivaldi を選択している辺りから、
実際に実装しやすいものや、多少の誤差を許しながらも専用のトラフィックを持たないものなど、
運用や書きやすさに考慮してこれらの研究を選択しているように見えるのも少し印象的でした。
HashiCorp のツール以外にも、普段運用しているツールで、
このように学術的な知見が生きているものが多くあると思います。
今回のように深入りして学ぶことで、ツール自体への理解も深まり、
同じような基盤技術を使用している他のプロダクトへも馴染みやすくなりました。
また、理解や内容には恐らく誤りがありますが、
修正しますのでぜひ指摘して貰えればと思います。