最近クローラーを作成する機会が多く、その時にXPathが改めて便利だと思ったので
XPathについてまとめてみました!
XPathを学ぶ方の役に立てれば幸いです。
初級編
XPathとは
XPathはXML文章中の要素、属性値などを指定するための言語です。
XPathではXML文章をツリーとして捉えることで、要素や属性の位置を指定することができます。
HTMLもXMLの一種とみなすことができるため、XPathを使ってHTML文章中の要素を指定することができます。
例えば、
<html>
...
<body>
<h1>ワンピース</h1>
<div class="item">
<span class="brand">iQON</span>
<span class="regular_price">1,200円</span>
<span class="sale_price">1,000円</span>
</div>
</body>
</html>
このようなHTMLの場合であれば、ざっくりと下記のようなツリー構造に表すことができます。
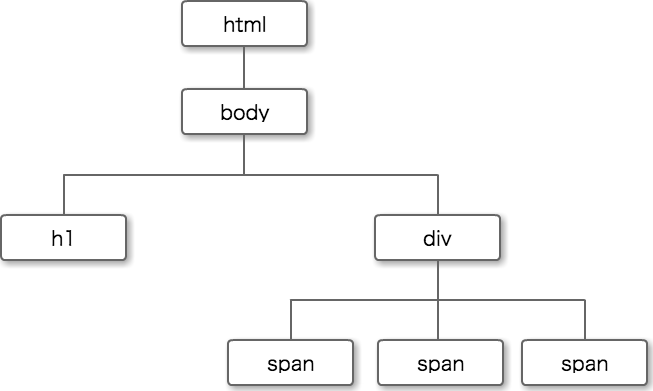
XPathはこのようなツリー構造から要素を取得します。
XPathの基礎
ロケーションパス
XPathは、ロケーションパスによって表されます。
ロケーションパスとは、ツリー構造から特定の要素を指定するための式のことです。
ロケーションパスは、URLのように『/』で要素を繋げて書きます。
<html>
...
<body>
<h1>ワンピース</h1>
<div class="item">
<span class="brand">iQON</span>
<span class="regular_price">1,200円</span>
<span class="sale_price">1,000円</span>
</div>
</body>
</html>
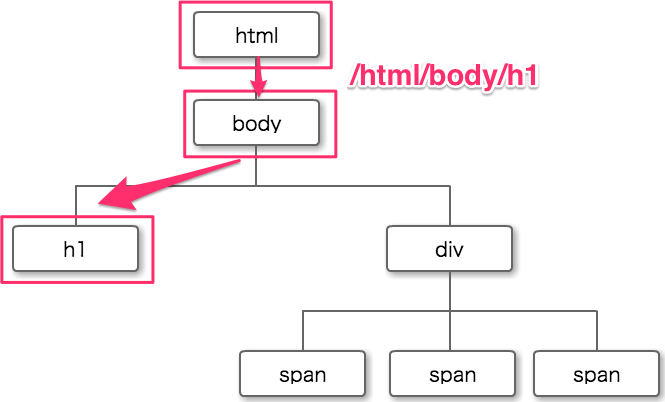
このHTMLにおいて『h1要素』を取得するXPathは、
ツリー構造の上から順に『html要素→body要素→h1要素』と指定します。
ロケーションパスで表すと、
/html/body/h1
このようなXPathになります。
中級編
属性について
classのような要素に紐づく属性をXPathでは『@』で表します。
『1,200円』という要素を取得したい場合は、属性を用い下記のように書くことができます。
/html/body/div/span[@class='regular_price']
//を用いて途中までのパスを省略
/html/body/div/span[@class='regular_price']
このXpathを『//』を用いて、ノードパスを省略することができます。
『//』は、descendant-or-selfの省略形です。
すなわち起点となるノードの子孫すべての集合を表します。
例えば、
/html/body/div/span[@class='regular_price']
このXPathを『//』を用いて省略すると、下記のように書くことができます。
//span[@class='regular_price']
指定する文字列が含まれている要素を取得する: contains
containsは、指定する文字列が含まれている要素を取得します。
<img class="large_image">
<img class="small_image">
<img class="thumbnail">
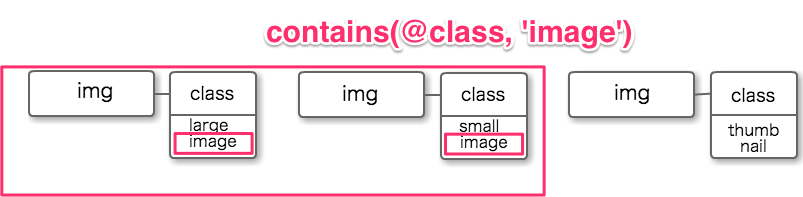
上記のHTMLからclassにimageがつくものをすべて取得したい場合、『contains』を用いることができます。
contains関数は、第1引数文字列内に、第2引数文字列が含まれているかどうかを調べる関数です。
classにimageがつく要素すべて取得する、という条件をcontainsを用いて表すと下記のような書き方になります。
//img[contains(@class, 'image')]
このXPathは、classにimageを含むimg要素を取得するという意味になります。
