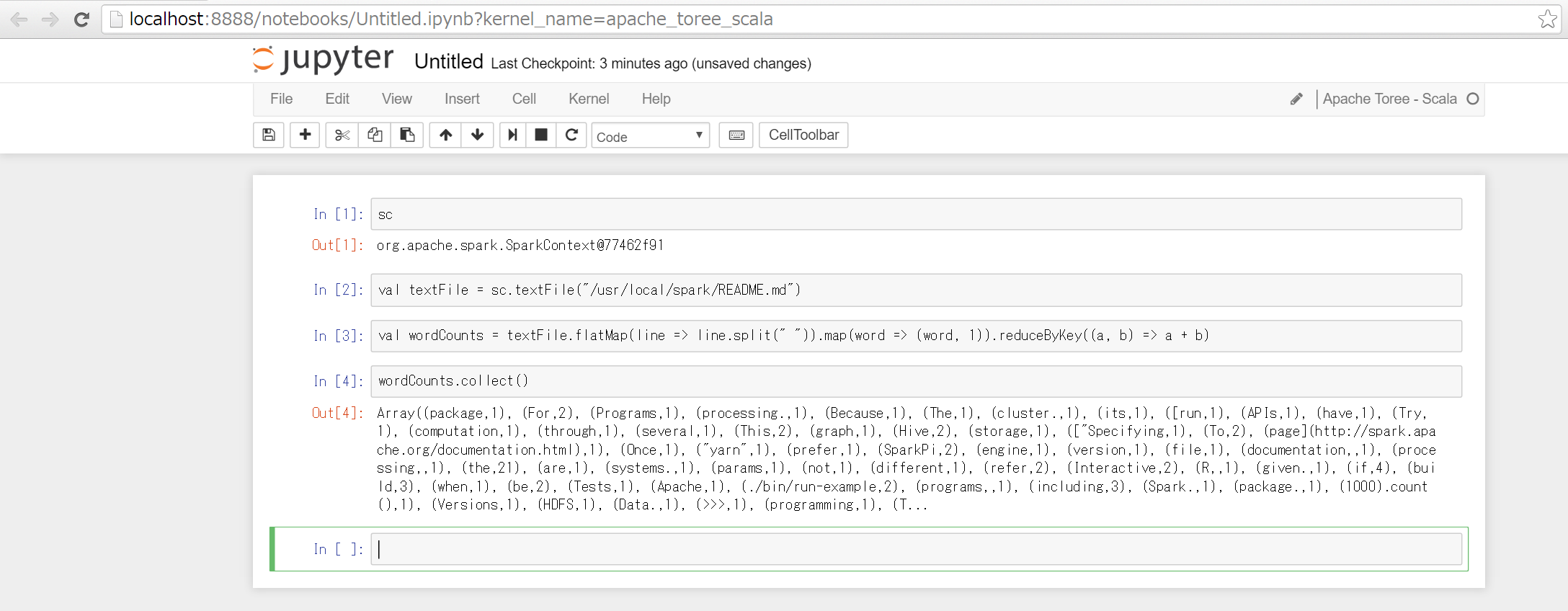
機械学習で実験した結果を残すときなどは Jupyter Notebook が便利。
MLlibを使った検証を Jupyter Notebook で残せるようにする。
Ubuntu で動作検証しているが他のOSでもいけるはず。
1. Python環境構築 (jupyter, pip)
以下の記事を参考に Anaconda を入れるのが楽
2. Spark のインストール
3. Apache Toree (Spark kernel) のインストール
$ pip install --pre toree
$ sudo jupyter toree install
SPARK_HOME を設定していない場合は $ sudo jupyter toree install --spark_home=/spark/home/dir で指定する。
インストール後 $HOME/.local のオーナーが root になっている場合は $USER に変更する。
起動
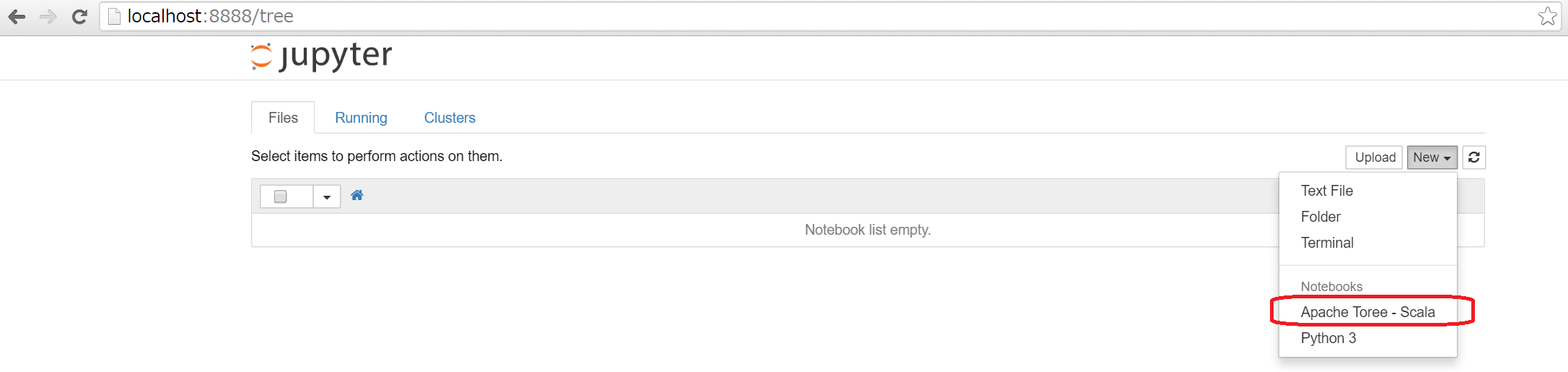
$ jupyter notebook で起動すると下図のように [Apache Toree - Scala] が追加されている
カーネルを選択したあとしばらく起動を待つ必要があるが下図のように Jupyter 上で Spark を実行できる