rvest パッケージを使ってWEBから文字列を取得し、これをデータフレームにして RMeCab の doDF() で解析する。
前提
MeCab がインストールされた環境。OSXでのMeCabのインストールについては https://sites.google.com/site/rmecab/home/install を参照。
さら R がインストールされており、追加で以下のパッケージが導入されている。
install.packages(c("dplyr", "rvest", "wordcloud", "igraph"), depend = TRUE)
install.packages("RMeCab", repos = "http://rmecab.jp/R")
igraphの tkplot() をOSXで利用するには XQuartz が必要となる。
スクレイピング
まずスクレイピングでテキスト部分を抽出する。
テキスト部分を html_nodes() でピンポイントに指定するには、その部分を特定するCSSセレクタを知る必要があるが、これはブラウザで該当箇所を右クリック、検証ツールからコピペする。
library(rvest)
library(dplyr)
x <- read_html("http://anond.hatelabo.jp/20170429110724")
texts <- x %>% html_nodes(css = "#body > div.day > div.body > div > p:nth-child(3)") %>% html_text()
形態素解析
抽出したテキストをいったんデータフレームに変換し、これを形態素解析にかけて頻度表を作成する。
if(.Platform$OS.type == "windows") texts <- iconv(texts, from = "UTF-8")
textDF <- data.frame(X = texts, stringsAsFactors = FALSE)
library(RMeCab)
textDF2 <- docDF(textDF, pos = c("名詞", "動詞", "形容詞"), column = 1, type = 1)
解析結果
> head(textDF2)
TERM POS1 POS2 Row1
1 3 名詞 数 5
2 4 名詞 数 3
3 あがる 動詞 自立 1
4 あまり 名詞 接尾 1
5 ありがたい 形容詞 自立 1
6 ある 動詞 非自立 2
> tail(textDF2)
TERM POS1 POS2 Row1
235 様 名詞 接尾 2
236 様子 名詞 一般 1
237 来る 動詞 自立 2
238 立つ 動詞 自立 1
239 歴史 名詞 一般 1
240 饒舌 名詞 形容動詞語幹 1
ワードクラウドを作成
library(wordcloud)
pal <- brewer.pal(8,"Dark2")
wordcloud(textDF2$TERM, textDF2$Row1, colors = pal, min.freq = 2, family = "JP1")

(形態素レベルの)バイグラムを作成
textDF3 <- docDF(textDF, pos = c("名詞", "動詞", "形容詞"), column = 1, type = 1, N = 2, nDF = TRUE)
出力
> head(textDF3)
N1 N2 POS1 POS2 Row1
1 あがる ライン 動詞-名詞 自立-一般 1
2 あまり 記憶 名詞-名詞 接尾-サ変接続 1
3 ありがたい さ 形容詞-名詞 自立-接尾 1
4 ある すべて 動詞-名詞 非自立-副詞可能 1
5 ある 写真 動詞-名詞 非自立-一般 1
6 あれ 顔 名詞-名詞 代名詞-一般 1
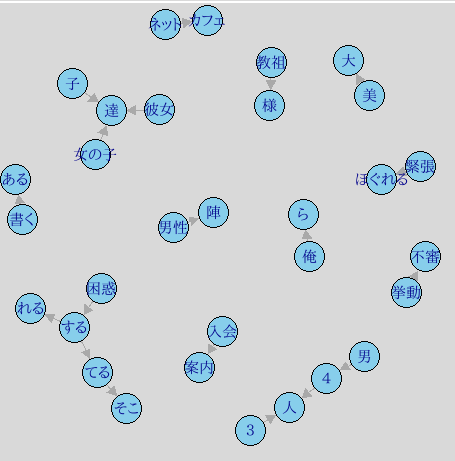
ネットワークグラフを作成
library(igraph)
netDF <- textDF3 %>% select(N1, N2, Row1) %>% filter(Row1 > 1) %>% graph_from_data_frame()
tkplot(netDF, vertex.color = "SkyBlue")