またテキスト中に含まれている文字を指定したい場合には、text()とcontainsを組み合わせます。
<div class="item">
<h1>ワンピース</h1>
<div class="price">1,200円</div>
<div class="description">
冬に最適なニットワンピースです。
品番:100000000
</div>
</div>
</div>
このHTMLから『品番』という文字を含んでいる要素を指定したい場合は、
//div[contains(text(), '品番')]
と書くことができます。
さらに、『指定する文字を含むJavaScript』を取得する場合は、下記のように書くことができます。
//script[contains(text(), 'stock')]
要素の位置を指定: position
要素の位置を指定したい場合はpositionを使用します。
positionは、指定したノードから何番目のノードかを指定することができます。
<ul>
<li>色を選択</li>
<li>ホワイト</li>
<li>レッド</li>
<li>ブルー</li>
</ul>
このHTMLでposition()を使ってみます。
position() =
上記のHTMLで『レッド』はli要素の3番目のなのでpositionを用いて
//li[position()=3]
と表すことができます。
またposition()=3を省略し
//li[3]
と書くこともできます。
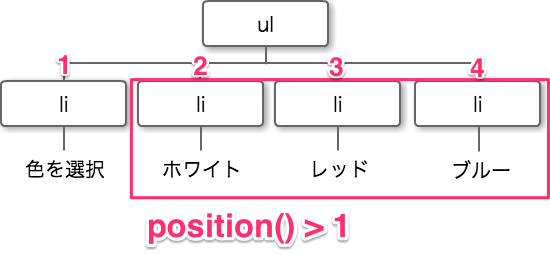
position() >
『色を選択』以外のli要素を取得する場合はpositionを用いて下記のように表すことができます。
//li[position()>1]
『色を選択』はli要素の1番目であるため、position()>1は、『色を選択』以外のli要素を指定します。
テキストノードの取得
要素内のテキストを取得したい場合は、『text()』というテキストノードを用います。
<p>Sサイズ <span>レッド</span></p>
このHTMLから『Sサイズ』という文字列のみを取得したい場合は、text()を用いて
//p/text()
と書くことができます。
not
notは述部にて否定を表します。
<img src="http://sample.ne.jp/sample_main_image.jpg">
<img src="http://sample.ne.jp/sample_sub_image.jpg">
<img src="http://sample.ne.jp/sample_thumbnail.jpg">
このHTMLからhttp://sample.ne.jp/sample_main_image.jpg以外の
@srcを取得したい場合はnotを用いて
//img[not(contains(@src, 'main'))]/@src
と書くことができます。
or
or条件をXPathで使うことができます。
<img src="http://sample.ne.jp/sample_100.jpg">
<img src="http://sample.ne.jp/sample_200.jpg">
<img src="http://sample.ne.jp/sample_300.jpg">
<img src="http://sample.ne.jp/sample_400.jpg">
<img src="http://sample.ne.jp/sample_500.jpg">
<img src="http://sample.ne.jp/sample_600.jpg">
このHTMLから、100か300を含むsrcを取得したい場合は、orを用いて下記のように書くことができます。
//td[contains(@src,'100') or contains(@src, '300')]
また、100か300以外のsrcを取得したい場合は、notとorを組み合わせます。
//td[not(contains(@src,'100') or contains(@src, '300'))]
and
and条件も、XPathで使うことができます。
<img src="http://sample.ne.jp/main_100.jpg">
<img src="http://sample.ne.jp/main_300.jpg">
<img src="http://sample.ne.jp/sub_100.jpg">
<img src="http://sample.ne.jp/sub_300.jpg">
<img src="http://sample.ne.jp/thumbnail_100.jpg">
<img src="http://sample.ne.jp/thumbnail_300.jpg">
このHTMLから、『main』と『300』を含むsrcを取得したい場合は、 andを使って下記のように書くことができます。
//img[contains(@src, 'main') and contains(@src, '300')]
上級編
軸・ノードテスト・述部
ロケーションパス内で要素を表現する際、『軸・ノードテスト・述部』と呼ばれるものを用いて表現します。
| 名前 | 説明 |
|---|---|
| 軸 | ツリー上の位置関係を指定する |
| ノードテスト | 選択するノードの型と名前を指定する |
| 述部 | 選択するノードの集合を、任意の式を使用してさらに細かく指定する |
/html/body/h1
というXPathはノードテストのみで要素を表していました。
ノードテストだけでは欲しい要素を取得できない場合は、軸や述部を使用することで細かく要素を指定することができます。
述部について
ツリー図に、classなどの属性の情報を加えたものが下記の図になります。
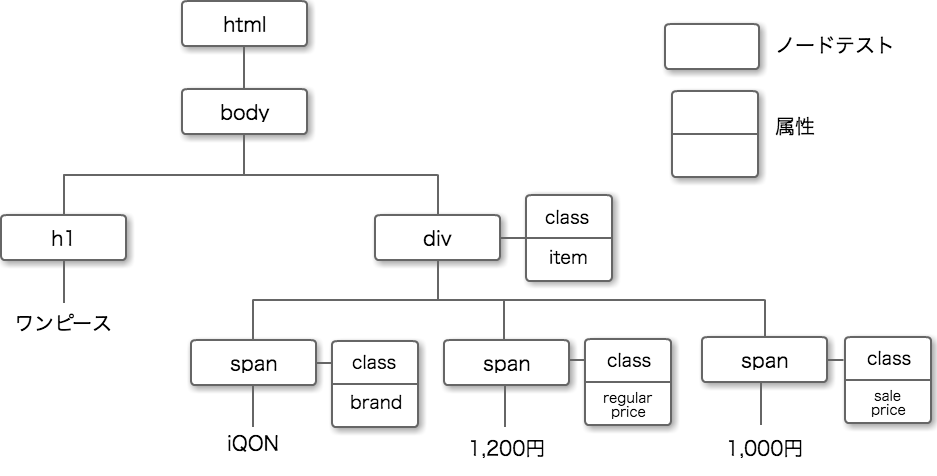
軸
軸は、ツリー上の位置関係を指定するものです。
軸の代表的なものとして、以下のような種類があります。
| 名前 | 説明 |
|---|---|
| self | ノード自身を表す |
| child | ノードの子ノードの集合 |
| parent | ノードの親ノードの集合 |
| ancestor | ノードから祖先ノードの集合(親も含む) |
| descendant | ノードから子孫ノード集合 |
| following | ノードの後に出てくるノードの集合 |
| preceding | ノードの前に出てくるノードの集合 |
| following-sibling | ノードと同じ階層にあり、かつ後に出てくる兄弟ノードの集合 |
| preceding-sibling | ノードと同じ階層にあり、かつ前に出てくる兄弟ノードの集合 |
軸を先ほどまでの図に加えてみます。
どこを起点として考えるかによって位置関係は変わりますが、今回は『div』を中心に軸を考えます。
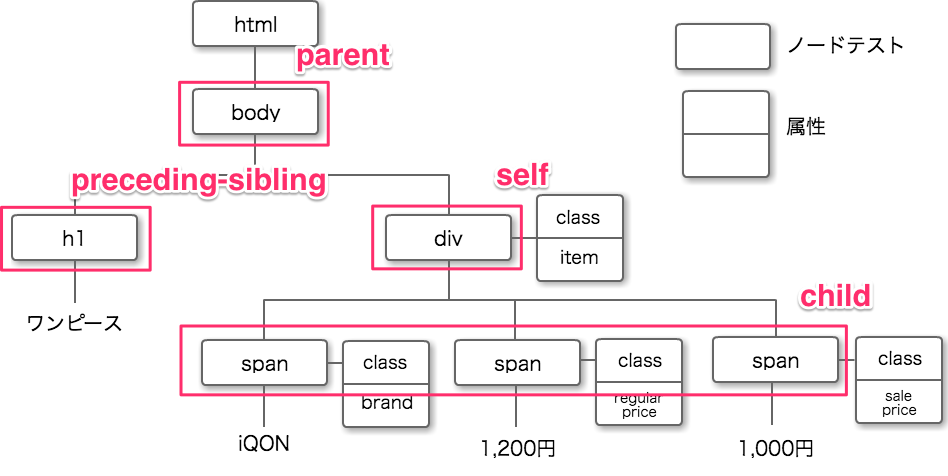
今回はdivを中心に考えるため、div自身は起点となるノードつまり『self』になります。
bodyは、divから見て一つ上の階層つまり親となるので『parent』、 3つのspanは、一つ下の階層つまり子となるので『child』となります。
また、h1要素は、divと同じ階層かつdivより前に出現するので、軸は『preceding-sibling』となります。
childの省略について
明示的に軸を指定しない場合は、軸がchildとみなされます。
そのため基本的にchildは省略することができます。
//を用いて途中までのパスを省略
『//』は、descendant-or-selfの省略形です。
すなわち起点となるノードの子孫すべての集合を表します。
この『//』を用いて、パスを省略することができます。
例えば、
/html/body/div/span[@class='regular_price']
このXPathを『//』を用いて省略すると、下記のように書くことができます。
//span[@class='regular_price']
軸::ノードテスト[述語]
軸・ノードテスト・述部を用いてXPathを書く場合、『軸::ノードテスト[述部]』という書き方で要素を指定します。
<html>
...
<body>
<h1>ワンピース</h1>
<div class="item">
<span class="brand">iQON</span>
<span class="regular_price">1,200円</span>
<span class="sale_price">1,000円</span>
</div>
</body>
</html>
このHTMLから『1,200円』の要素を取り出すXPathは下記のように書くことができます。
/html/body/div/span[@class='regular_price']/self::text()
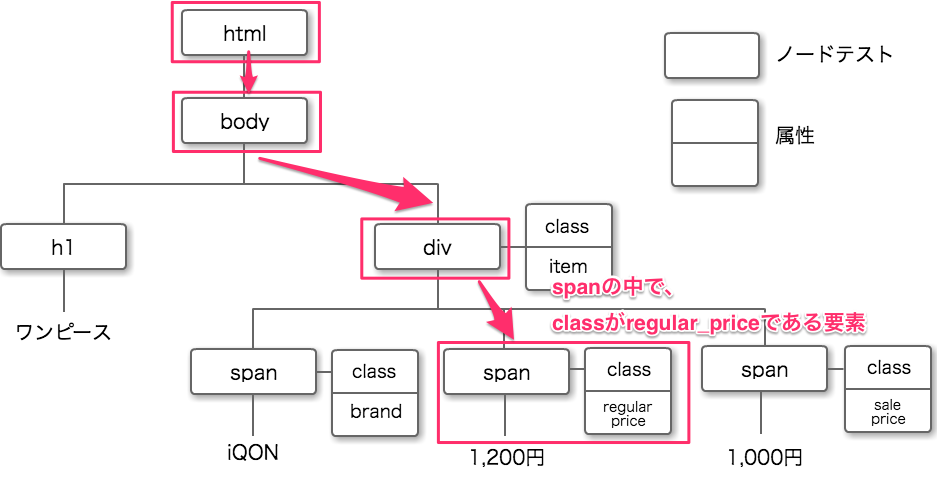
また、省略した形で書くと、こうなります。
//span[@class='regular_price']
ここまでざっくりと軸・ノードテスト・述部を説明しました。
軸・ノードテスト・述部についてもっと詳しく知りたい方は、下記のページがすごくわかりやすいのでぜひ参考にしてみてください。
http://www.techscore.com/tech/XML/XPath/XPath3/xpath03.html/
指定された要素より後の兄弟要素を持ってくる: following-sibling::
軸のところで紹介しましたが『following-sibling::』は、起点となるノードと同じ階層にあり、かつ起点となるノードより『後』に出てくる兄弟ノードの集合を表す軸です。
この『following-sibling::』は、テーブル要素を指定するときに大活躍します。
<table>
<tr>
<td>生産国</td>
<td>日本</td>
</tr>
<tr>
<td>素材</td>
<td>綿</td>
</tr>
</table>
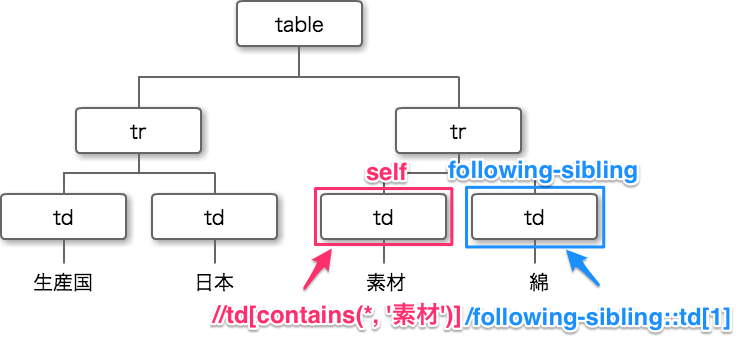
このようなテーブルが用意されている場合、『綿』をどのように取得したらよいでしょうか。
//td[4]
と書くこともできますが、td要素が増えたり減ったり変化がある場合、//td[4]の指定する要素が変わり対応できません。
そこで、『following-sibling::』を使います。
綿を取得したい場合は、
//td[contains(*, '素材')]/following-sibling::td[1]
と書くことができます。
指定された要素より前の兄弟要素を持ってくる: preceding-sibling::
『preceding-sibling::』はfollowing-sibling::の対となる軸で、起点となるノードと同じ階層にあり、かつ起点となるノードより『前』に出てくる兄弟ノードの集合を表す軸です。
こちらもテーブル要素を指定するときに大活躍します。
<table>
<tr>
<td class="title">22cm</td>
<td class="title">23cm</td>
<td class="title">24cm</td>
</tr>
<tr>
<td class="title">レッド</td>
<td class="inventory">在庫あり</td>
<td class="inventory">在庫あり</td>
</tr>
<tr>
<td class="title">ブルー</td>
<td class="inventory">在庫あり</td>
<td class="inventory">在庫なし</td>
</tr>
<tr>
<td class='title'>グリーン</td>
<td class='inventory'>在庫あり</td>
<td class='inventory'>在庫あり</td>
</tr>
</table>
上記のようなHTMLにおいて、色(レッド, ブルー, グリーン)をすべて取得したい場合、どのようなXPathで取得できるでしょうか。
単に、
//td[@class='title']
では色だけでなくサイズも取得してしまいます。
このようなときに、preceding-siblings::を用います。
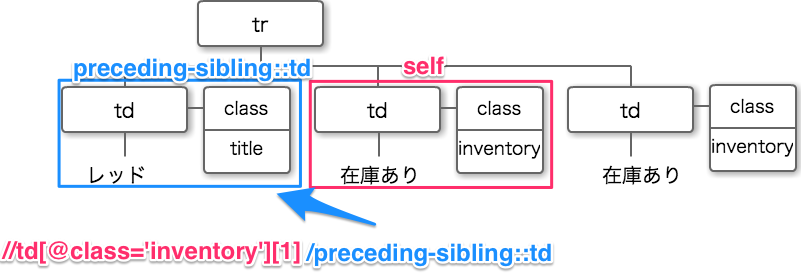
//td[@class="inventory"][1]/preceding-sibling::td
このように書くことで、class属性がinventoryのtd要素の1番目(td[@class='inventory'][1])の1つ前の要素(preceding-sibling::td)すなわち色を取得することができます。
重複なく抽出
<table>
<tr>
<td>レッド</td>
<td>レッド</td>
<td>レッド</td>
</tr>
<tr>
<td>ブルー</td>
</tr>
<tr>
<td>グリーン</td>
</tr>
</table>
このHTMLから重複なく色を取得したい場合は下記のように書けます。
//td[not(.=preceding::td)]
このXPathは、td要素の中でprecedingすなわち前に出てくる要素と一致しないものを取得しています。
XPath関連便利サービス
最後に、XPathを取得する時にオススメの拡張機能を紹介します。
『XPath Helper』です!!
XPath Helper
XPath Helperは、ブラウザから要素をカーソルに合わせるだけでXPathを調べることができる超優れたchrome拡張機能です。

下記からダウンロードができます。
https://chrome.google.com/webstore/detail/XPath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl?hl=ja
この拡張機能を使い方は、
chromeブックマークバーのxと書いてあるアイコンをクリック、またはショートカットキー[Ctrl + Shift + X]で起動します。
そして、取得したい要素をシフトを押しながら選択すると、要素のXPathが簡単に取得できます。

とても簡単にXPathが取得できるのでオススメです!
まとめ
以上が、クローラーに便利なXPathまとめでした!
XPathは比較的覚えやすく理解しやすい言語ですので、非エンジニアの方にもとてもオススメです。
ぜひXPath Helperを入れて、XPathを試してみてください!